
Backup for Microsoft 365 v7 - Self Service, Immutability and Integrations!
The releases keep coming in 2023 from Veeam! This week, we have released the GA of Veeam Backup for Microsoft 365 (VBM) version 7.0 ( Build 7.0.0.2911 ). Thi...
Tag
15 posts
The releases keep coming in 2023 from Veeam! This week, we have released the GA of Veeam Backup for Microsoft 365 (VBM) version 7.0 ( Build 7.0.0.2911 ). Thi...

At VeeamON 2022 a couple weeks ago, Dustin Albertson and myself presented a session on what Object Storage functionality is going to look like in v12 of Veea...

A couple of weeks ago I wrote a quick post about Longhorn as a storage provider for my Kubernetes labs. While that has worked pretty well, I thought I would ...

When Veeam Backup & Replication v11 went Generally Available on the 24th of February I posted the What’s in it for Service Providers blog. In that post I bri...

The only thing hotter than Kubernetes at the moment is Crypto. While the price of BitCoin takes centre stage for the most, there is so much more behind this ...
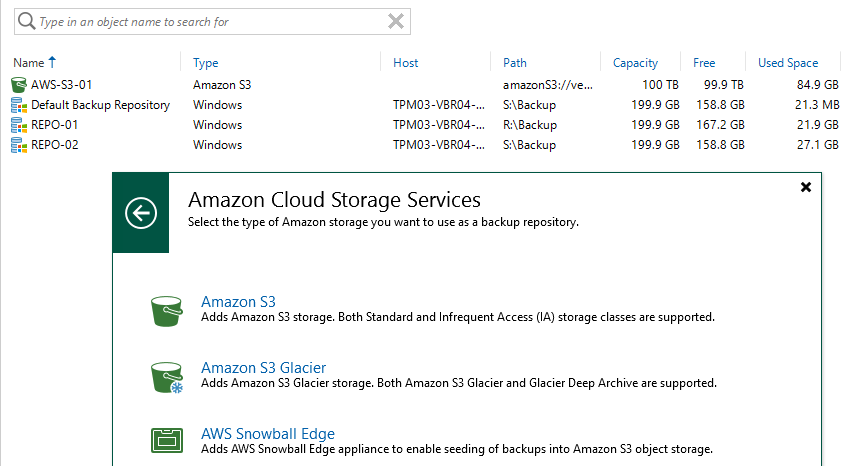
Since version 9.5 Update 4 of Veeam Backup & Replication we have had support to firstly move, then copy ( as part of v10 ) backup data from what is, traditio...

We always talk about starting with backup... and it is true that you can't recover unless you have a solid backup, however more and more the recovery of work...
Last week I wrote about a cool new enhancement coming in v10 of Backup & Replication where we are introducing a Mount function that will enable users to impo...
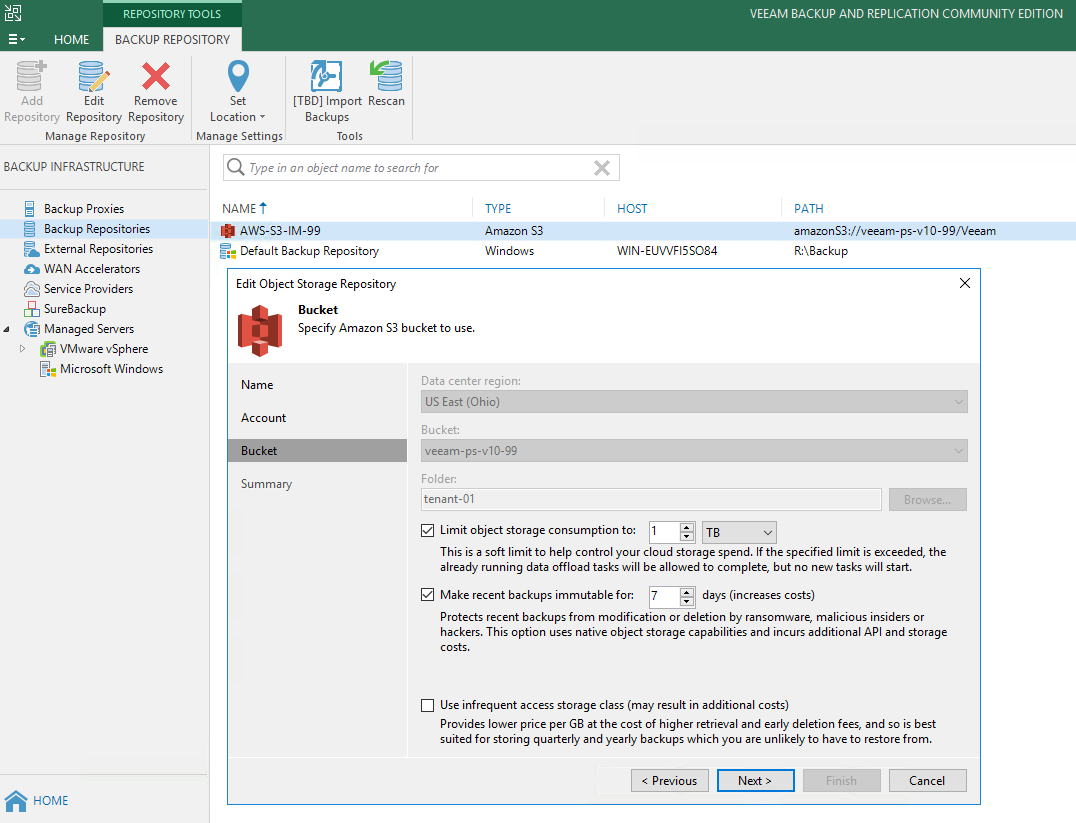
Version 10 of Veeam Backup & Replication isn't too far away and we are currently at the end of a second private BETA for our customers and partners. There ha...
