
Veeam Backup & Replication v12.2: Key Features & Enhancements
This week, Veeam made Generally Available Veeam Backup & Replication v12.2 ( Build 12.2.0.334 ), continuing the innovation of our core platform with a signif...
Tag
196 posts
This week, Veeam made Generally Available Veeam Backup & Replication v12.2 ( Build 12.2.0.334 ), continuing the innovation of our core platform with a signif...
In the latest episode of the Great Things with Great Tech podcast, we delve into the challenges of IT management in today's fragmented channel. We explore ho...

I haven't done one of these blog posts for a while, but in the lead up to VeeamON in a couple weeks, as we look ahead to what's coming we haven't taken our e...

We are well into 2024 now, with January all but done and dusted... but before we really dive into 2024, let's take a look ahead as we move forward into what ...

Those that know me and have followed my career understand that I've lived and breathed the Cloud and Service Provider space for more than twenty years. In th...

Last week, with the release of the RTM of Veeam Backup & Replication v12 we also released Veeam Service Provider Console v7 (7.0.0.12777) . Veeam continues f...

Today, Veeam made available to our VCSP partners the RTM of Veeam Backup & Replication 12 (Build 12.0.0.1402). It actually feels like it's been a while betwe...

NOTE: The following content was transcribed and modified from the Thoughts on X podcast…Click Play if you would like to listen. I think we should all put a p...

While at AWS re:Invent 2022 I had some great conversations with a mix of old and new Managed Service Providers who are focusing on delivering services for wo...

Over my now twenty plus year career in IT, i've been very fortunate to be around technical innovation from all sides of the technology fence. Working in the ...
I've said this more than a few times... but I wouldn't be where I am today without the Veeam Vanguard program. As a former Veeam Vanguard, I know the value o...

I must say... it was good to be back at the Mascone Center and San Francisco for VMware Explore 2022. Some people might question my excitement at getting bac...

It's crazy to thing that it had been almost three full years between VeeamON mainstage sessions...but the pandemic did keep the Product Strategy Team offstag...

It's less than one week away from VeeamON 2022 and yes... I am bloody excited! Things are shaping up really well from a behind the scenes point of view and t...

With the release of Veeam Backup for Microsoft 365 v6 , we brought to market one of the most heavily requested features across all products at Veeam. That is...

Great news this week, with the GA release of Veeam Backup for Microsoft 365 (VBM) version 6.0 ( 6.0.0.367 ). This new version again builds on the 5.0 release...
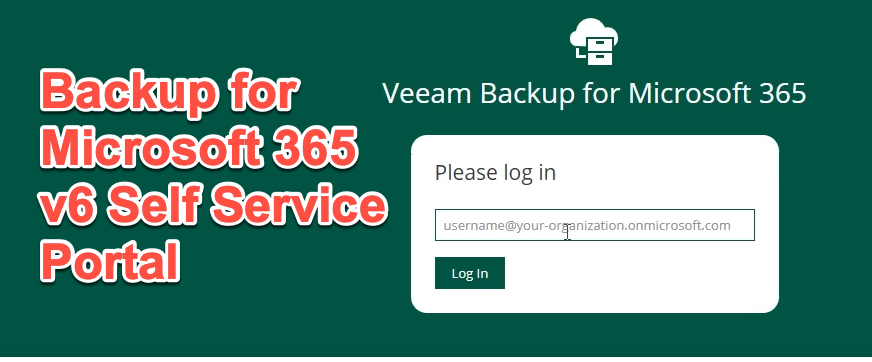
No doubt that one of the biggest requests for our Backup for Microsoft 365 product since it was released has been the desire for user driven self service res...
What can I say...it's been a long time between drinks and looking back on the past couple of years it's certainly been a frustrating time for us in the tech ...
This is a quick post to highlight the updated release build (version 1.1.11 ) of Veeam Backup for Red Hat Virtualization (RHV) that was released a few weeks ...

Cloud Field Day 12 has come and gone...and for the third time virtually, I had the pleasure of presenting to the delegates. This time around it was the first...

At VeeamOn Update overnight we announced that Veeam Backup for Salesforce would be our next SaaS backup product, with intentionality to release some time in ...

VMworld 2021 is today! This year, once again we will all be experiencing the conference remotely and a little more delayed than is usual for VMworld (US). Wi...

Overnight, we released v11a ( Build 11.0.1.1261 ) of our flagship product, Veeam Backup & Replication. This is the first major update to v11 which was releas...

Continuous Data Protection (CDP) is a technology that has been around for a while. Lots of companies have looked to leverage it within their products and, as...
Cloud Field Day 11 was held a couple weeks back...and while this time around I was not presenting, I still wanted to give a round up of the event from a Kast...

When Veeam Backup & Replication v11 went Generally Available on the 24th of February I posted the What’s in it for Service Providers blog. In that post I bri...

VeeamON has come and gone for another year but for those that might not have been able to virtually attend last week, the VeeamON Virtual Online Platform wil...

At VeeamON 2021 we made a significant new product announcement which was the unveiling of Veeam Backup for Red Hat Virtualization. While this might not be th...

VeeamON is kicking off this week and once again an online event for the second year in a row. It still pains me that we can not be doing this event in person...
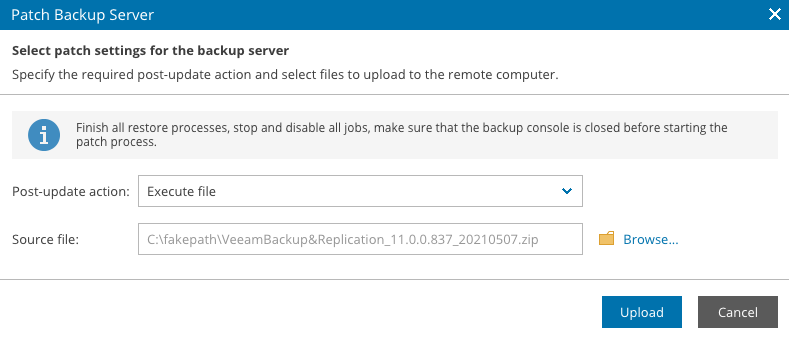
Overnight we released a new patch release (Build P20210507 ) for Veeam Backup & Replication v11. This is actually quite a big patch release and contains a nu...

When Veeam Backup & Replication v11 went Generally Available on the 24th of February I posted the What’s in it for Service Providers blog. In that post I bri...

The only thing hotter than Kubernetes at the moment is Crypto. While the price of BitCoin takes centre stage for the most, there is so much more behind this ...
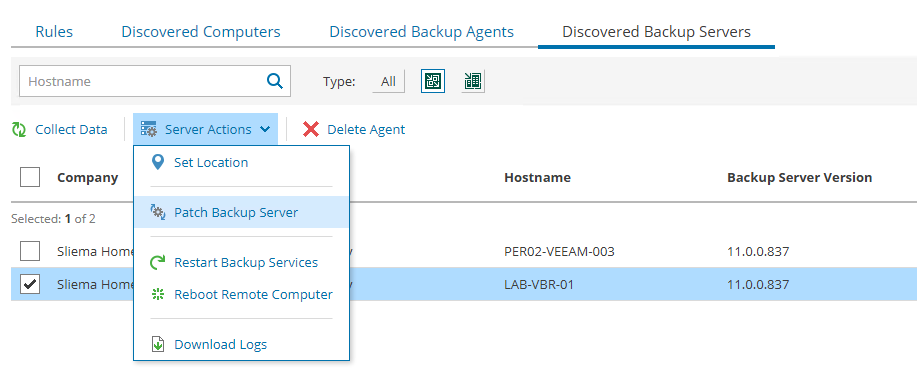
One of the cooler features to come out as part of the Veeam Service Provider Console (Console or VSPC) v5 is the ability to remotely patch Veeam Backup & Rep...

