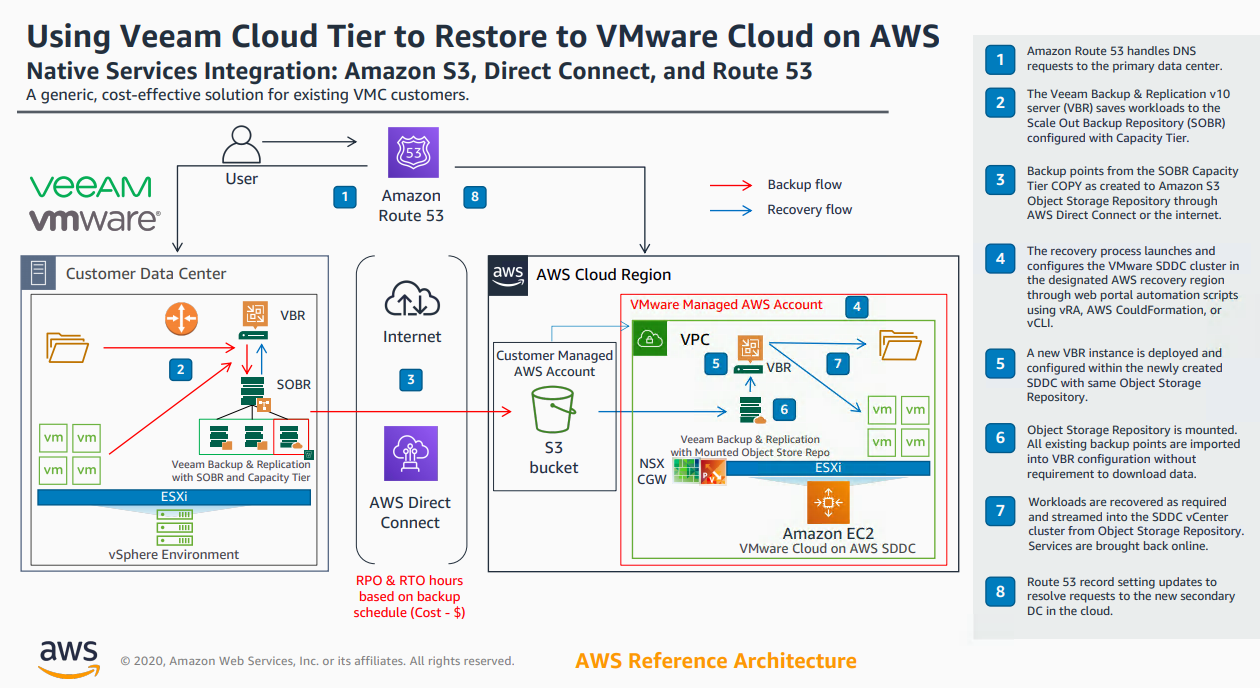
v10 Update: On Demand Recovery with Cloud Tier and VMware Cloud on AWS
With the release of v10 of Backup & Replication came significant enhancements to the Cloud Tier. As I wrote about here , we introduced Copy Policy , Immutabi...
Tag
12 posts
With the release of v10 of Backup & Replication came significant enhancements to the Cloud Tier. As I wrote about here , we introduced Copy Policy , Immutabi...
Last week I wrote about a cool new enhancement coming in v10 of Backup & Replication where we are introducing a Mount function that will enable users to impo...