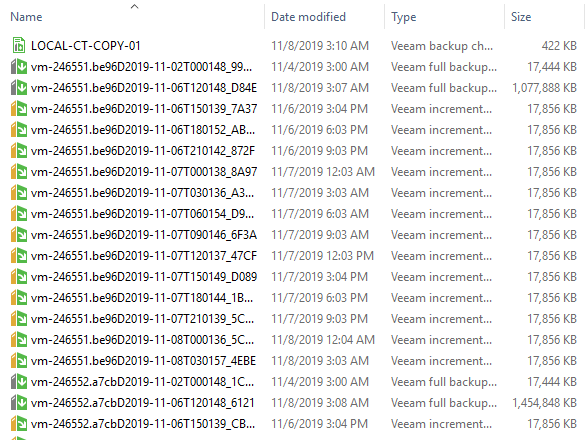
Version 10 of Veeam Backup & Replication isn't too far away and we are currently in the middle of a second private BETA for our customers and partners. There...

Overnight at Microsoft Ignite, we announced availability of the Public Beta for the next version of Veeam Backup for Microsoft Office 365. This is again a mu...
For a look sneak peek at the highly anticipated Cloud Tier Copy mode... head here to veeam.com https://www.veeam.com/blog/v10-sneak-peek-cloud-tier-copy-mode...