Before I joined Veeam I spent all my career working for service providers. I spent my first 7 years working for a hosting provider working on Windows and Lin...
This is a very very quick post to highlight that earlier this week we released v5b of Veeam Backup for Microsoft Office 365 ( Build 5.0.1.225 ) mainly to add...

When Veeam Backup & Replication v11 went Generally Available on the 24th of February I posted the What’s in it for Service Providers blog. In that post I bri...
Cloud Field Day 10 has come and gone...and for the third time, I had the pleasure of presenting to the assembled delegates.. Again, while it was a different ...

In early February we released the RTM Build of Backup & Replication v11 to our Cloud and Service Provider partners. This was to ensure that any keen early ad...

Last week, with the release of Veeam Backup & Replication v11 we also released Veeam Service Provider Console v5 (Latest build 5.0.0.6838) . Veeam remains fo...

This week we officially launched v11 of Veeam Backup and Replication along with Veeam ONE, Service Provider Console and updated Veeam Agents for Windows, Lin...

Today Veeam made Generally Available Veeam Backup & Replication 11 ( Build 11.0.0.837 ) and with it comes over 150+ anticipated new features and enhancements...

Hard to believe we are on the cusp of another major Veeam Backup & Replication release! Seems like it was only a short time ago that we were doing this for v...
Last week the RTM of Veeam Backup & Replication v11 was released. With it also came the RTM of Veeam Service Provider Console v5. I wanted to give a quick ov...
Overnight, Veeam made available to our VCSP partners the RTM of Veeam Backup & Replication 11 (Build 11.0.0.825). Seems like only yesterday v10 was released,...
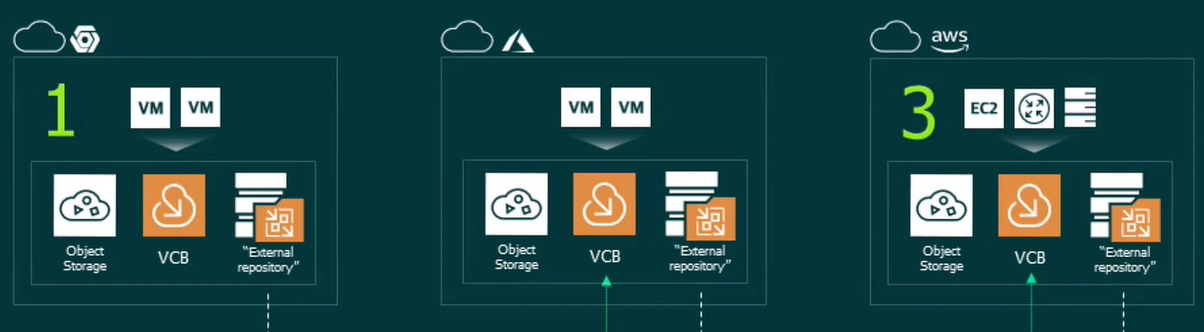
Since version 9.5 Update 4 of Veeam Backup & Replication we have had support to firstly move, then copy ( as part of v10 ) backup data from what is, traditio...

Over the past few days I've been working on prepping my old 2014 Mac Book Pro for trade in for a new Mac Mini M1. I've had this trusty MBP since 2014 and was...

A Challenging Year for Community For a lot of us in the IT Industry, 2020 made it difficult to advocate technology like we had done in previous years. No dou...
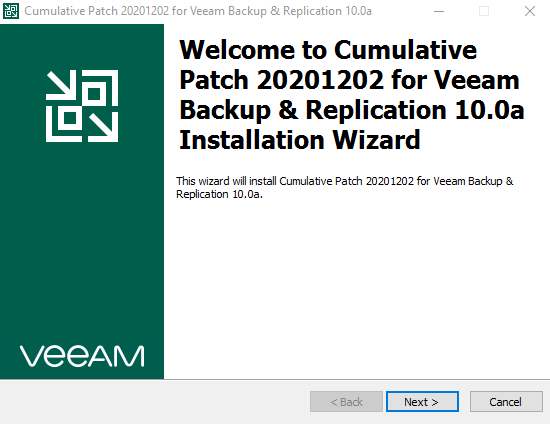
Yesterday, Veeam made available Cumulative Patch 3 for Veeam Backup & Replication 10a ( build 10.0.0.4854 P20201202 ). This is the third cumulative patch for...

Veeam acquired Kasten last month and for those that maybe wondering why a lot of us internal to Veeam are super excited about this taking place I thought I w...
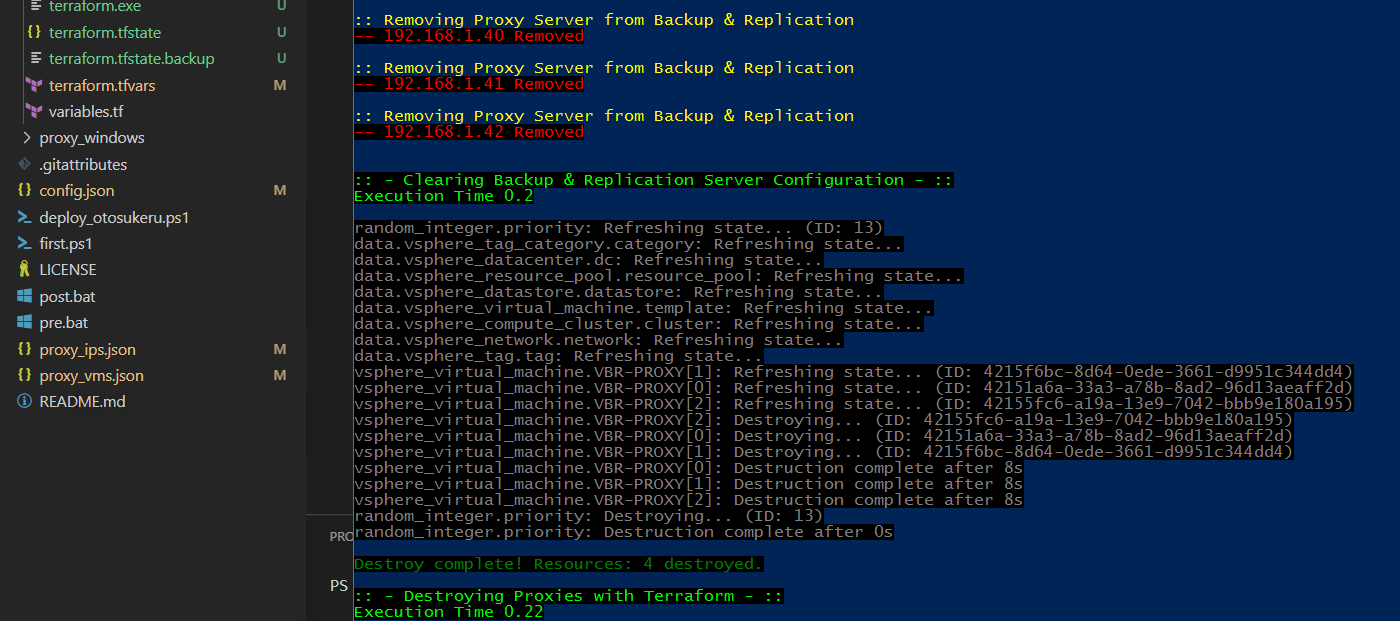
HashiConf took place a couple of weeks ago now, and during the event I presented a community based Lightning Talk live. The session is based on using Infrast...

