
Backup for AWS v6 and Azure v5 Released!
Over the last couple of weeks we have continued to add to our v12 Data Platform by releasing new versions of Veeam Backup for AWS v6 ( Build 6.0.0.335 ) and ...
Category
47 posts
Over the last couple of weeks we have continued to add to our v12 Data Platform by releasing new versions of Veeam Backup for AWS v6 ( Build 6.0.0.335 ) and ...

While at AWS re:Invent 2022 I had some great conversations with a mix of old and new Managed Service Providers who are focusing on delivering services for wo...
NOTE: The following content was transcribed and modified from the Thoughts on X podcast embedded above… Click Play if you would like to listen. AWS re:Invent...

NOTE: The following content was transcribed and modified from the Thoughts on X podcast embedded above... Click Play if you would like to listen. Last week, ...

Last week, I had the pleasure to sit down in a Twitter Space with Chris Williams and other AWS Community members to chat about Chris's journey from a traditi...

I remember back a few years ago when VMware first launched their Flings how useful some of them where (and still are). Seemed like no matter what area of the...
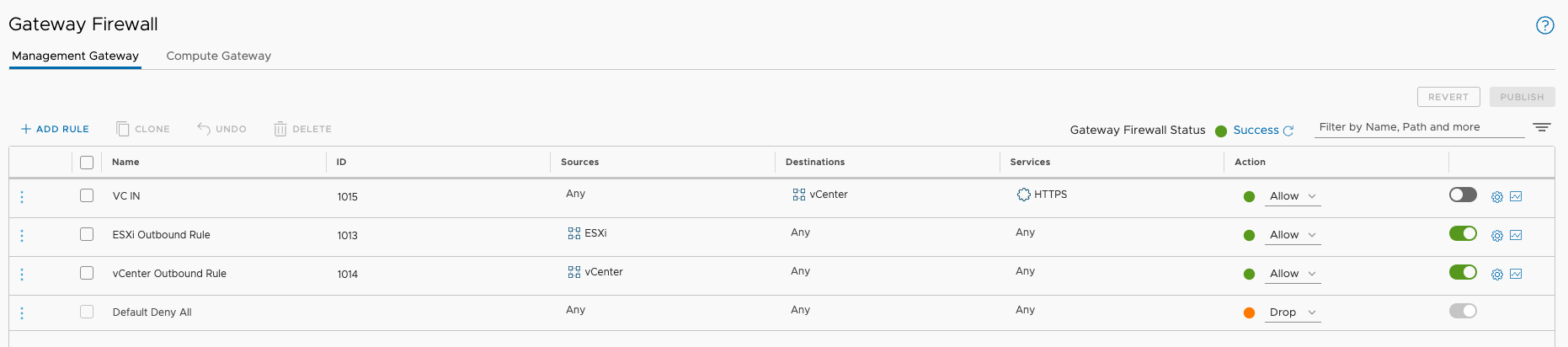
Over the past week or so, i've been diving back into working on VMware Cloud on AWS ... for the most, the experience hasn't changed that much since I started...

The releases keep coming from us here at Veeam and off the back of updated versions Veeam Backup & Replication (v11a) , Veeam One (v11a) and Veeam Service Pr...

I've been looking for alternative Wordpress blogging options for a while and the one that keeps on coming up is Ghost . Now, Ghost has been around for a long...

When Veeam Backup & Replication v11 went Generally Available on the 24th of February I posted the What’s in it for Service Providers blog. In that post I bri...
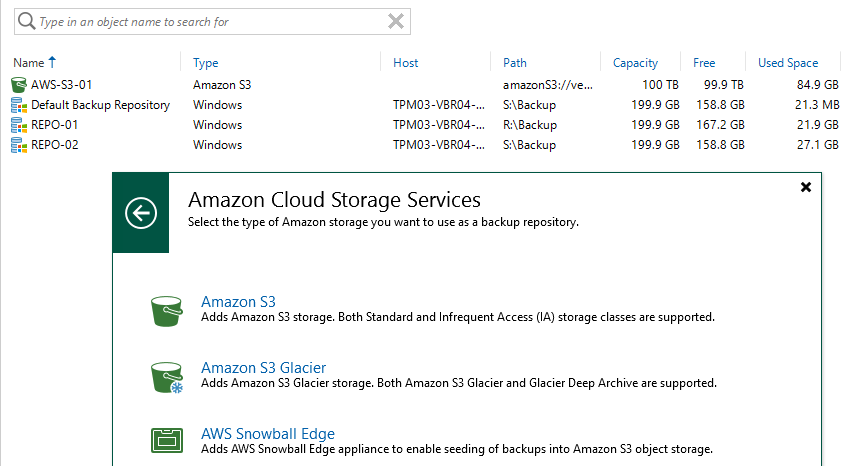
Since version 9.5 Update 4 of Veeam Backup & Replication we have had support to firstly move, then copy ( as part of v10 ) backup data from what is, traditio...

We always talk about starting with backup... and it is true that you can't recover unless you have a solid backup, however more and more the recovery of work...
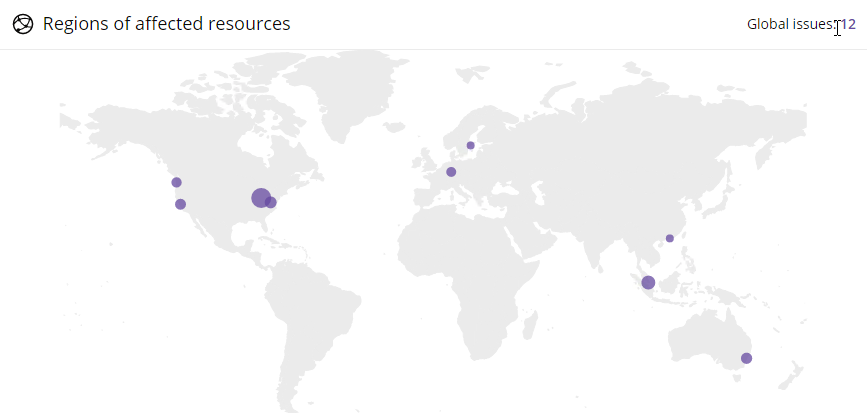
Back when I first started using AWS in 2010 I had a couple of EC2 instances running across a few regions for some web hosting clients I was managing at the t...
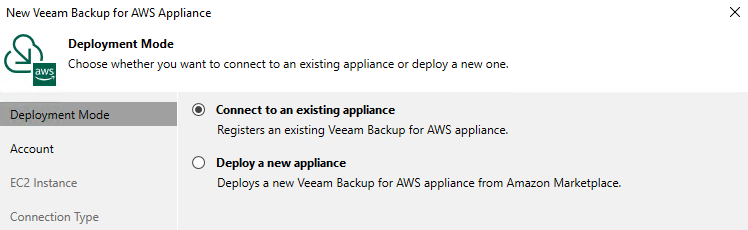
As mentioned my post yesterday, Veeam Backup & replication v10a has been released . One of the more significant new features of the release was the new AWS P...
In todays application centric world, upgrading software has almost become a non-event. We have gotten used to instant upgrades that just work without having ...