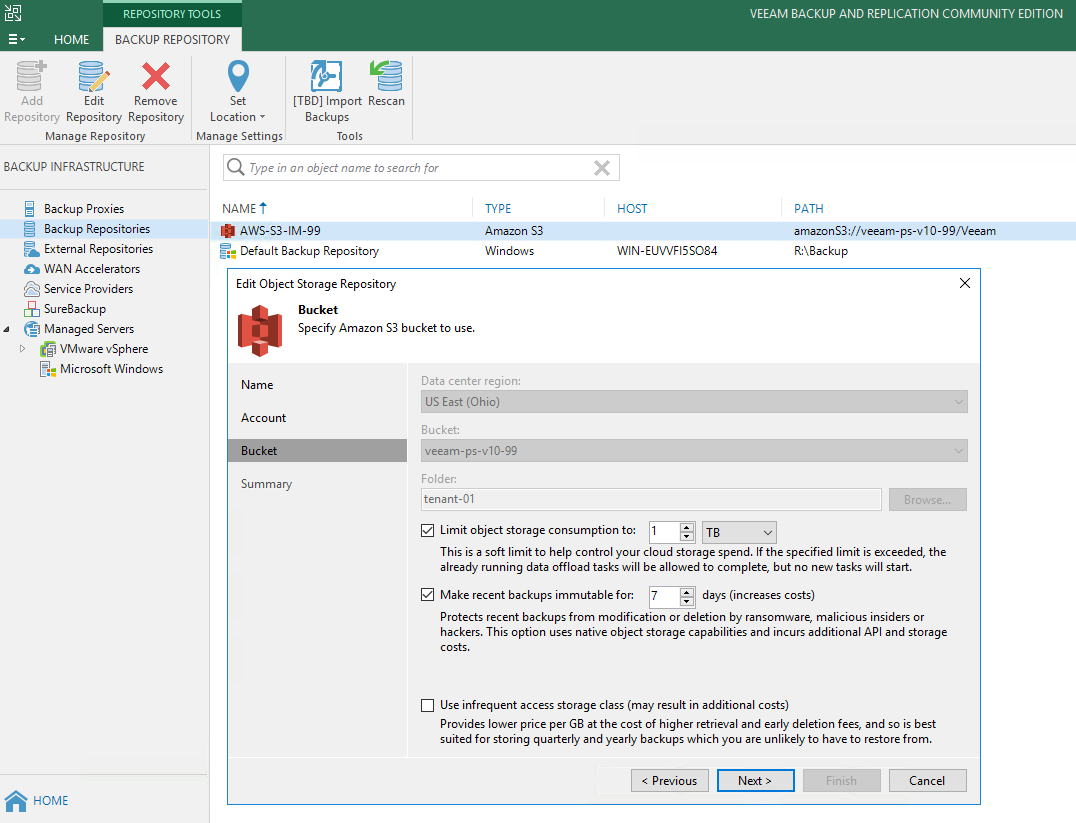
Version 10 of Veeam Backup & Replication isn't too far away and we are currently at the end of a second private BETA for our customers and partners. There ha...

Tech Field Day 20 has come and gone, and it was an honour to play a small part in the 10th year anniversary Tech Field Day event. This was my second TFD even...
Yesterday I presented at Tech Field Day 20. My first topic was on the enhancements we are bringing to Cloud Tier in our Backup & Replication v10 release. Ric...
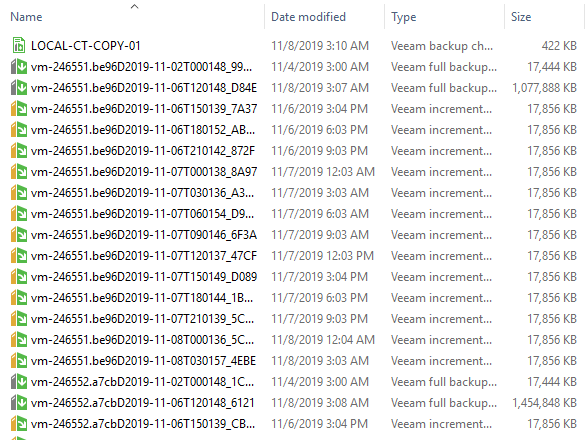
Version 10 of Veeam Backup & Replication isn't too far away and we are currently in the middle of a second private BETA for our customers and partners. There...
For a look sneak peek at the highly anticipated Cloud Tier Copy mode... head here to veeam.com https://www.veeam.com/blog/v10-sneak-peek-cloud-tier-copy-mode...
Last week at VeeamON 2019, Dustin Albertson and myself delivered a two part deep dive session on Cloud Tier, which was released in Update 4 of Veeam Backup &...