We have one more to go! One more Major Veeam Virtual Event for the year and we have worked hard to ensure that even with all the virtual fatigue, Veeam Live ...

Today Veeam has acquired Kasten . This acquisition is focused on offering a pathway to achieving a multi-platform backup strategy leveraging both data protec...

VMworld has been leveraged by a lot of people to help advance their careers with a lot of advancement seeded by personal interactions at the conference. Soci...

VMworld 2020 is now only a couple of days away, and this year we will all be experiencing the conference remotely. Without question this will be a different ...

We always talk about starting with backup... and it is true that you can't recover unless you have a solid backup, however more and more the recovery of work...
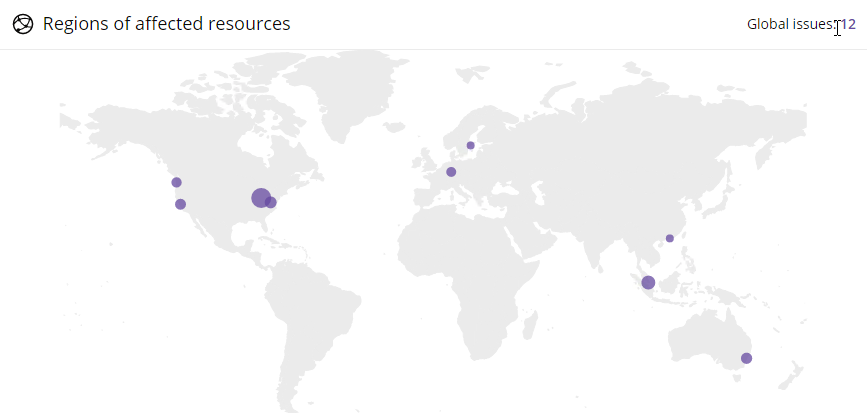
Back when I first started using AWS in 2010 I had a couple of EC2 instances running across a few regions for some web hosting clients I was managing at the t...
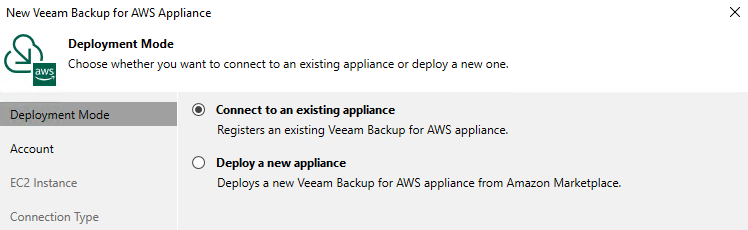
As mentioned my post yesterday, Veeam Backup & replication v10a has been released . One of the more significant new features of the release was the new AWS P...

Over the weekend, we released the v10a ( Build 10.0.1.4854 ) release of our flagship product, Veeam Backup & Replication. This is the first major update to v...
Cloud Field Day 8 has come and gone...it always amazes me the amount of preparation leading up to these events. We take them very seriously and while it was ...
I'm currently sitting in my home office in Perth, Western Australia...a stark contrast to where I have written my previous Cloud and Tech Field Day lead up p...
In todays application centric world, upgrading software has almost become a non-event. We have gotten used to instant upgrades that just work without having ...

VMware still represents a strong focus for the foundation of our core platform supportability. VMware workloads are still easily the most protected workloads...

During the VeeamON 2020 Technical Session we previewed new features and enhancements across our platform. I posted a quick review covering the platform updat...

VeeamON has come and gone for another year but for those that might not have been able to virtually attend last week, the VeeamON Virtual Online Platform wil...

VeeamON (Live) is happening next week and while we should have already been done and thinking about next years 2021 event after the completion of a successfu...

Today, Veeam made available Patch 2 for Veeam Backup & Replication 10 ( Build 10.0.0.461 P2 ). This is the second cumulative patch for v10 and contains a num...

Yesterday Veeam and Kasten announced a strategic partnership focused on offering a pathway to achieving a multi-platform backup strategy levering both data p...
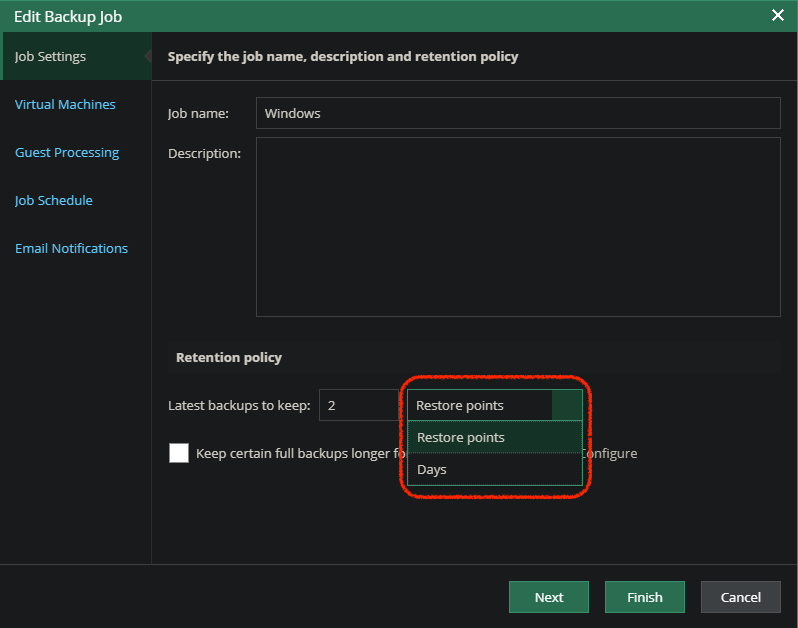
The Data Integration API is one of my favourite features that was released in v10 . This isn't only because it builds on existing technologies contained with...
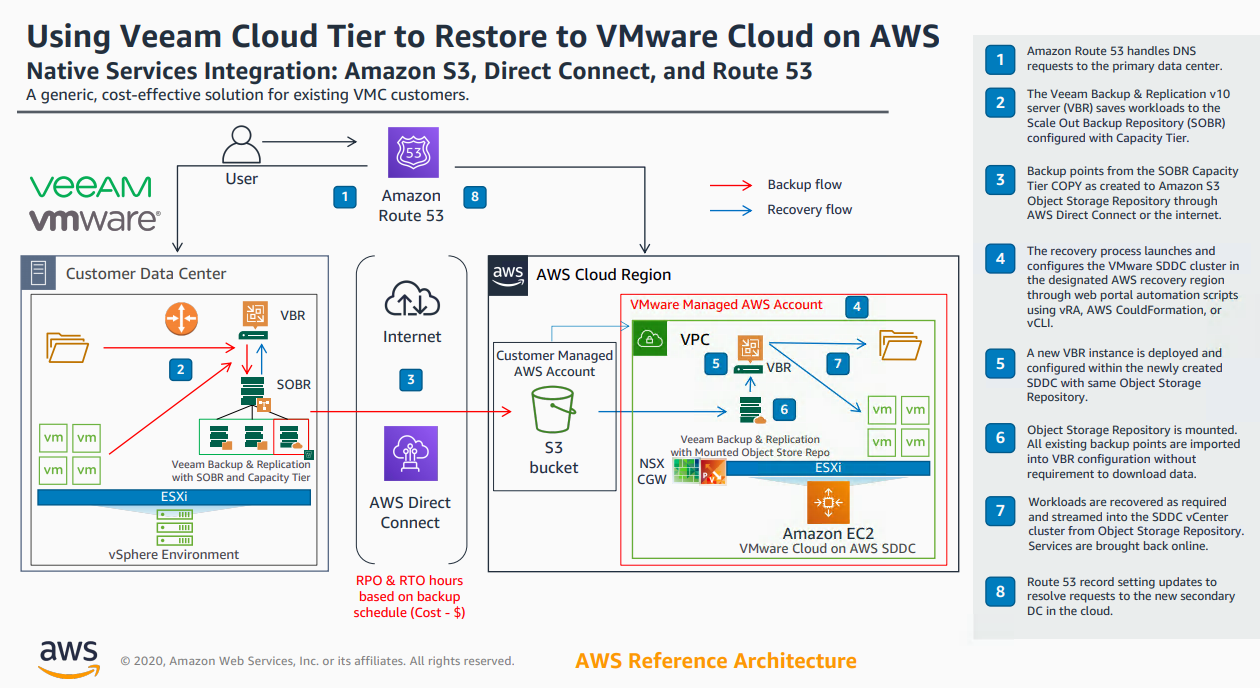
With the release of v10 of Backup & Replication came significant enhancements to the Cloud Tier. As I wrote about here , we introduced Copy Policy , Immutabi...