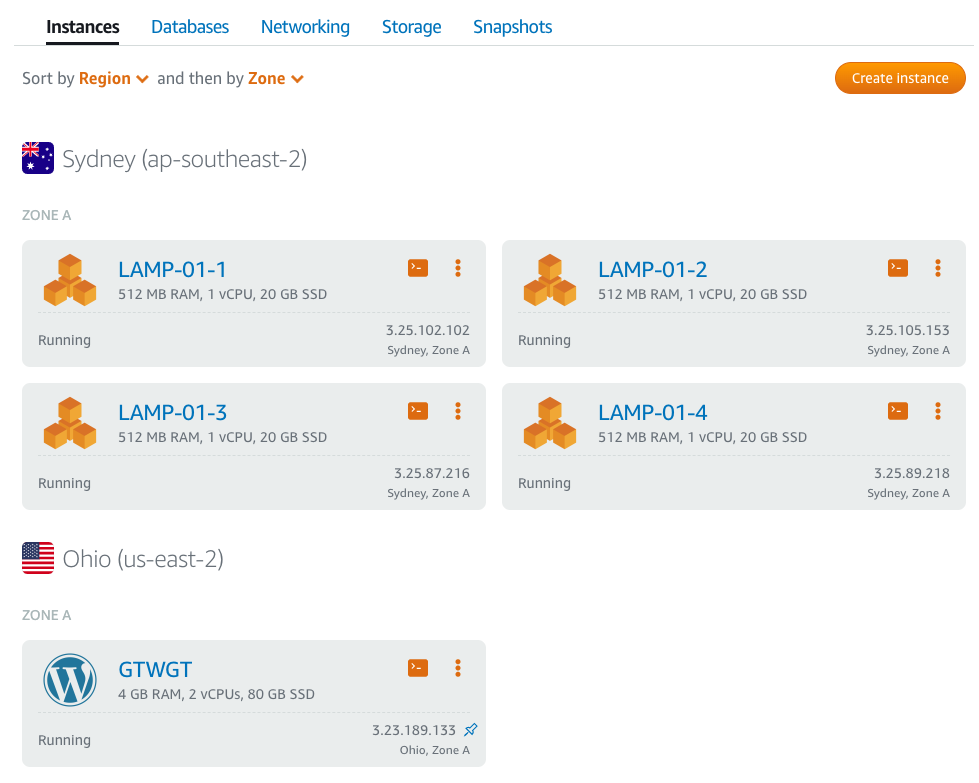
I've written before about how AWS offers complex simplicity when it comes to its plethora of service offerings. Without some education, the average user isn'...
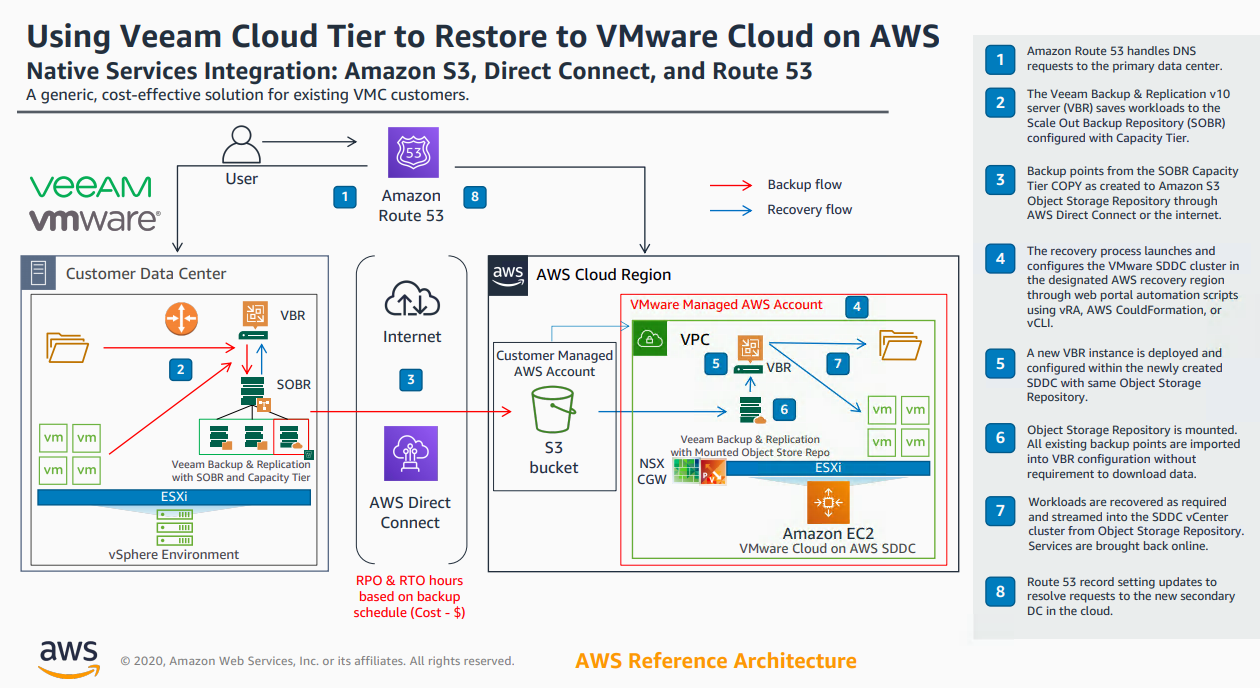
With the release of v10 of Backup & Replication came significant enhancements to the Cloud Tier. As I wrote about here , we introduced Copy Policy , Immutabi...
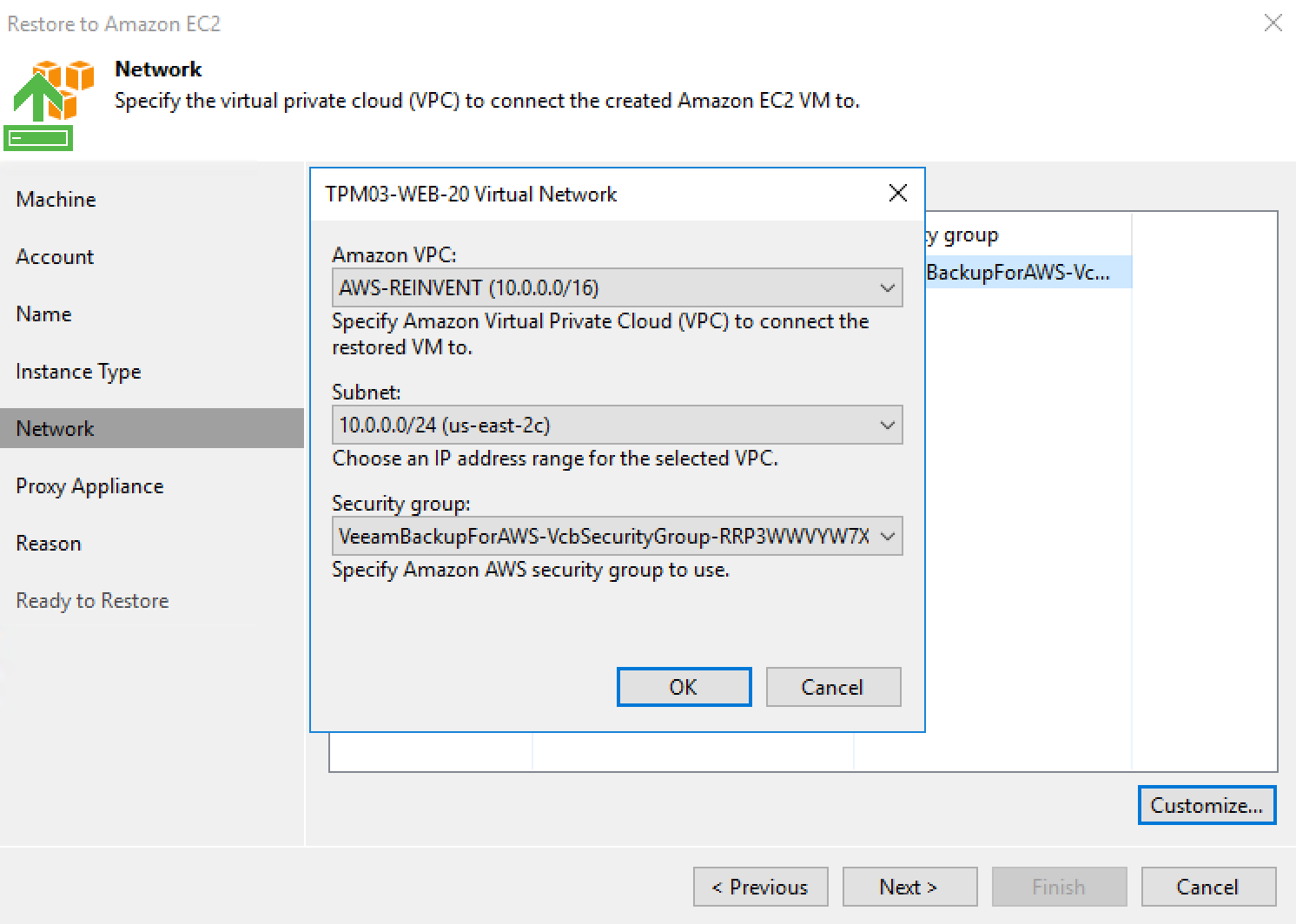
Version 10 of Veeam Backup & Replication isn't too far away and we are currently at the end of a second private BETA for our customers and partners. There ha...
