
v10a – Supercharging Recovery Speeds from Object Storage
We always talk about starting with backup... and it is true that you can't recover unless you have a solid backup, however more and more the recovery of work...
Tag
3 posts
We always talk about starting with backup... and it is true that you can't recover unless you have a solid backup, however more and more the recovery of work...
Version 10 of Veeam Backup & Replication isn't too far away and we are currently in the middle of a second private BETA for our customers and partners. There...
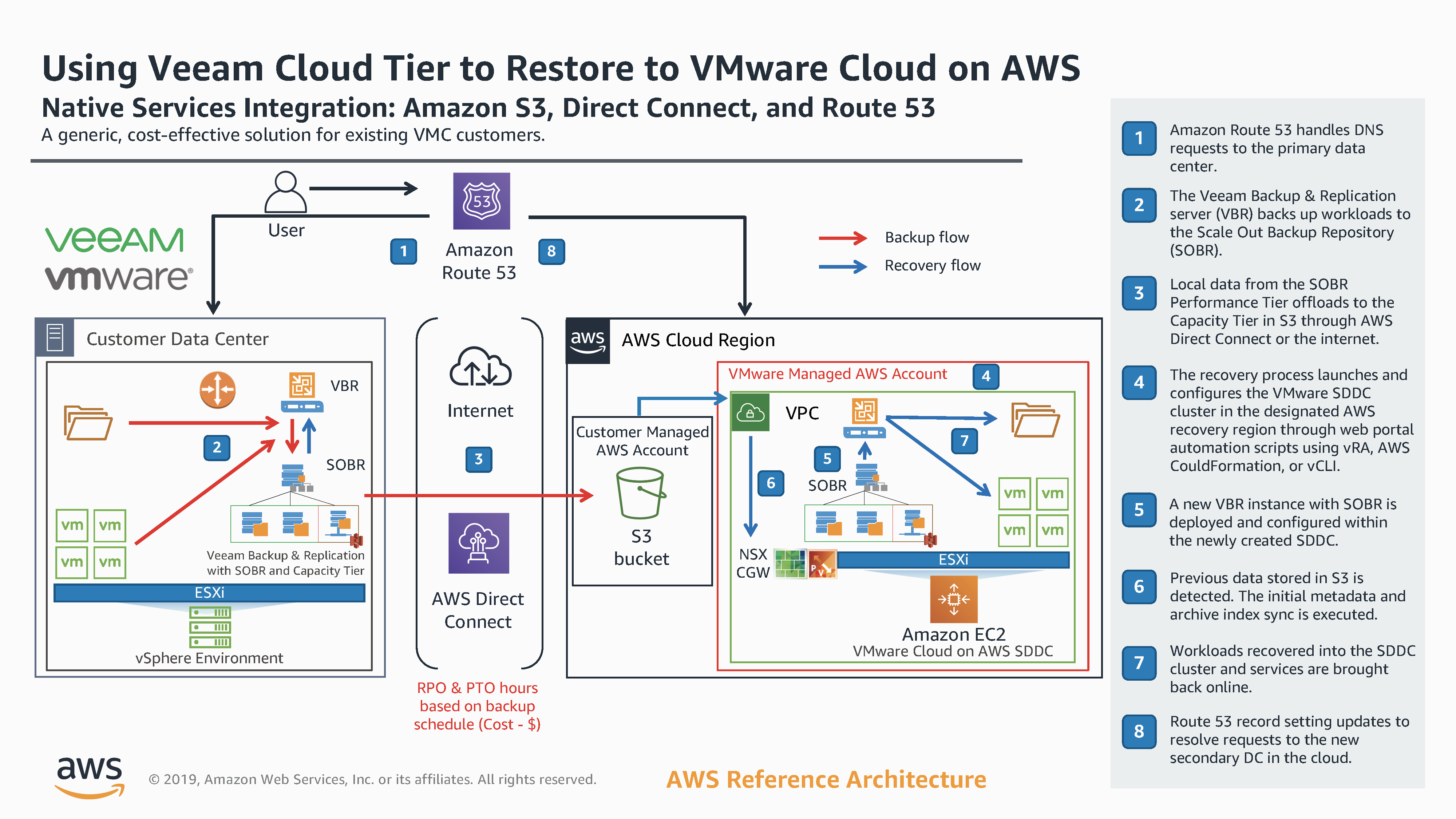
Since Veeam Cloud Tier was released as part of Backup & Replication 9.5 Update 4 , i've written a lot about how it works and what it offers in terms of offlo...