Veeam Backup & Replication v10 has been Generally Available since mid Feburary and last week I posted a What’s in it for Service Providers overview blog post...

In early Feburary we released the RTM Build of Backup & Replication v10 to our Cloud and Service Provider partners. This was to ensure that any keen early ad...

True innovation is solving a real problem ...and though for the most, it's startups and tech giants that are seen to be the innovators, their customers and p...
Yesterday we officially launched v10 of Veeam Backup and Replication along with Veeam ONE and updated Veeam Agents for Windows and Linux. We had a live launc...
Today Veeam made Generally Available Veeam Backup & Replication 10 (Build 10.0.0.4416) and with it comes over 150+ anticipated new features and enhancements....
Version 10 of Veeam Backup & Replication right around the corner as we rapidly approach GA. The RTM has been out for our service provider partners for a coup...

Late last week, Veeam made available to our VCSP partners the RTM of Veeam Backup & Replication 10 ( Build 10.0.0.4442 ). This is a much awaited version of B...
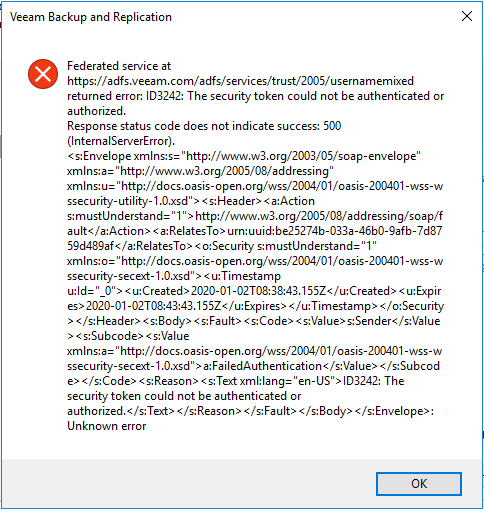
Multi Factor Authentication is pretty much standard now when it comes to accessing online accounts and most companies have implemented MFA for their employee...

Over the last few years the amount of CBT related issues has decreased significantly from VMware. I remember back in my previous roles of having to deal with...
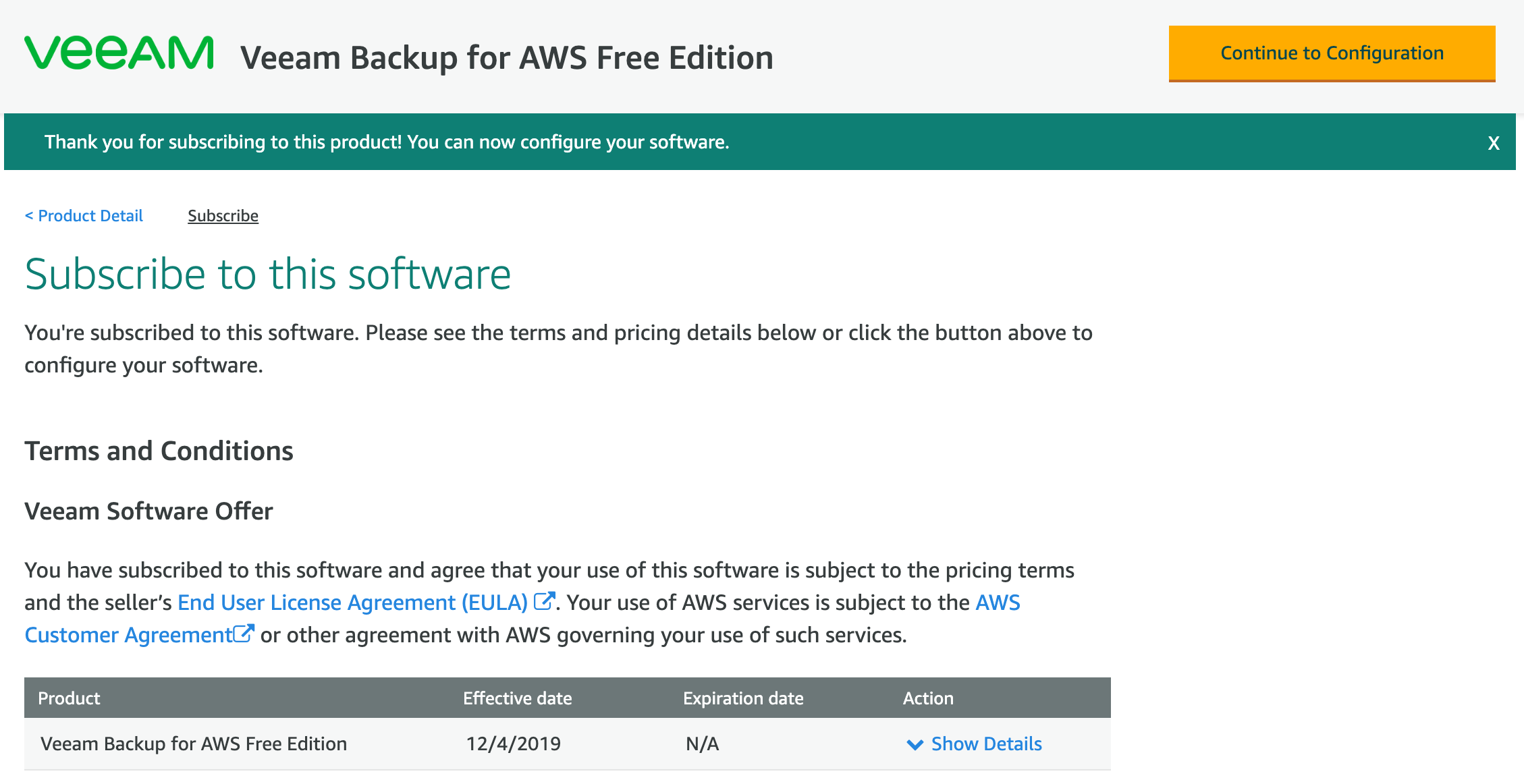
This week at AWS re:Invent, exciting news for a lot of us in Veeam was announced as we made available for GA Veeam Backup for AWS ( Build 1.0.0.1345 ). Avail...