Last week I wrote about a cool new enhancement coming in v10 of Backup & Replication where we are introducing a Mount function that will enable users to impo...
Version 10 of Veeam Backup & Replication isn't too far away and we are currently at the end of a second private BETA for our customers and partners. There ha...
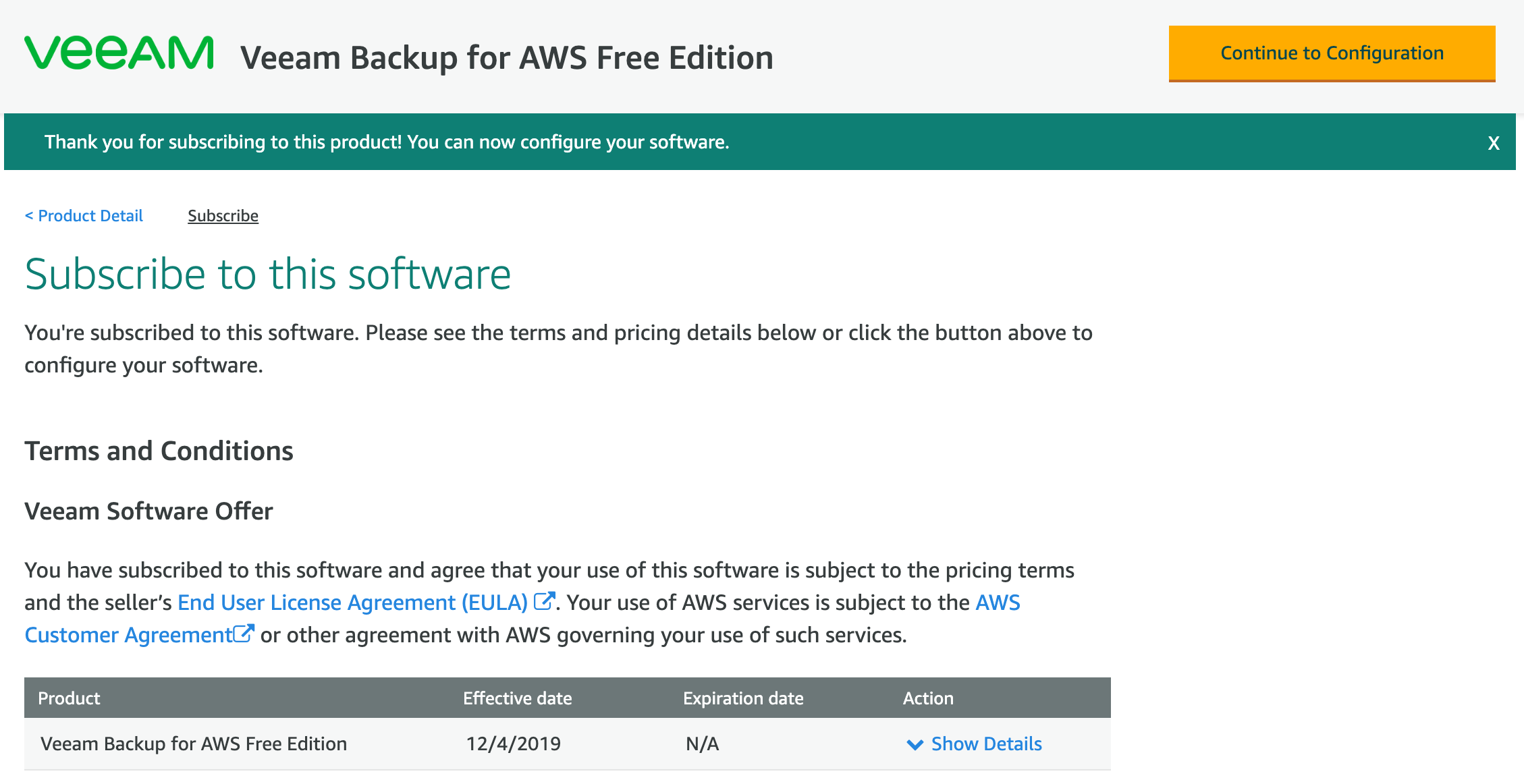
This week at AWS re:Invent, exciting news for a lot of us in Veeam was announced as we made available for GA Veeam Backup for AWS ( Build 1.0.0.1345 ). Avail...
Yesterday I presented at Tech Field Day 20. My first topic was on the enhancements we are bringing to Cloud Tier in our Backup & Replication v10 release. Ric...

Apart from the K word, there was one other enduring message that I think a lot of people took home from VMworld 2019 . That is, that Dev and Ops should be co...
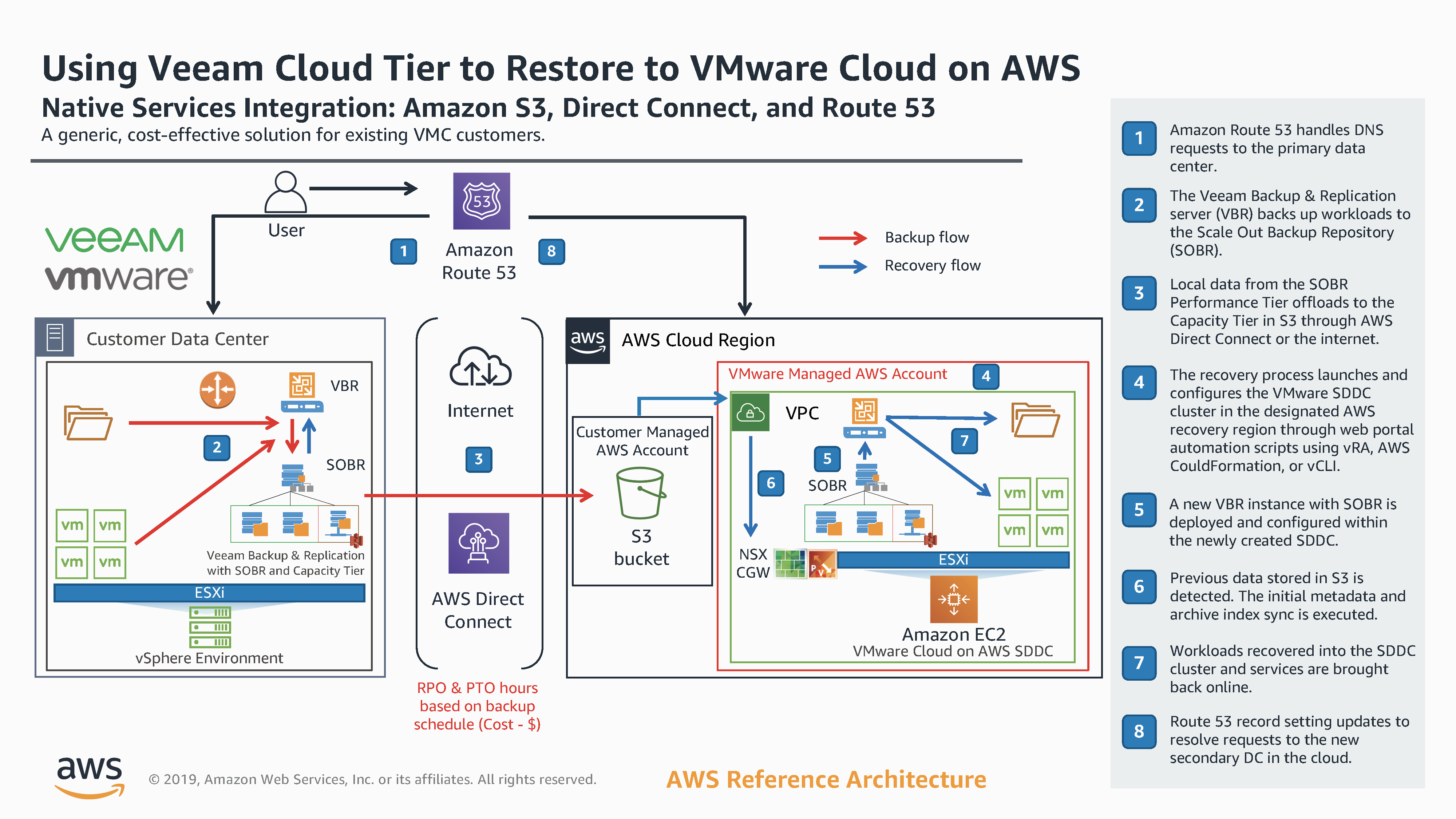
Since Veeam Cloud Tier was released as part of Backup & Replication 9.5 Update 4 , i've written a lot about how it works and what it offers in terms of offlo...