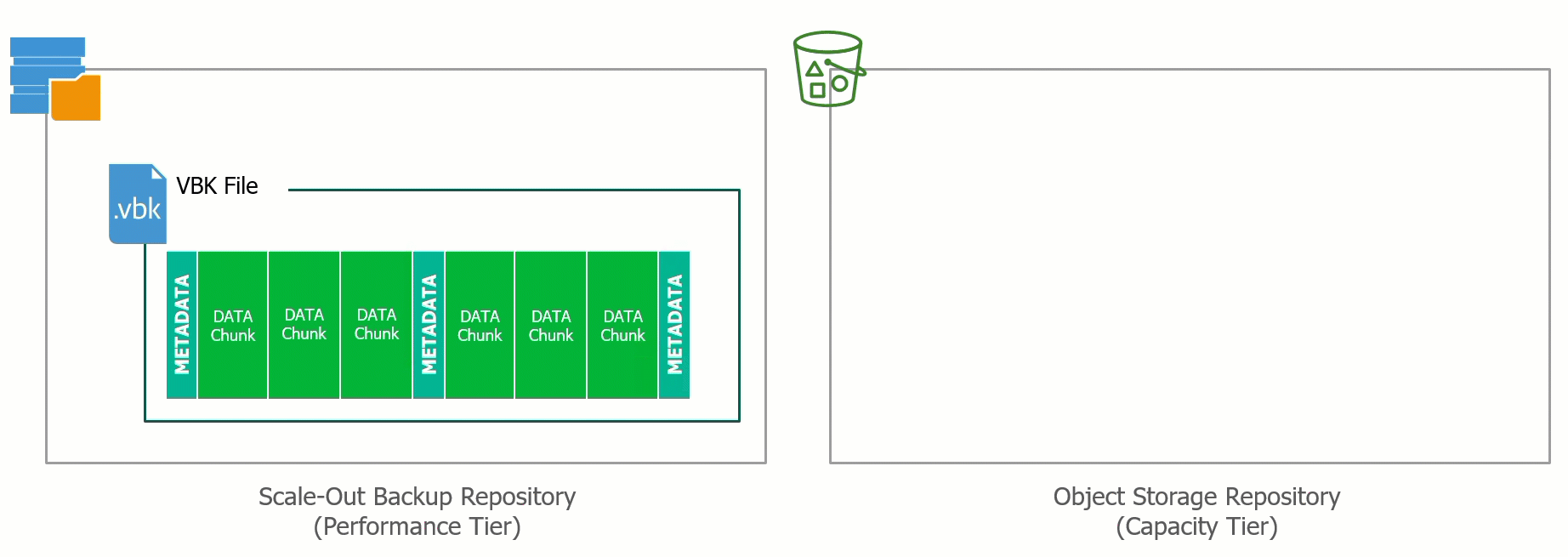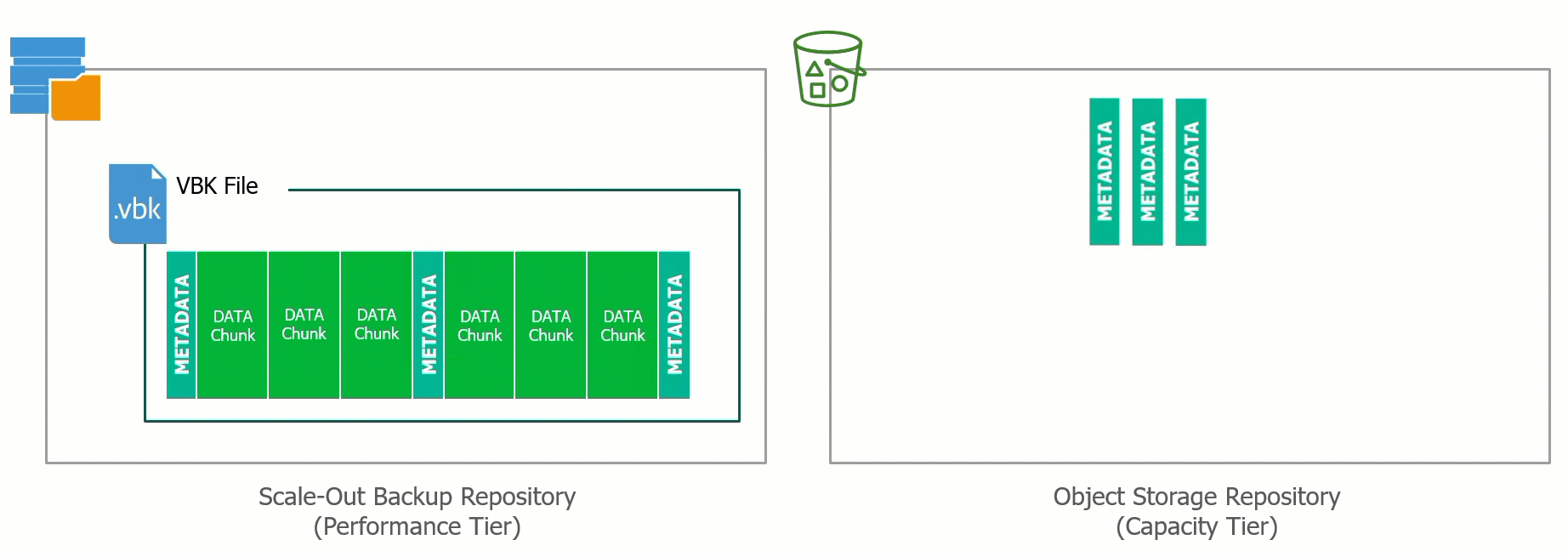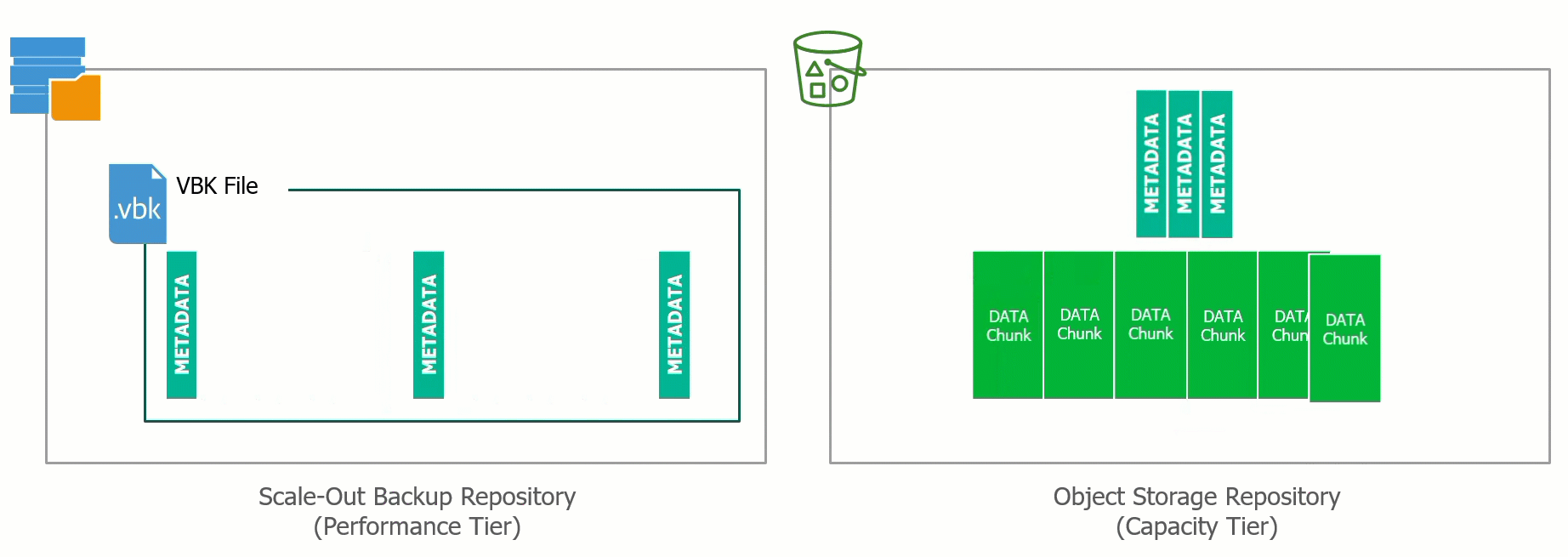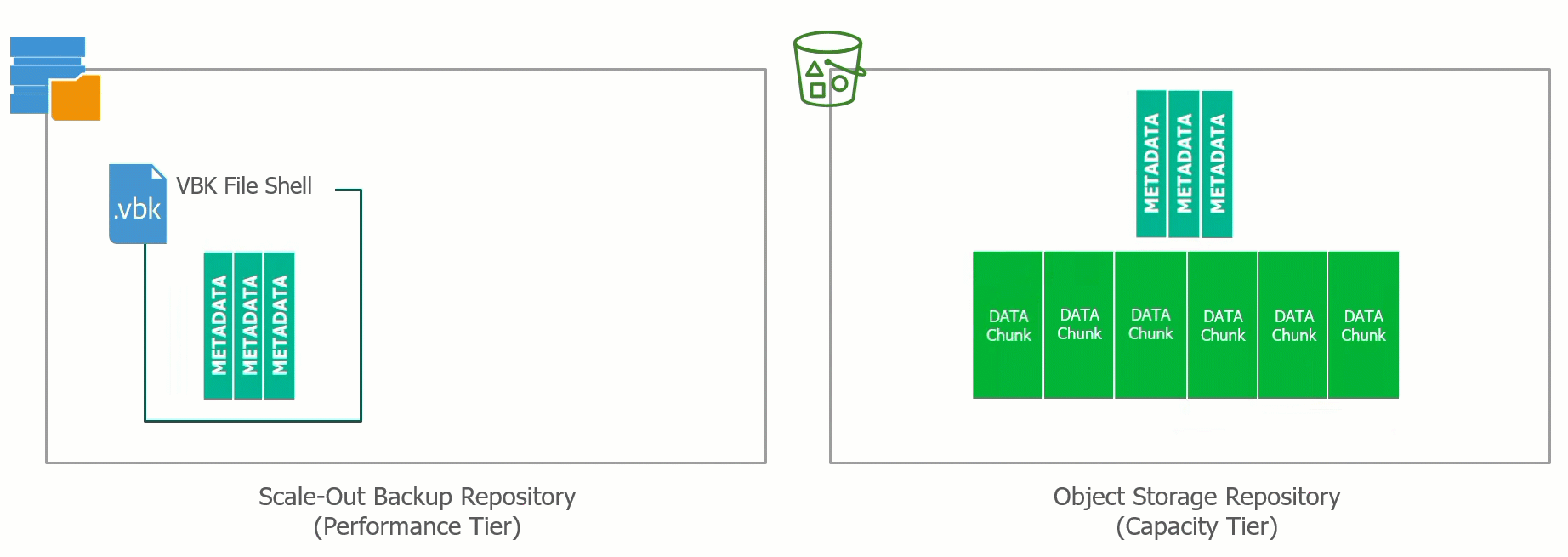