A couple of days ago we snuck out a minor update to Veeam Powered Network (Veeam PN) bringing the version up to 2.1 (Build 2.1.0.461). We released 2.0 back i...

Yesterday, Veeam Backup for Microsoft Office 365 (VBO) version 4.0 ( 4.0.0.1345 ) went GA. This new version again builds on the 3.0 release that enhanced ove...

Tech Field Day 20 has come and gone, and it was an honour to play a small part in the 10th year anniversary Tech Field Day event. This was my second TFD even...
Yesterday I presented at Tech Field Day 20. My first topic was on the enhancements we are bringing to Cloud Tier in our Backup & Replication v10 release. Ric...
I'm currently sitting in my hotel room in sunny sunny San Jose. Today and tomorrow will be spent finishing off preparations for Tech Field Day 20 . This will...
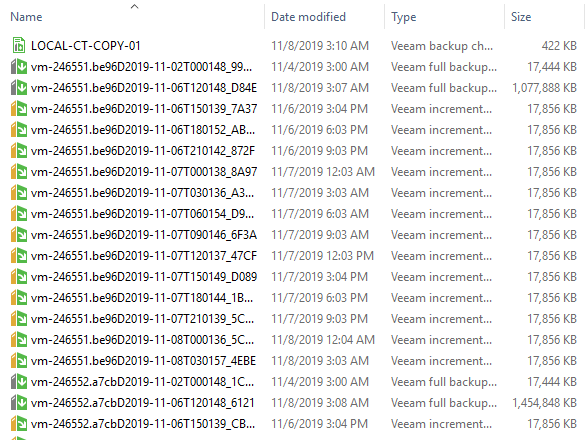
Version 10 of Veeam Backup & Replication isn't too far away and we are currently in the middle of a second private BETA for our customers and partners. There...

Overnight at Microsoft Ignite, we announced availability of the Public Beta for the next version of Veeam Backup for Microsoft Office 365. This is again a mu...
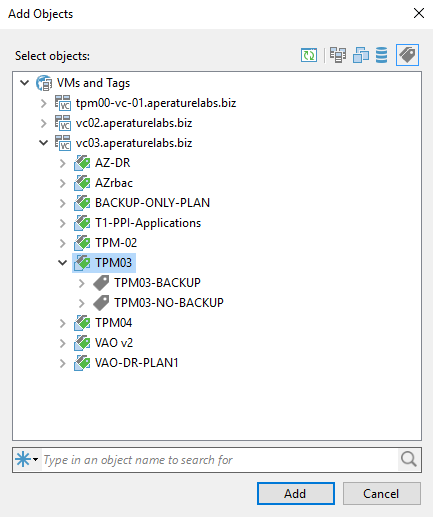
vSphere Tags are used to add attributes to VMs so that they can be used to help categorise VMs for further filtering or discovery. vSphere Tags have a number...

VMworld 2019 is almost a distant memory, and with the focus now shifting to VMworld Europe happening later in the year I wanted to round out the US event wit...

VMworld 2019 is now only a couple of days away, and I can't wait to return to San Francisco for what will be my seventh VMworld and third one with Veeam. It ...