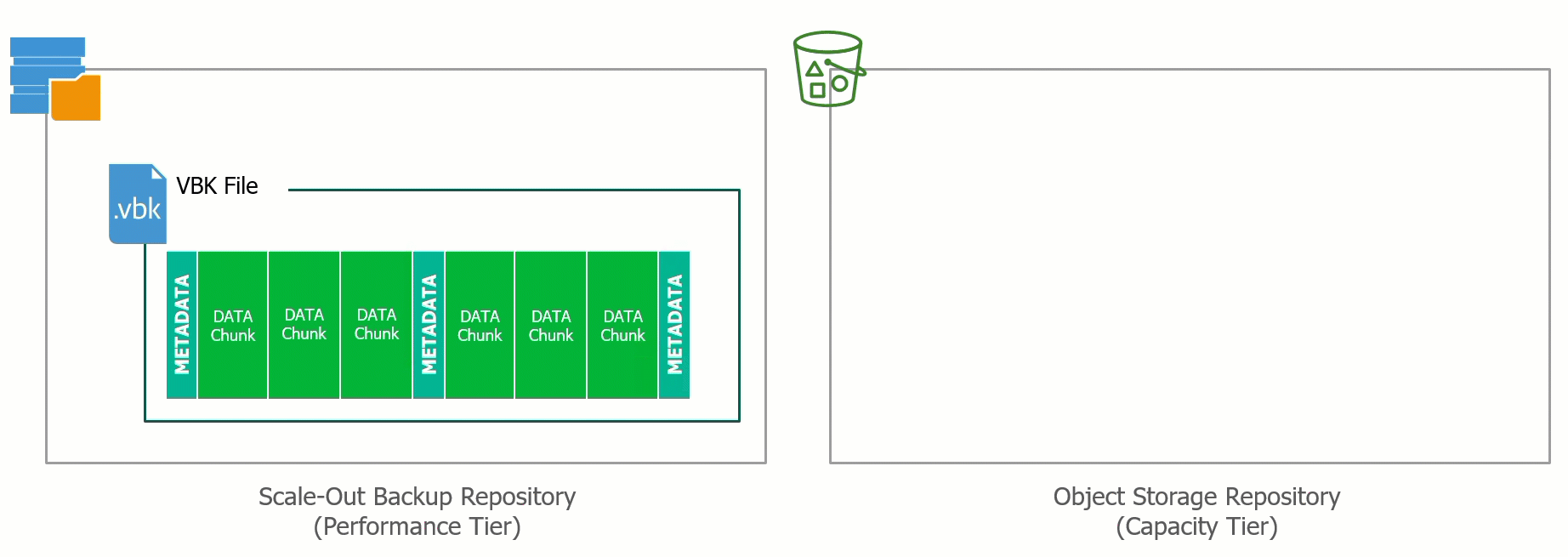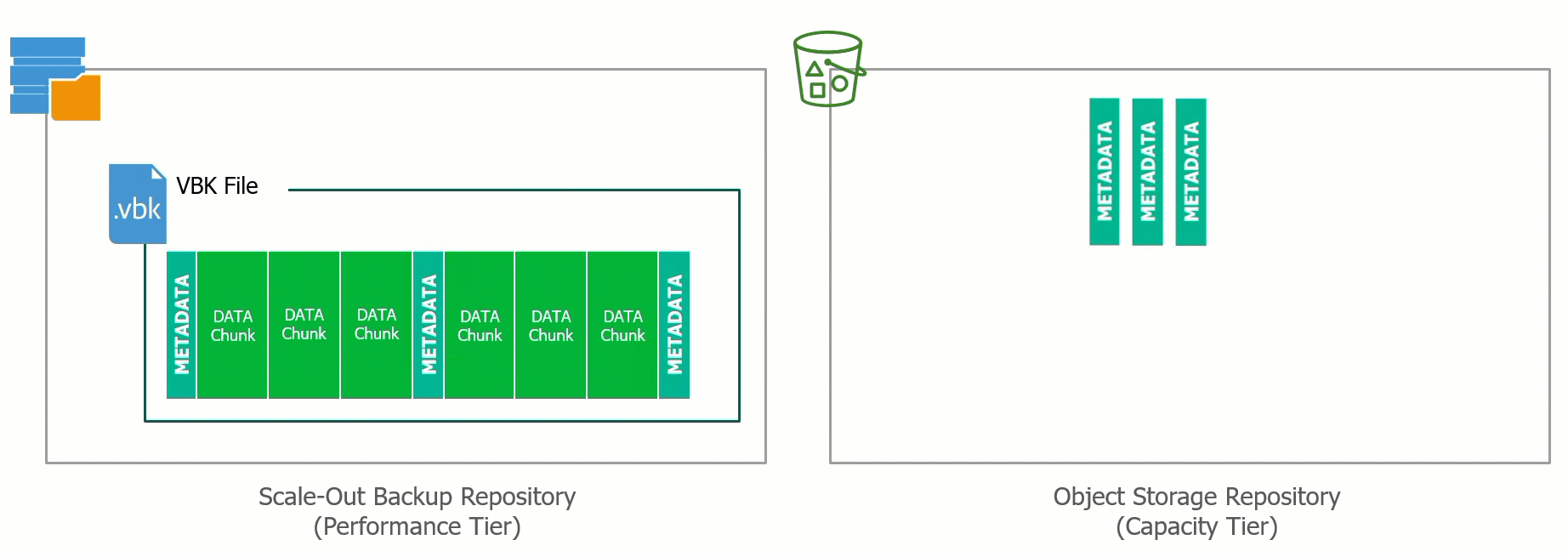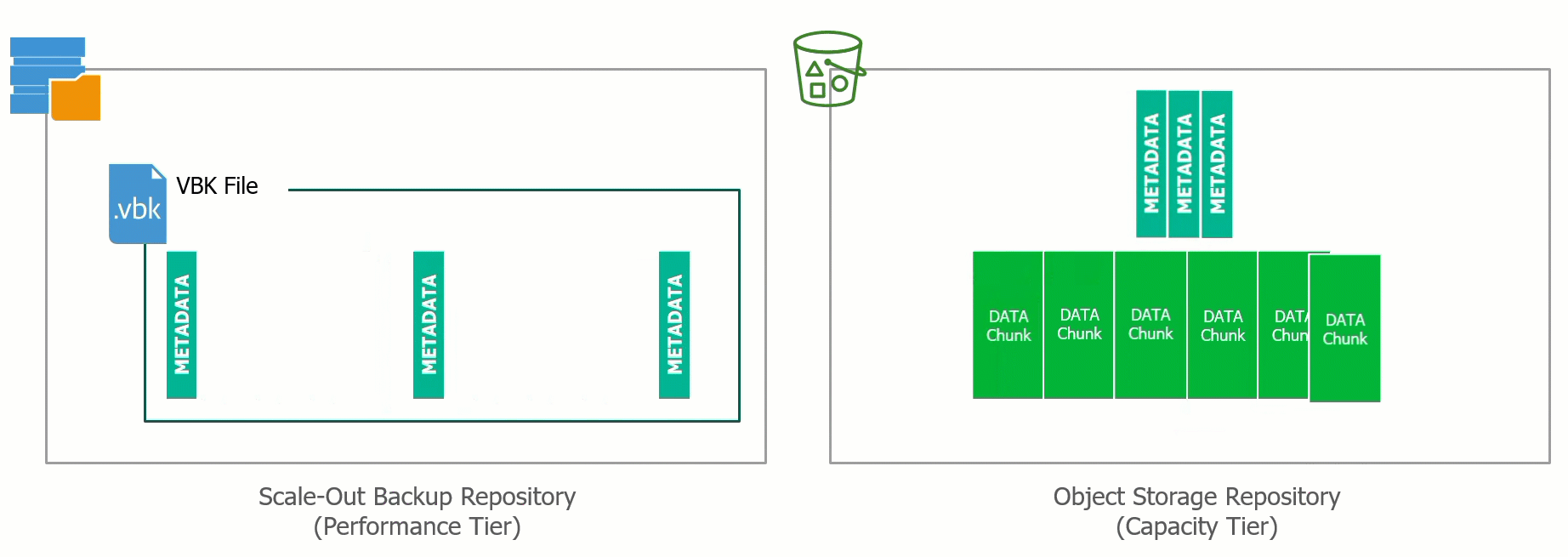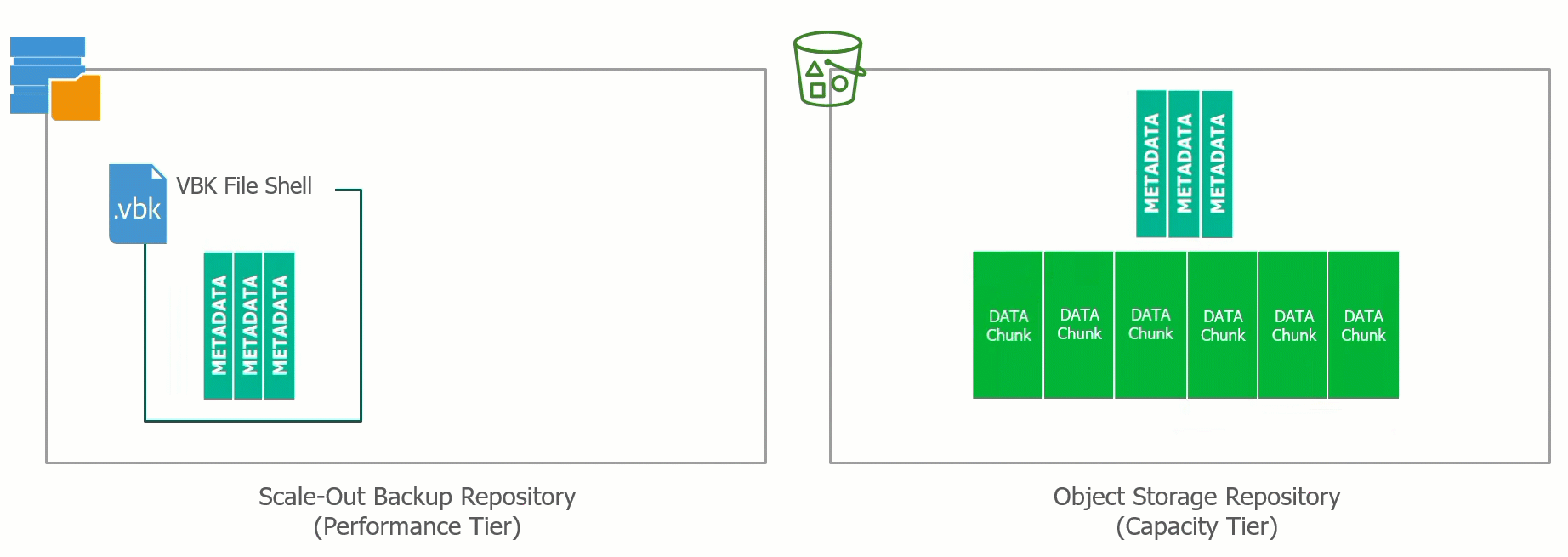
At the recent Cloud Field Day 5 (CFD#5) I presented a deep dive on the Veeam Cloud Tier which was released as a feature extension of our Scale Out Backup Rep...
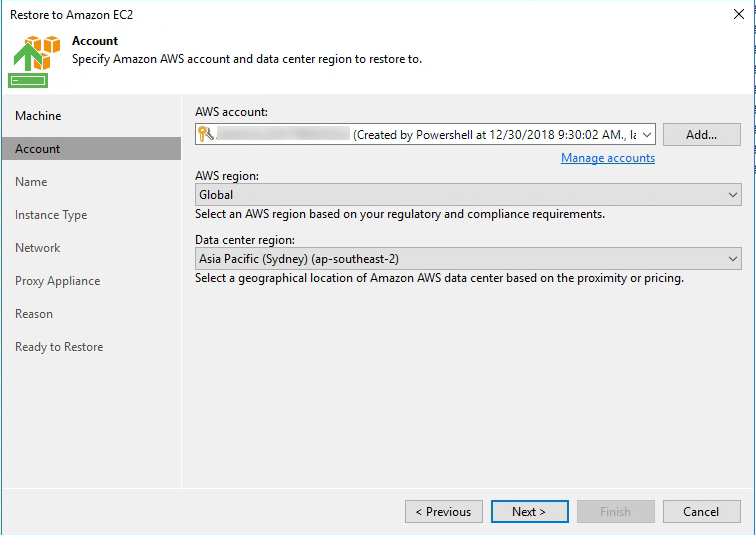
When Veeam Backup & Replication 9.5 Update 4 went Generally Available a couple of weeks ago I posted a What’s in it for Service Providers blog. In that post ...
With the release of Update 4 for Veeam Backup & Replication 9.5 we further enhanced our overall cloud capabilities by adding a number of new features and enh...
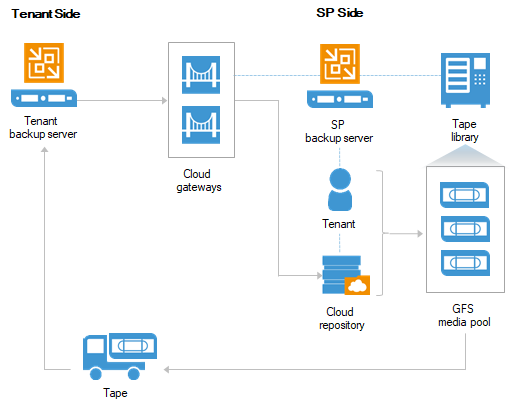
When Veeam Backup & Replication 9.5 Update 4 went Generally Available a couple of weeks ago I posted a What's in it for Service Providers blog. In that post ...

When looking at how to configure networking for interactions between a VMware Cloud on AWS SDDC and an Amazon VPC there is a little bit to grasp in terms of ...