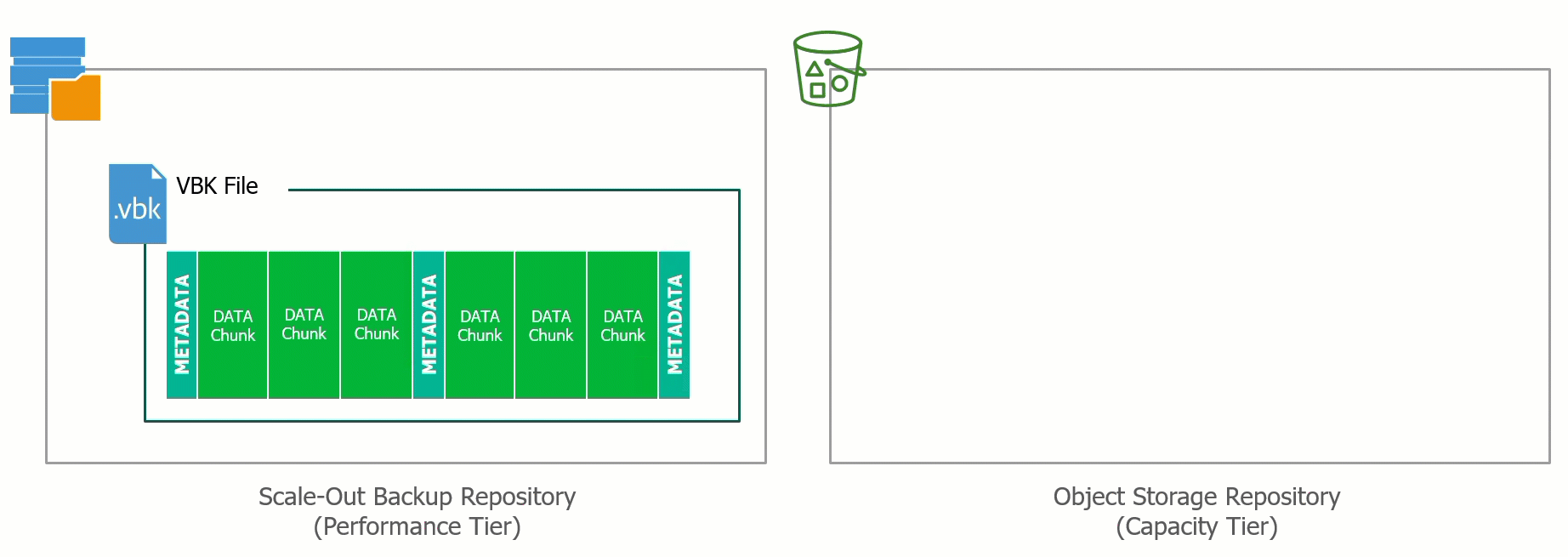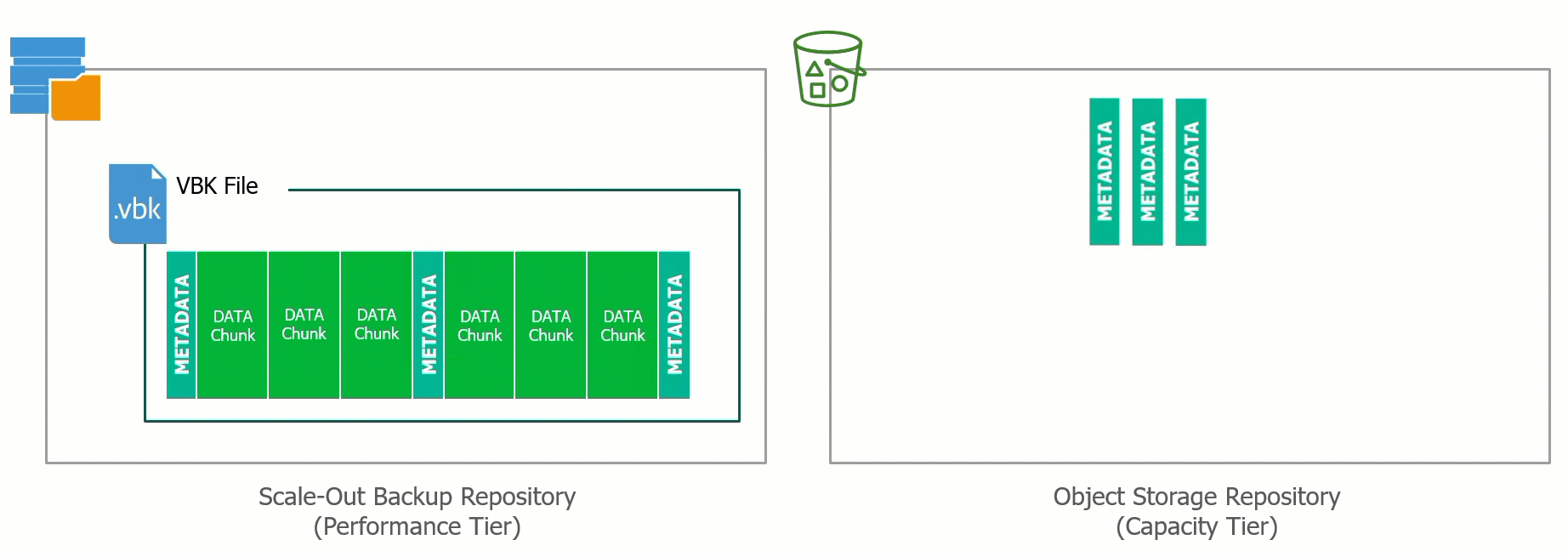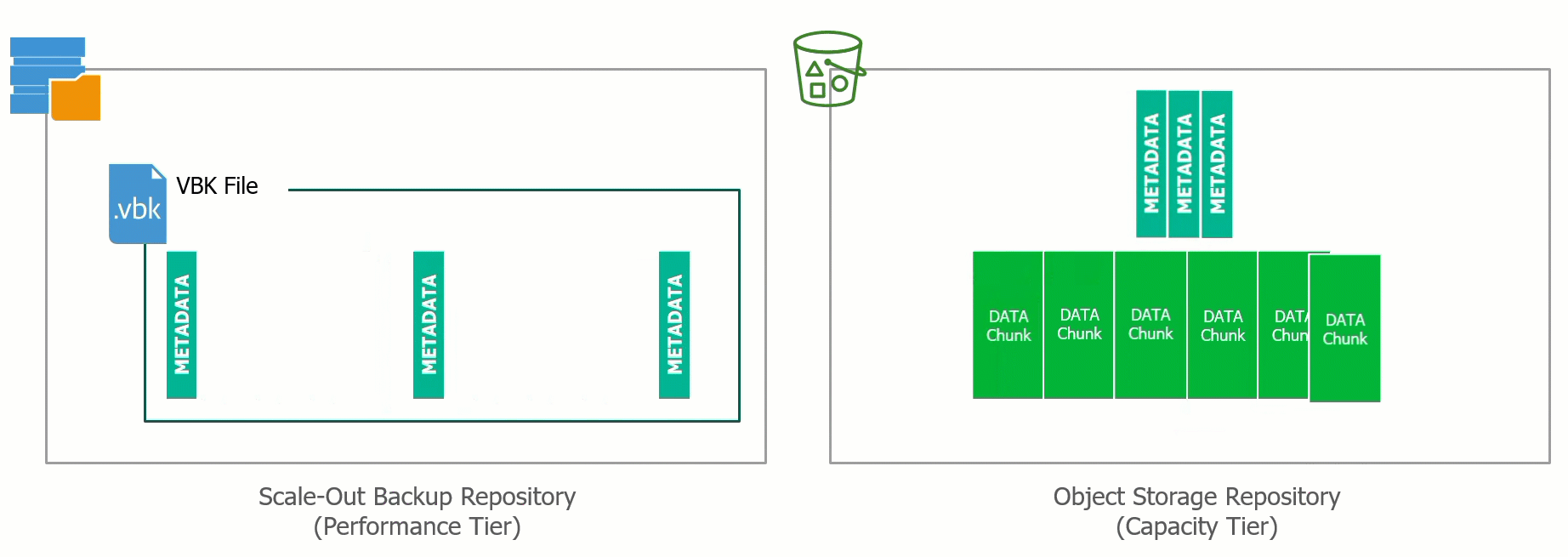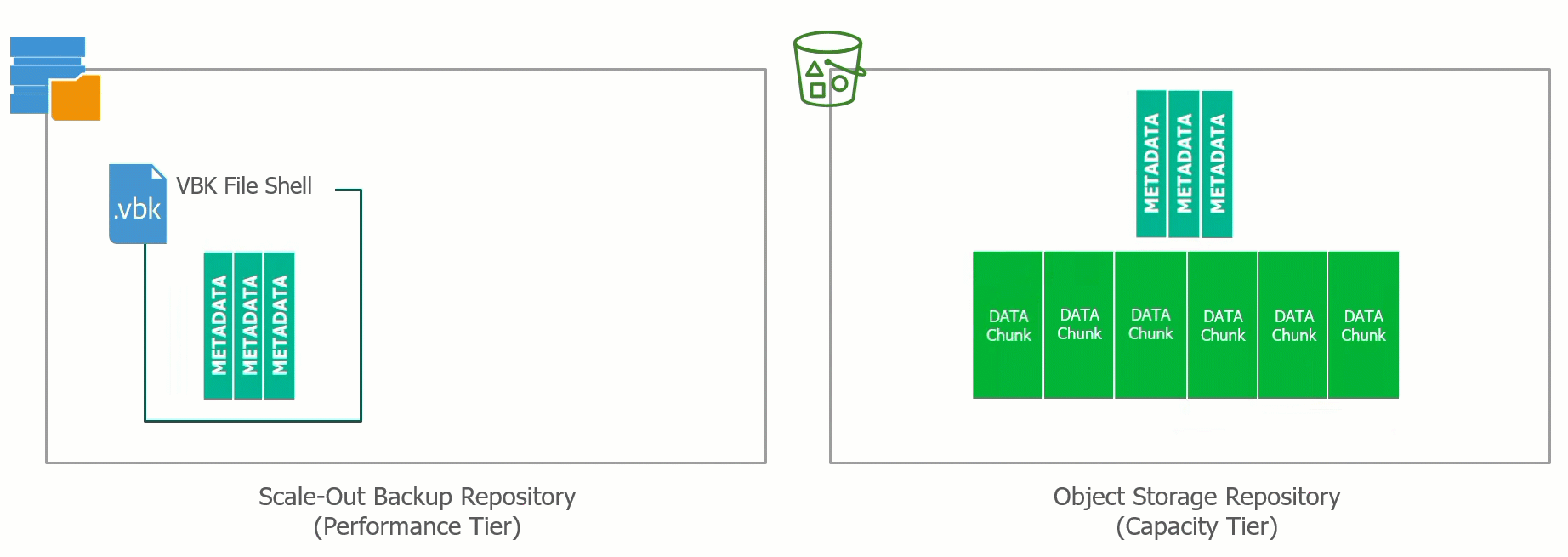
At the recent Cloud Field Day 5 (CFD#5) I presented a deep dive on the Veeam Cloud Tier which was released as a feature extension of our Scale Out Backup Rep...