VMworld is rapidly approaching, and for those that have not secured their place at the event in San Francisco, and for whatever reason have been hindered in ...
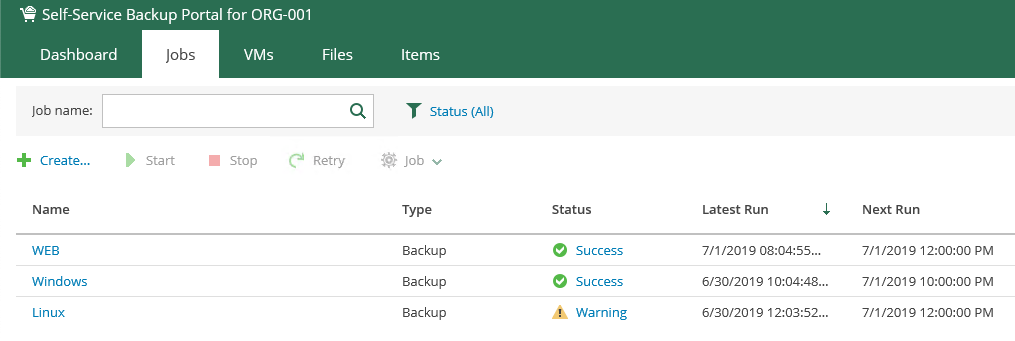
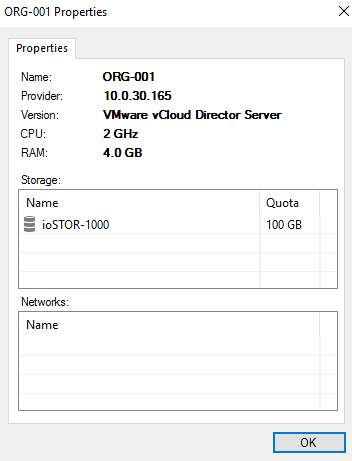
Since version 7 of Backup & Replication , Veeam has lead the way in regard to the protection of workloads running in vCloud Director. With version 7 Veeam fi...
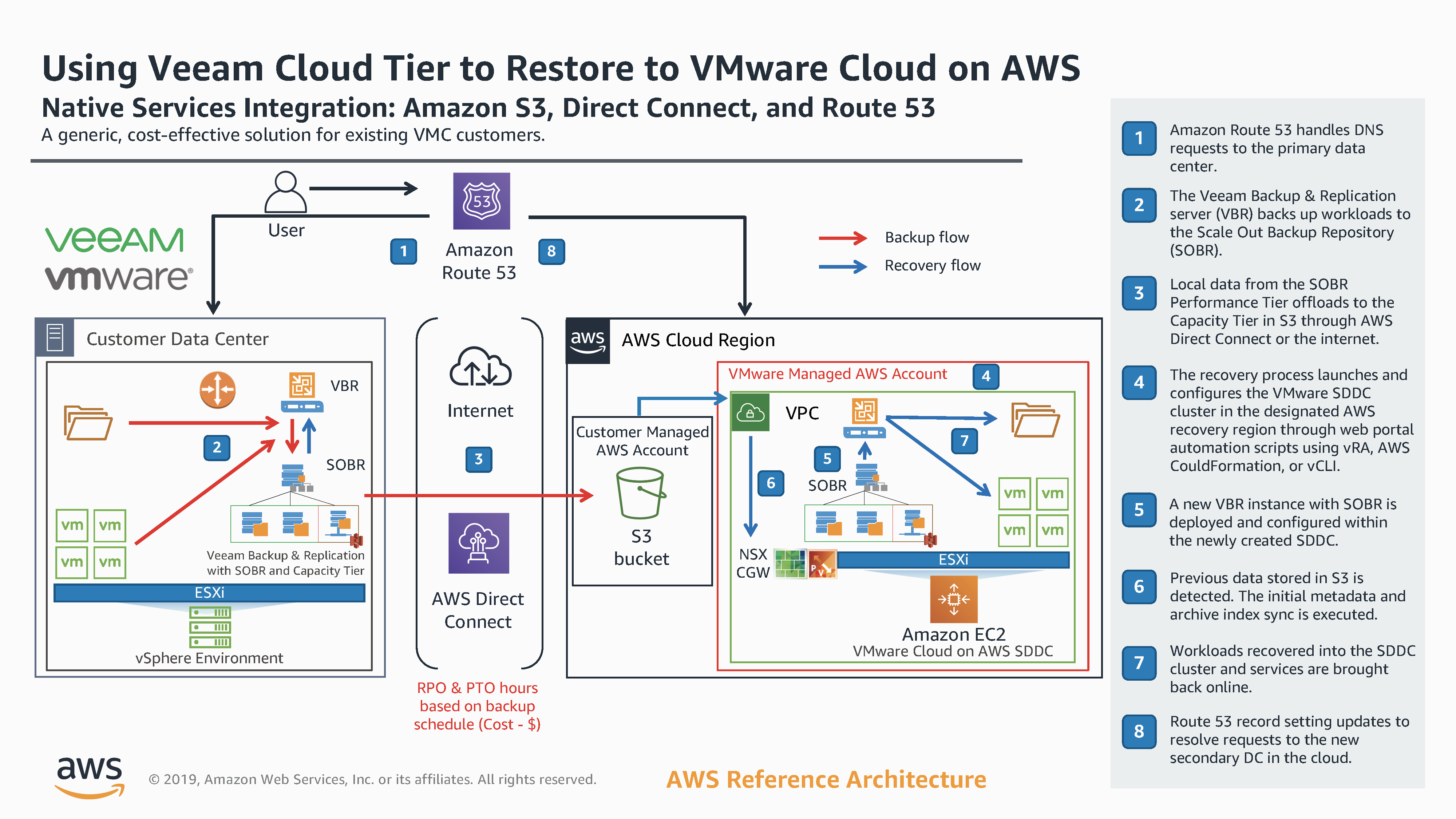
Since Veeam Cloud Tier was released as part of Backup & Replication 9.5 Update 4 , i've written a lot about how it works and what it offers in terms of offlo...
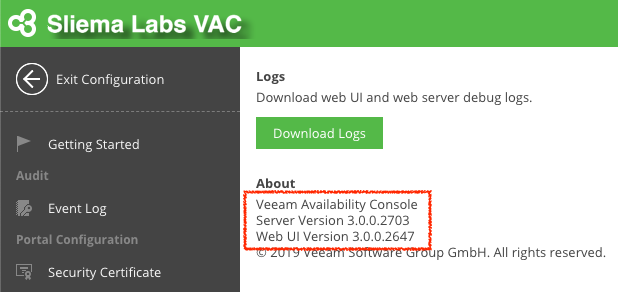
Today, a new patch was released for Veeam Availability Console v3 which brings the build to 3.0.0.2725 . Contained in this patch is a number of fixes that co...
Last week at VeeamON 2019, Dustin Albertson and myself delivered a two part deep dive session on Cloud Tier, which was released in Update 4 of Veeam Backup &...

Hard to believe that another VeeamON has come and gone… for us in the Product Strategy Team the lead up and the event itself is immensely busy, but this is w...

VeeamON is happening next week and the final push towards the event is in full swing. I can tell you that that this years event is going to be slightly diffe...
I'm currently on the first leg over from Perth to San Fransisco where I'll head down to Silicon Valley to present at Cloud Field Day 5 . This will be my firs...

Yesterday Update 4a for Veeam Backup & Replication 9.5 ( Build 9.5.4.2753 ) was made available for download to all Veeam customers and partners. This build u...
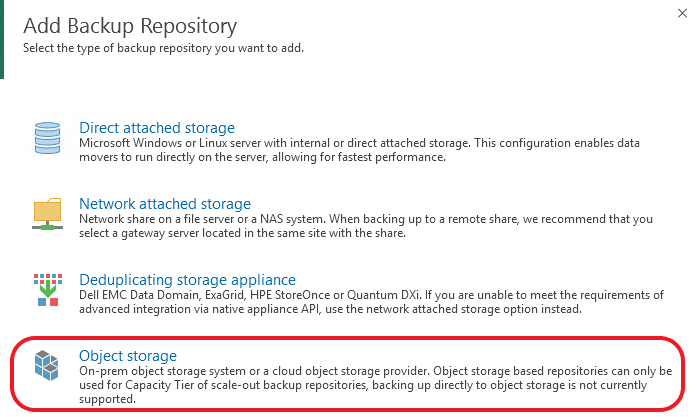
When Veeam Backup & Replication 9.5 Update 4 went Generally Available in late January I posted a What’s in it for Service Providers blog. In that post I brie...

A few years ago I claimed that the Melbourne VMUG Usercon was the “Best Virtualisation Event Outside of VMworld!” …that was a big statement if ever there was...
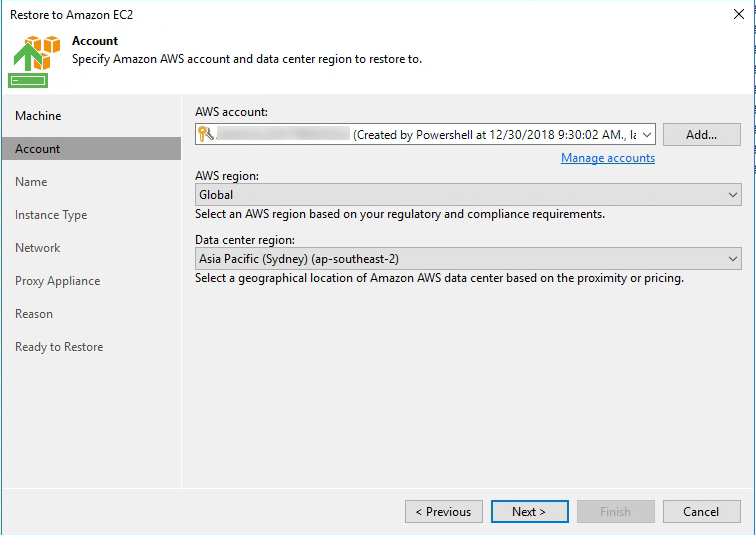
When Veeam Backup & Replication 9.5 Update 4 went Generally Available a couple of weeks ago I posted a What’s in it for Service Providers blog. In that post ...
With the release of Update 4 for Veeam Backup & Replication 9.5 we further enhanced our overall cloud capabilities by adding a number of new features and enh...
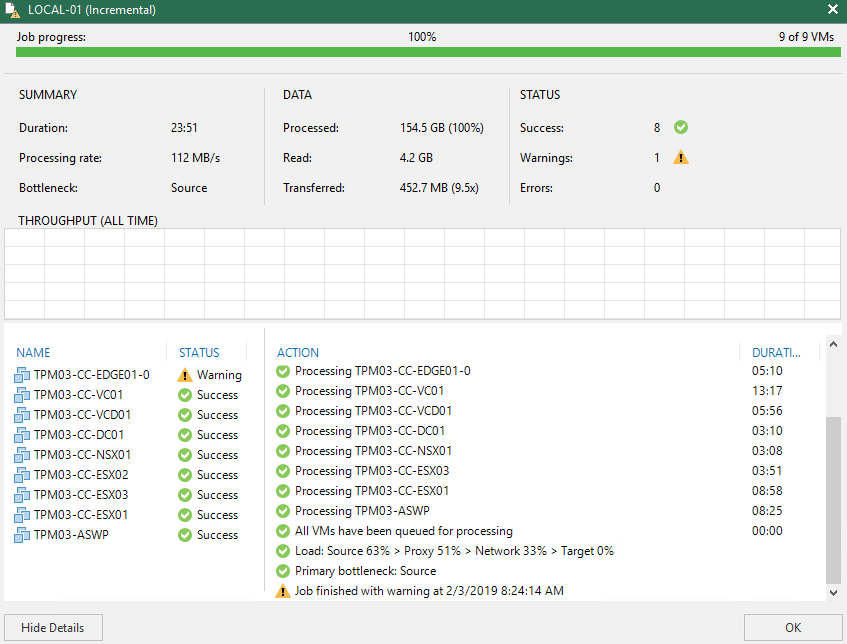
Recently I was sent a link to a video that showed an end user comparing Veeam to a competitors offering covering backup performance, restore capabilities and...