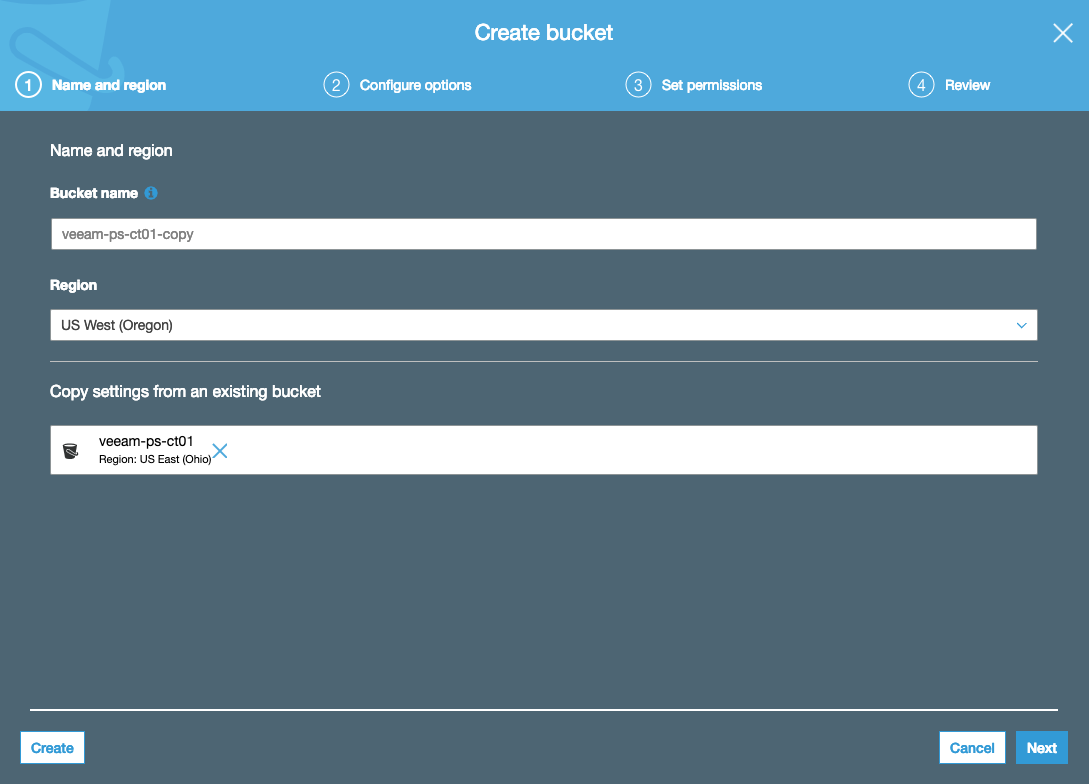
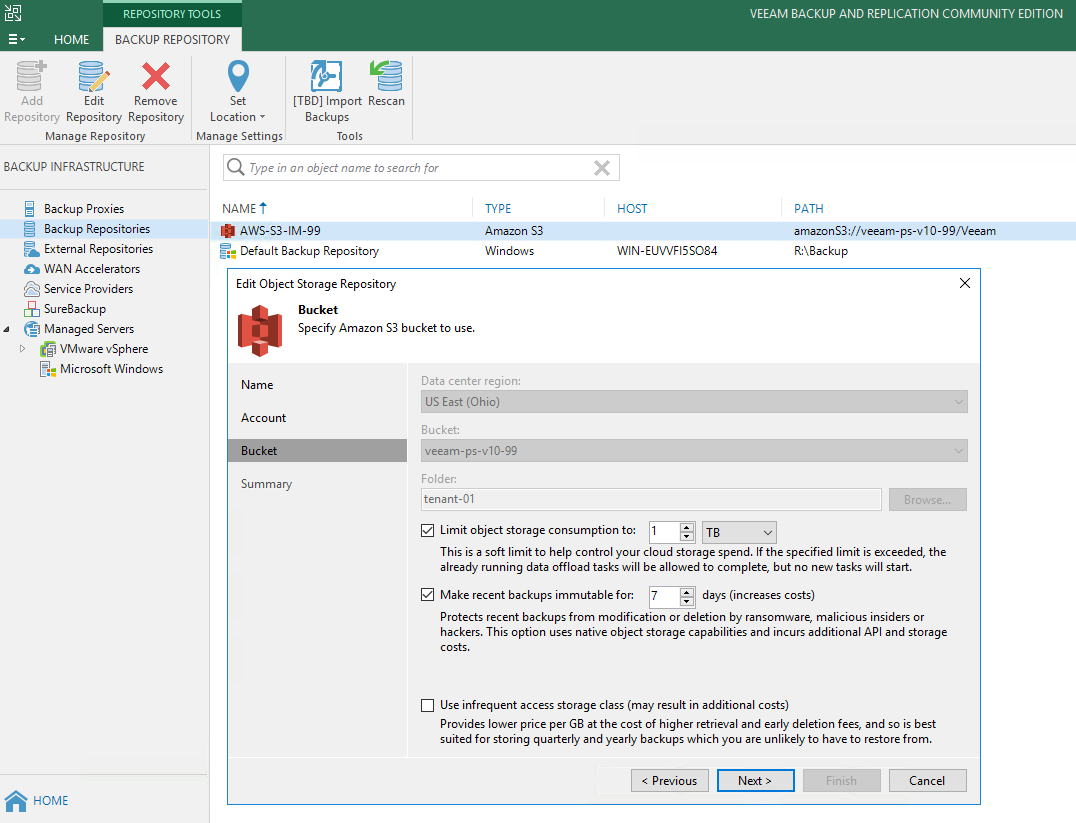
I am doing some work on validated restore scenarios using the new Veeam Cloud Tier that backed by an Object Storage Repository pointing at an Amazon S3 Bucke...
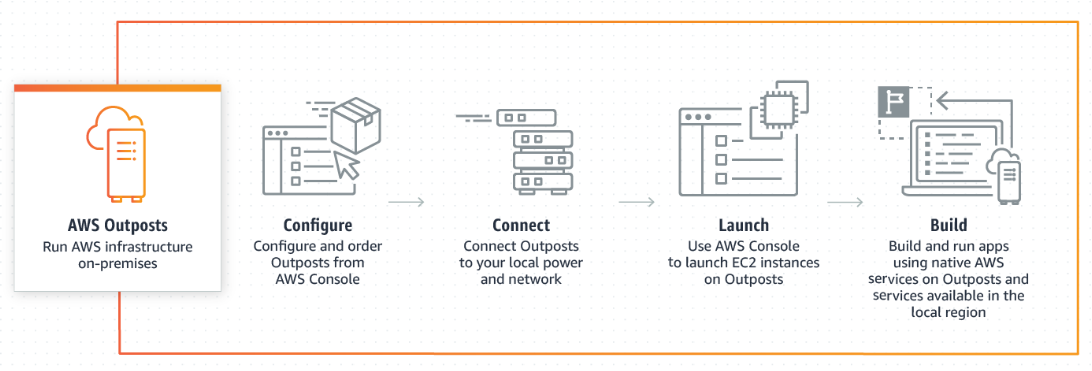
Now that AWS re:Invent 2018 has well and truly passed...the biggest industry shift to come out of the event from my point of view was the fact that AWS are g...
There was so much to take away from AWS re:Invent last week . In my opinion, having attended a lot of industry events over the past ten or so years, this yea...

This week, myself and David Hill presented at AWS re:Invent 2018 around what at Veeam is offering by way of providing data protection and availability for na...
AWS re:Invent 2018 is happening next week and for the first time Veeam is at the event in a big way! Last year, we effectively tested the waters with a small...
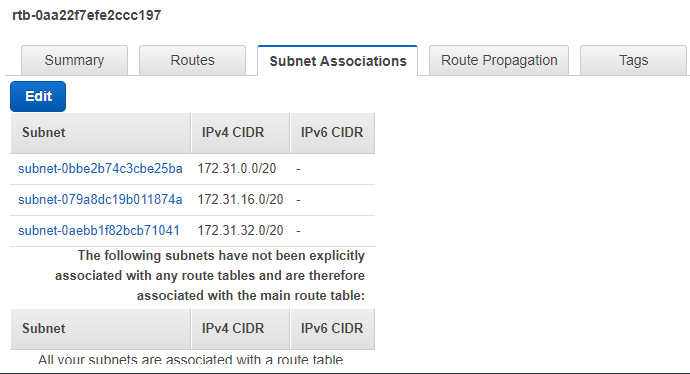
Yesterday I wrote about how to deploy a Single Host SDDC through the VMware Cloud on AWS web console. I mentioned some pre-requisites that where required in ...