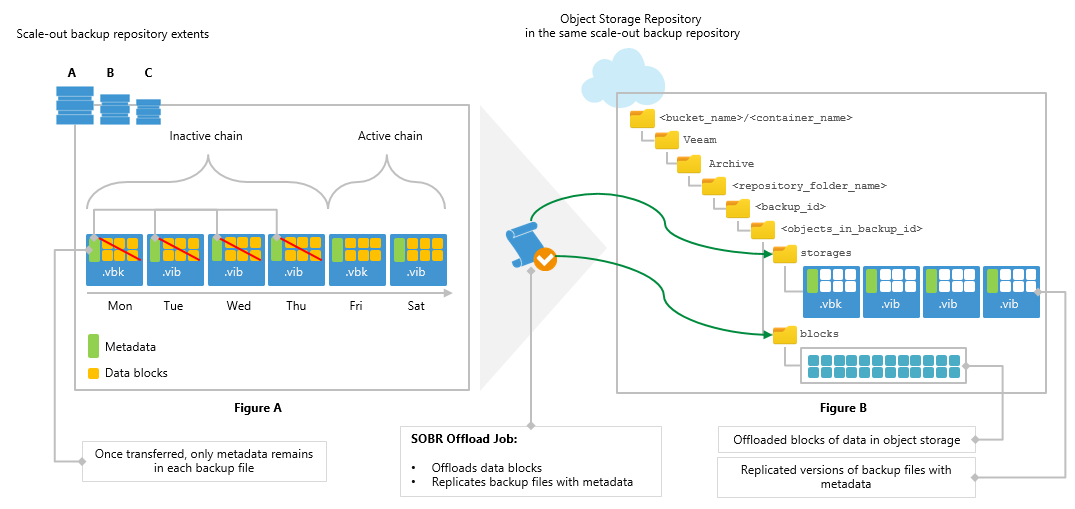
Yesterday at Cloud Field Day 5, I presented a deep dive on our Cloud Tier feature that was released as a feature for Scale Out Backup Repository (SOBR) in Ve...
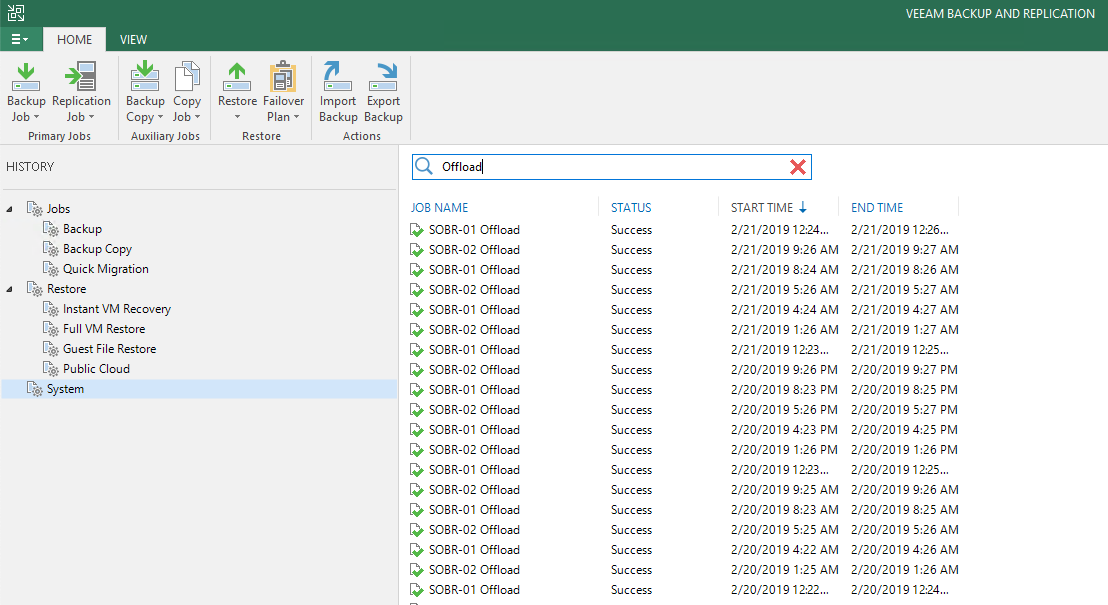
With the release of Update 4 for Veeam Backup & Replication 9.5 we introduced the Cloud Tier, which is an extension of the Scale Out Backup Repository (SOBR)...