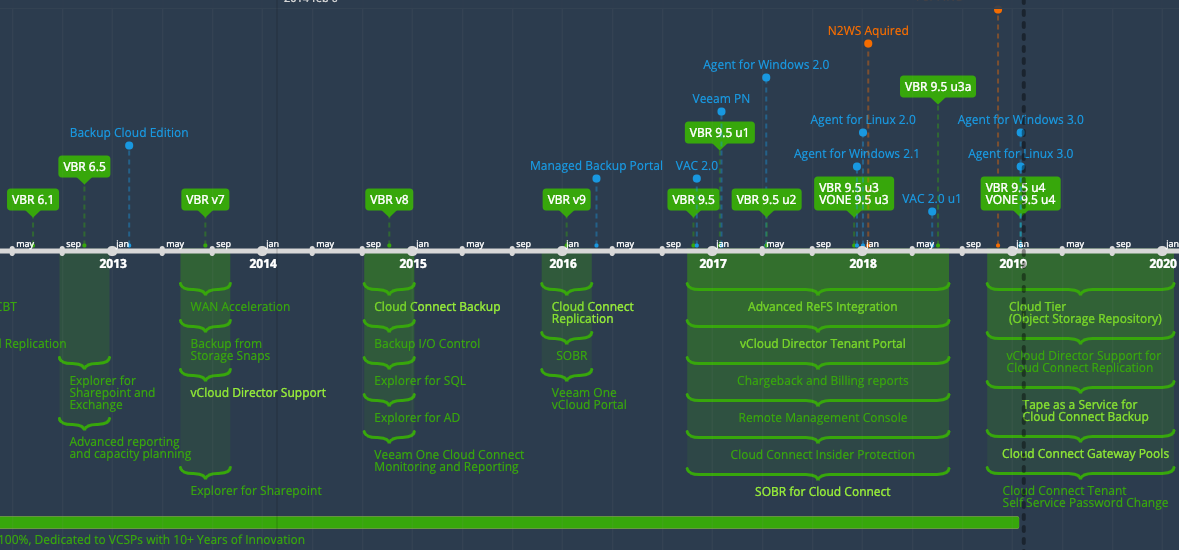
For ten plus years Veeam has continued to develop new innovative features and enhancements supporting our Cloud and Service Provider partners. As I posted ea...
I remember the day I first came across Veeam. It was mid 2010 and I was working for Anittel at the time. We had a large virtualisation platform that hosted a...
Yesterday we officially launched Update 4 for Veeam Backup & Replication 9.5 along with Veeam ONE and updated Veeam Agents for Windows and Linux. We had a li...

This time next week we will be well into Veeam Velocity 2019 . In previous years, this event acts as our global sales kick off however this year we have inco...

Today, Veeam has made available to our VCSP partners the RTM of Update 4 for Backup & Replication 9.5 ( Build 9.5.4.2399 ). Update 4 is what we term a breaki...
Things are moving here at Veeam with the impending release of Veeam Backup & Replication 9.5 Update 4. In preparation for the release there have been a numbe...
This year was my second full year working for Veeam and my role being global, requires me to travel to locations and events where my team presents content an...
There was so much to take away from AWS re:Invent last week . In my opinion, having attended a lot of industry events over the past ten or so years, this yea...

This week, myself and David Hill presented at AWS re:Invent 2018 around what at Veeam is offering by way of providing data protection and availability for na...
AWS re:Invent 2018 is happening next week and for the first time Veeam is at the event in a big way! Last year, we effectively tested the waters with a small...

Last week we snuck out an important cumulative patch for Veeam Backup for Office 365 v2 bring the build number up to 2.0.0.567 . The patch is actually fairly...
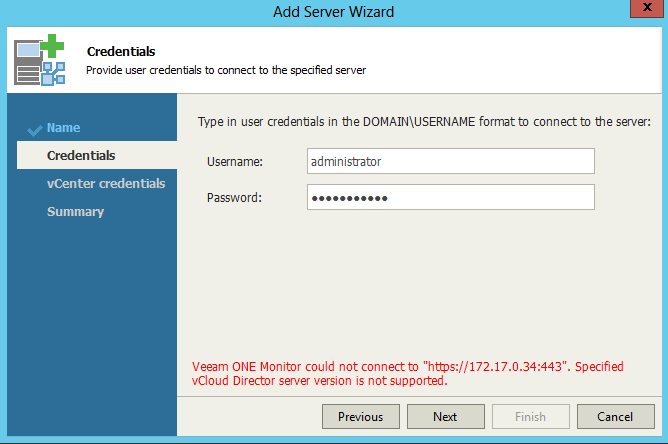
Back in May when VMware released vCloud Director 9.1 they also depreciated support for a number of older API versions: End of Support for Older vCloud API Ve...