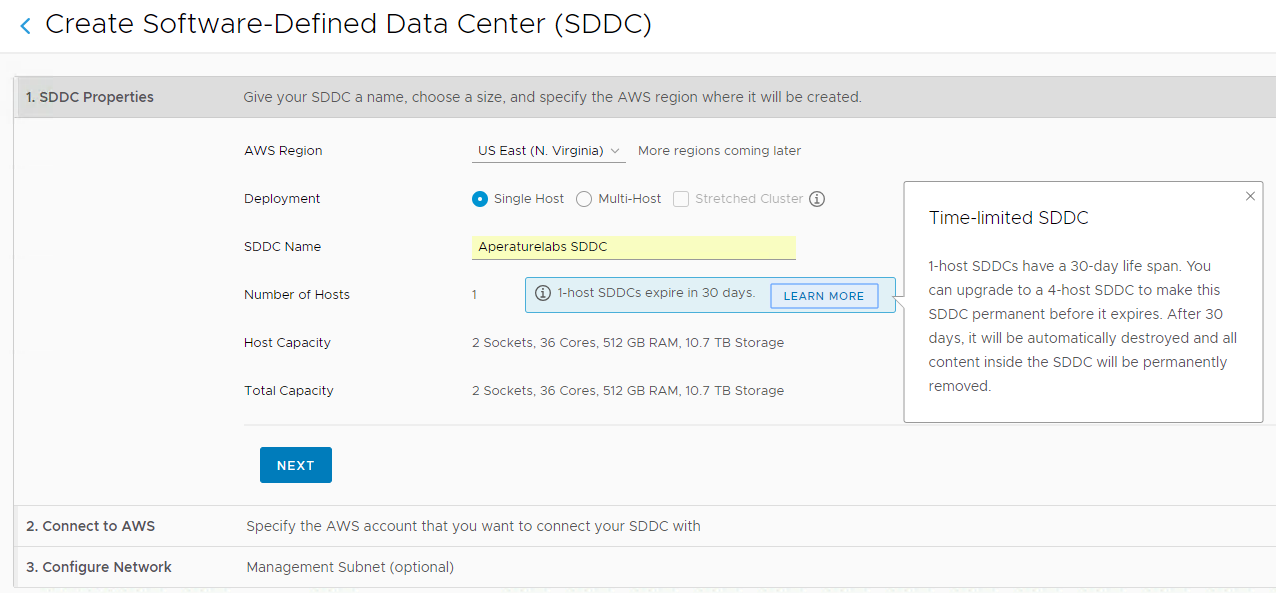
While preparing for my VMworld session with Michael Cade on automating and orchestrating the deployment of Veeam into VMware Cloud on AWS, we have been testi...
Back in April, I was lucky enough to present at the AWS Summit in Singapore . The session was a joint one with Alex Thomson from N2WS on how Veeam and N2WS a...

A couple of weeks ago I stumbled upon Zenko via a LinkedIn post. I was interested in what it had to offer and decided to go and have a deeper look. With Veea...
A month of so ago I wrote a post on deploying Veeam Powered Network into an AWS VPC as a way to extend the VPC network to a remote site to leverage a Veeam L...
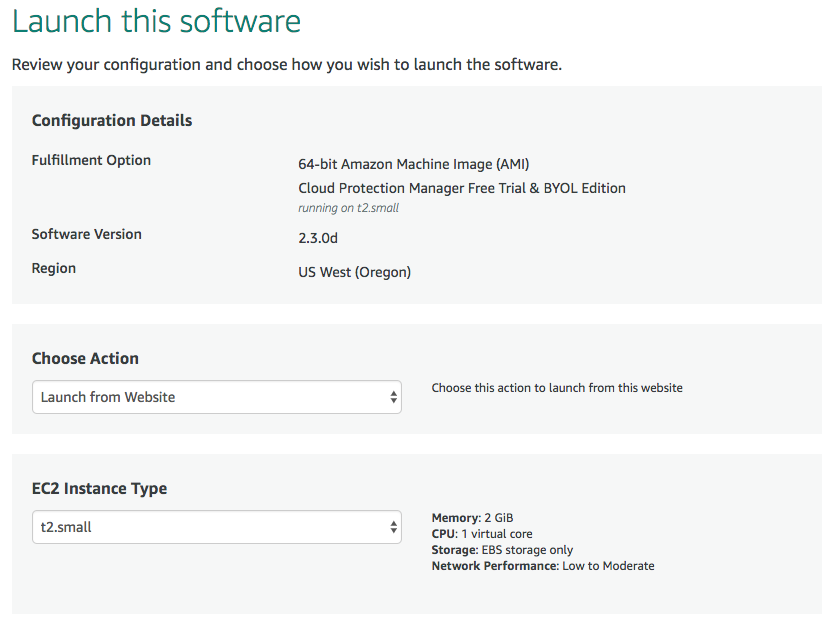
Earlier this year Veeam acquired N2WS after announcements last year of a technology partnership at VeeamON 2017. The more I tinker with Cloud Protection Mana...
I'm ok admitting that I am still learning as I progress through my career and I'm ok to admit when things go wrong. Learning from mistakes is a crucial part ...
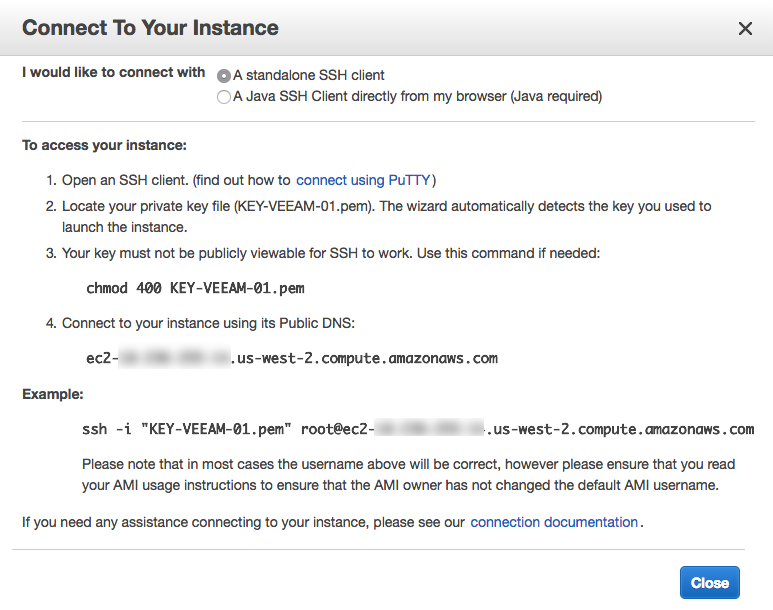
I've been doing a little more within AWS over the past month or so related to my work with VMware Cloud on AWS and the setting up of EC2 instances to use as ...