At the recent Cloud Field Day 5 (CFD#5) I presented a deep dive on the Veeam Cloud Tier which was released as a feature extension of our Scale Out Backup Rep...
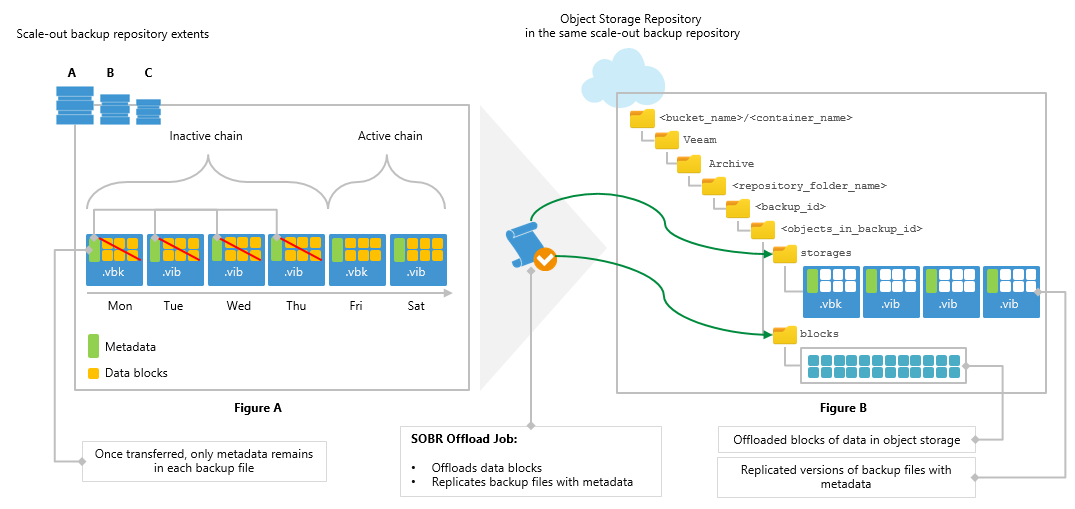
Yesterday at Cloud Field Day 5, I presented a deep dive on our Cloud Tier feature that was released as a feature for Scale Out Backup Repository (SOBR) in Ve...