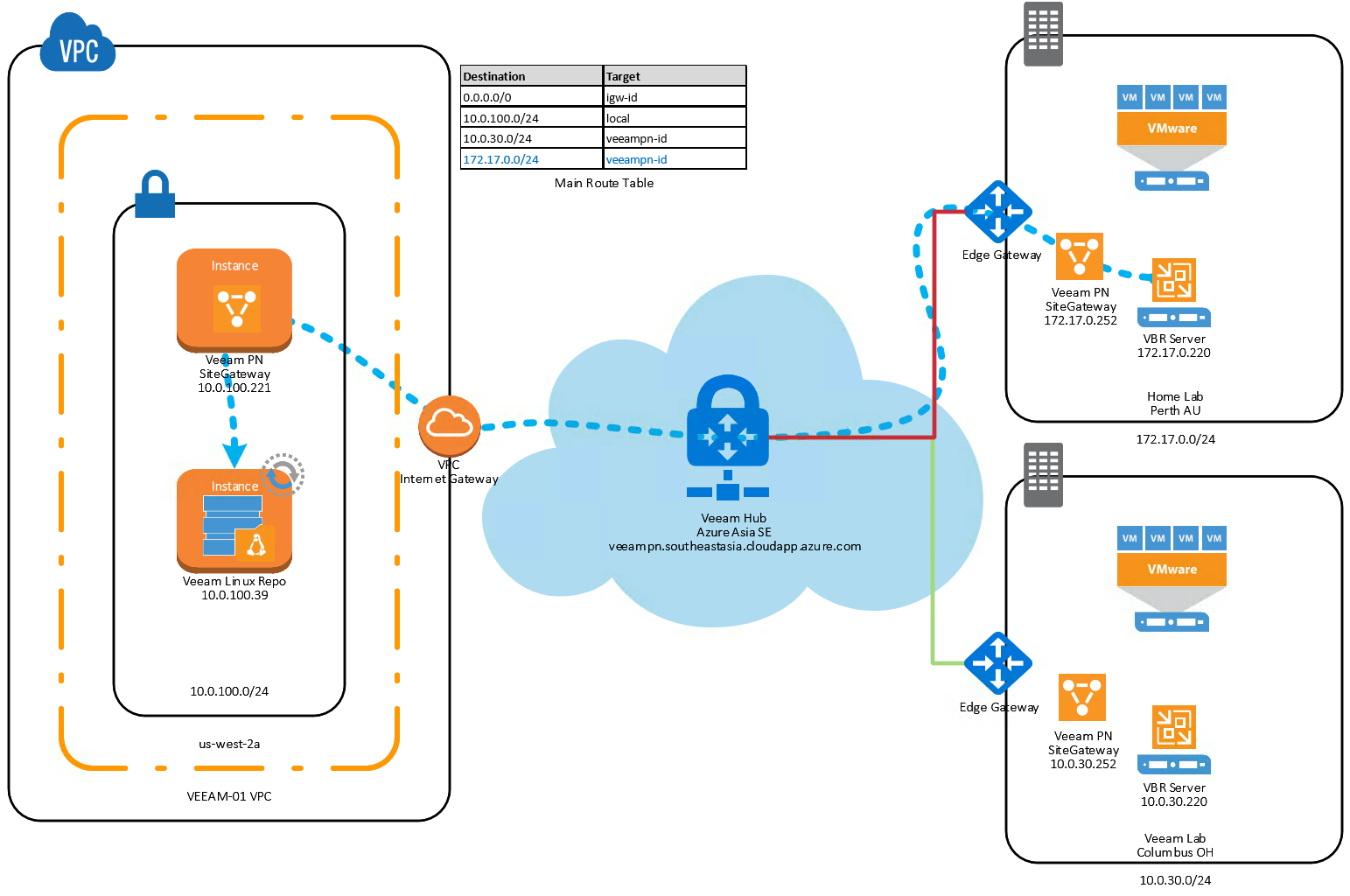
Veeam PN is a very cool product that has been GA for about four months now. Initially we combined the free product together with Veeam Direct Restore to Micr...
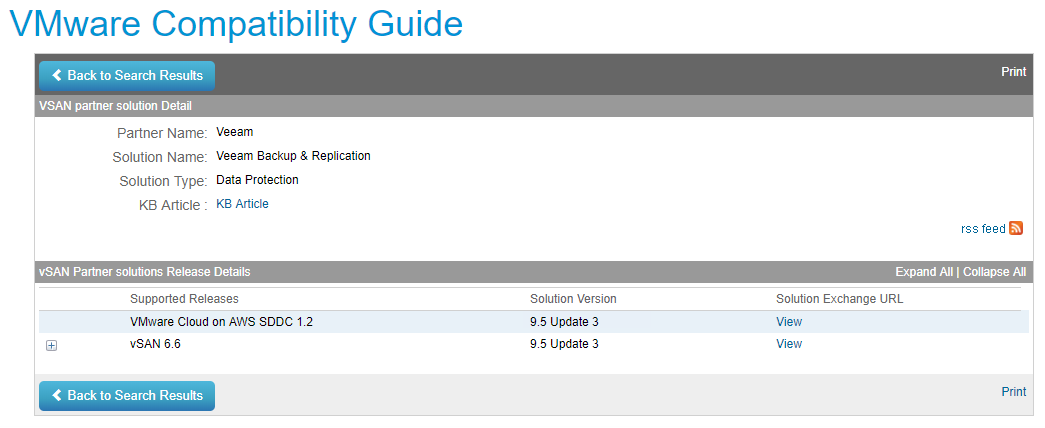
At VMworld 2017 Veeam was announced as one of only two foundation Data Protection partners for VMware Cloud on AWS. This functionality was dependant on the r...
Given this was my first AWS re:invent I didn't know what to expect from the keynotes and while Wednesday's keynote focused on new release announcements, Thur...

Today is the first day offical day of AWS re:Invent 2017 and things are kicking off with the global partner summit. Today also is my first day of AWS re:Inve...
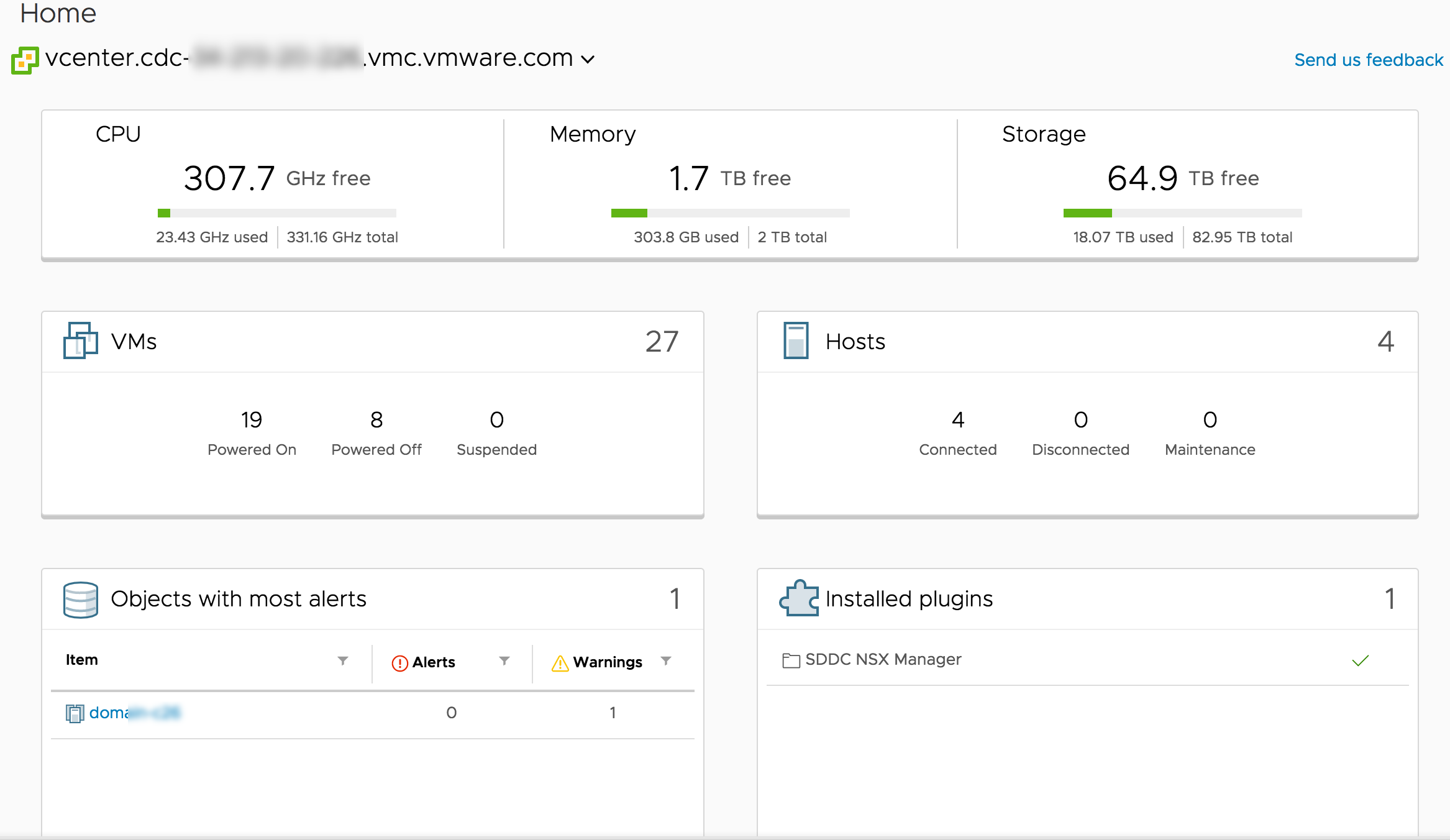
Last week at VMworld 2017 in the US, VMware announced the initial availability of VMware Cloud on AWS . It was the focal point for VMware at the event and pr...