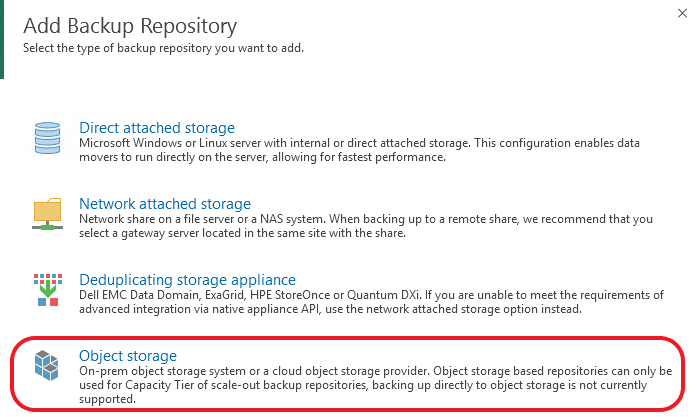
When Veeam Backup & Replication 9.5 Update 4 went Generally Available in late January I posted a What’s in it for Service Providers blog. In that post I brie...
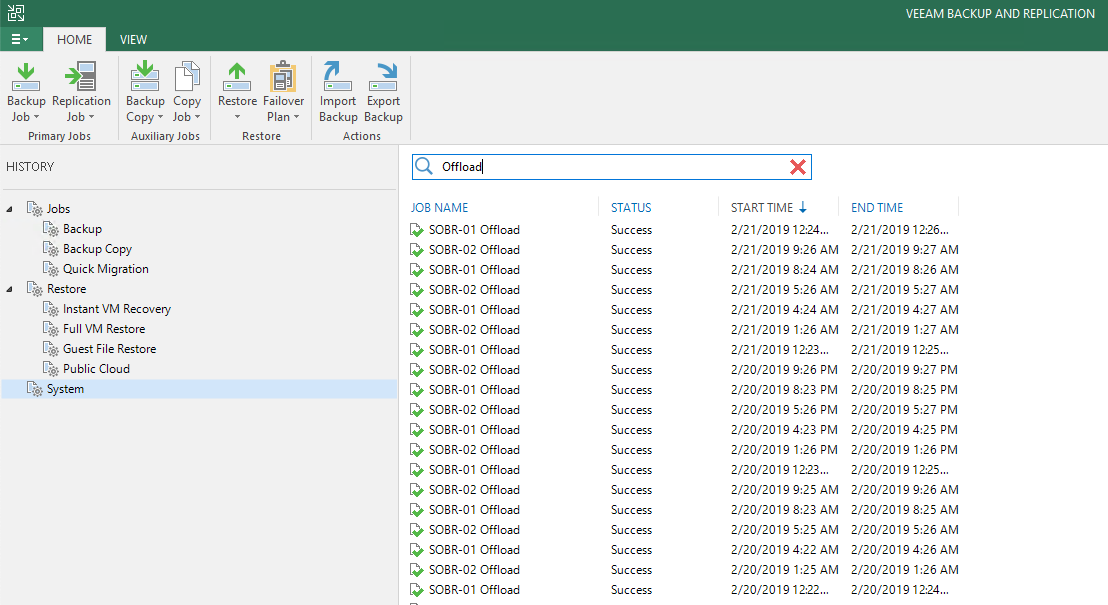
With the release of Update 4 for Veeam Backup & Replication 9.5 we introduced the Cloud Tier, which is an extension of the Scale Out Backup Repository (SOBR)...