As part of the Veeam Automation and Orchestration for vSphere project myself and Michael Cade worked on for VMworld 2018 , we combined a number of seperate p...
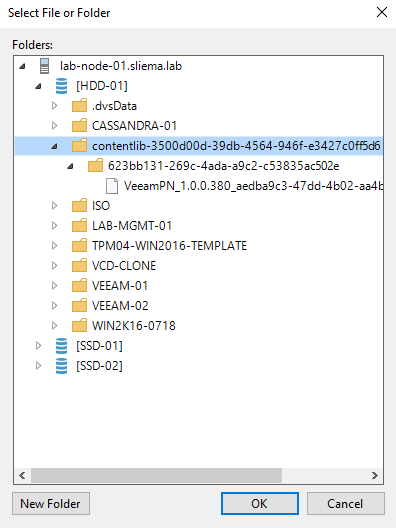
A question came up in the Veeam Forums this week about how you would backup the contents of a Content Library. As a refresher, content libraries are containe...
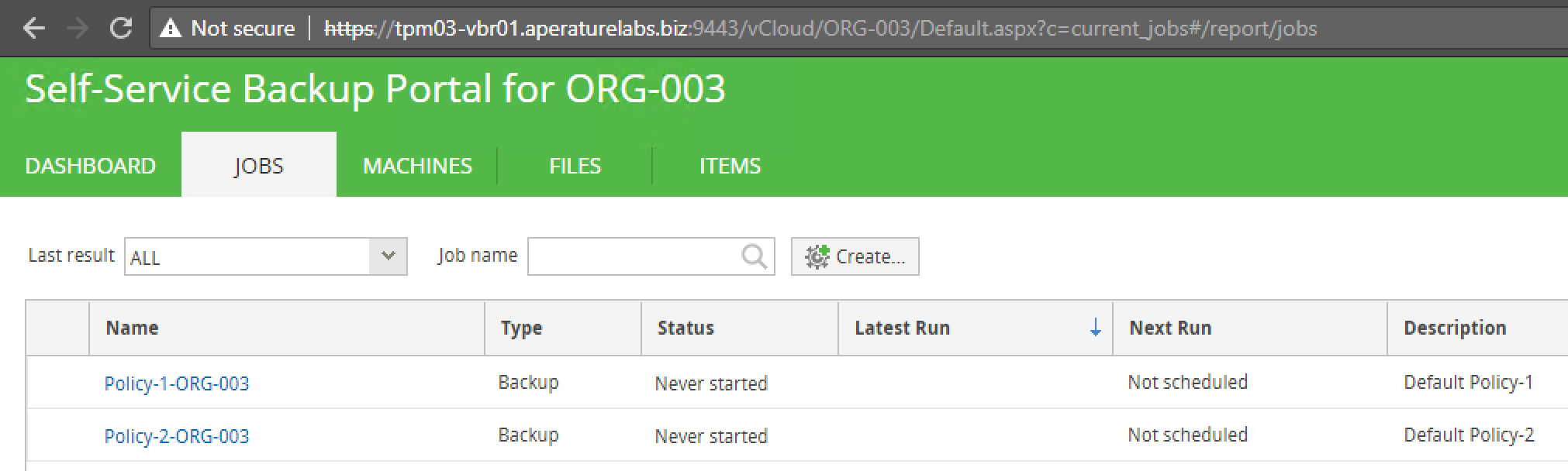
For a long time Veeam has lead the way in regard to the protection of workloads running in vCloud Director. Veeam first released deep integration into vCD ba...
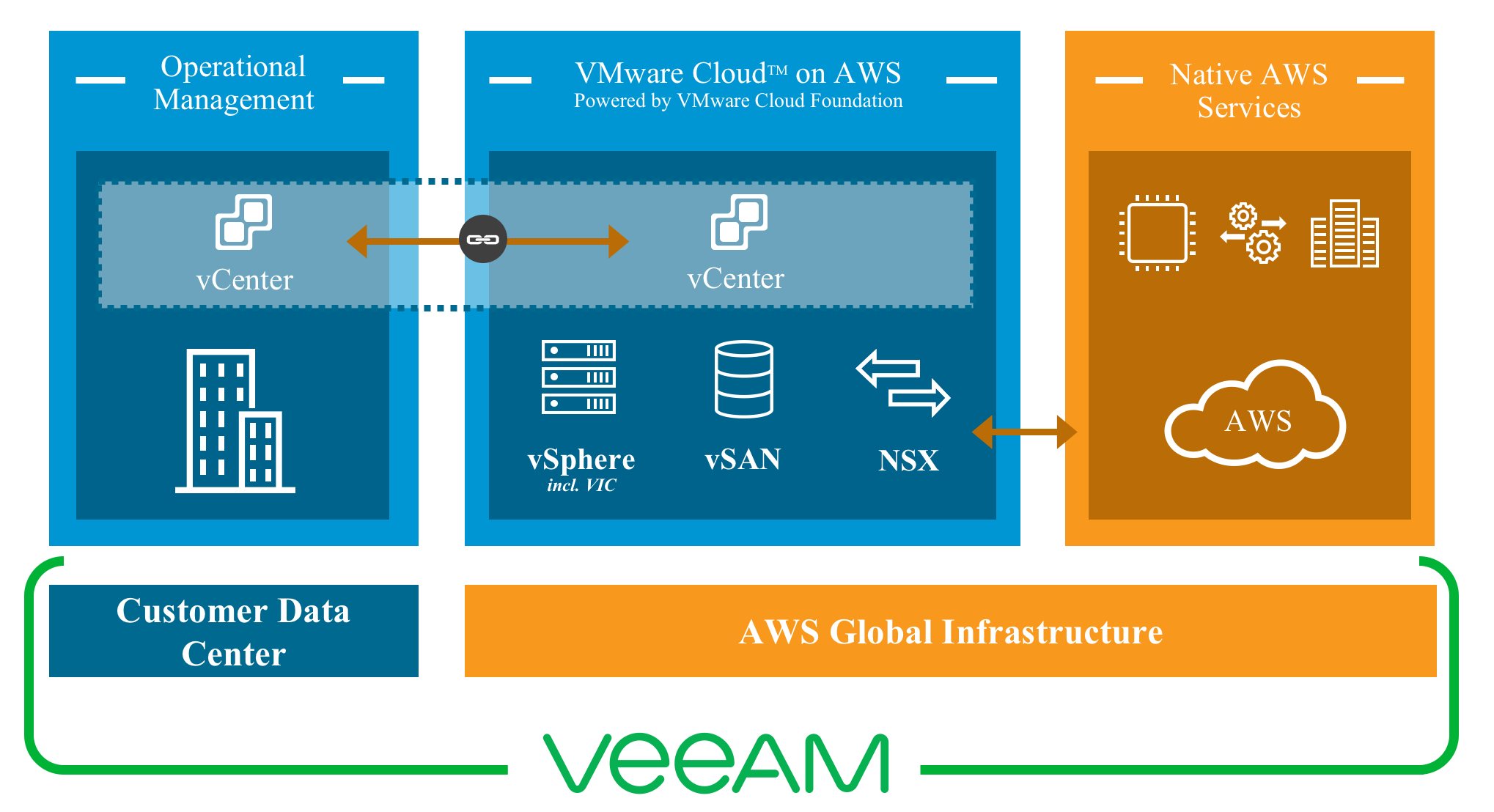
At VMworld 2018, myself and Michael Cade gave a session on automating and orchestrating Veeam on VMware Cloud on AWS . The premise of the session was to show...

VMworld 2018 has come and gone and after a couple of days recovery from the week that was, i’ve had time to reflect on what was a great week and an another g...

VMworld 2018 is less than a week away, and I can't wait to fly into Las Vegas for my sixth VMworld and second with Veeam. It's been an interesting year or so...
Earlier this month a patch was released for Veeam Availability Console 2.0 Update 1 . Contained in the list of fixes is an important note about those that ma...
Back in April, I was lucky enough to present at the AWS Summit in Singapore . The session was a joint one with Alex Thomson from N2WS on how Veeam and N2WS a...
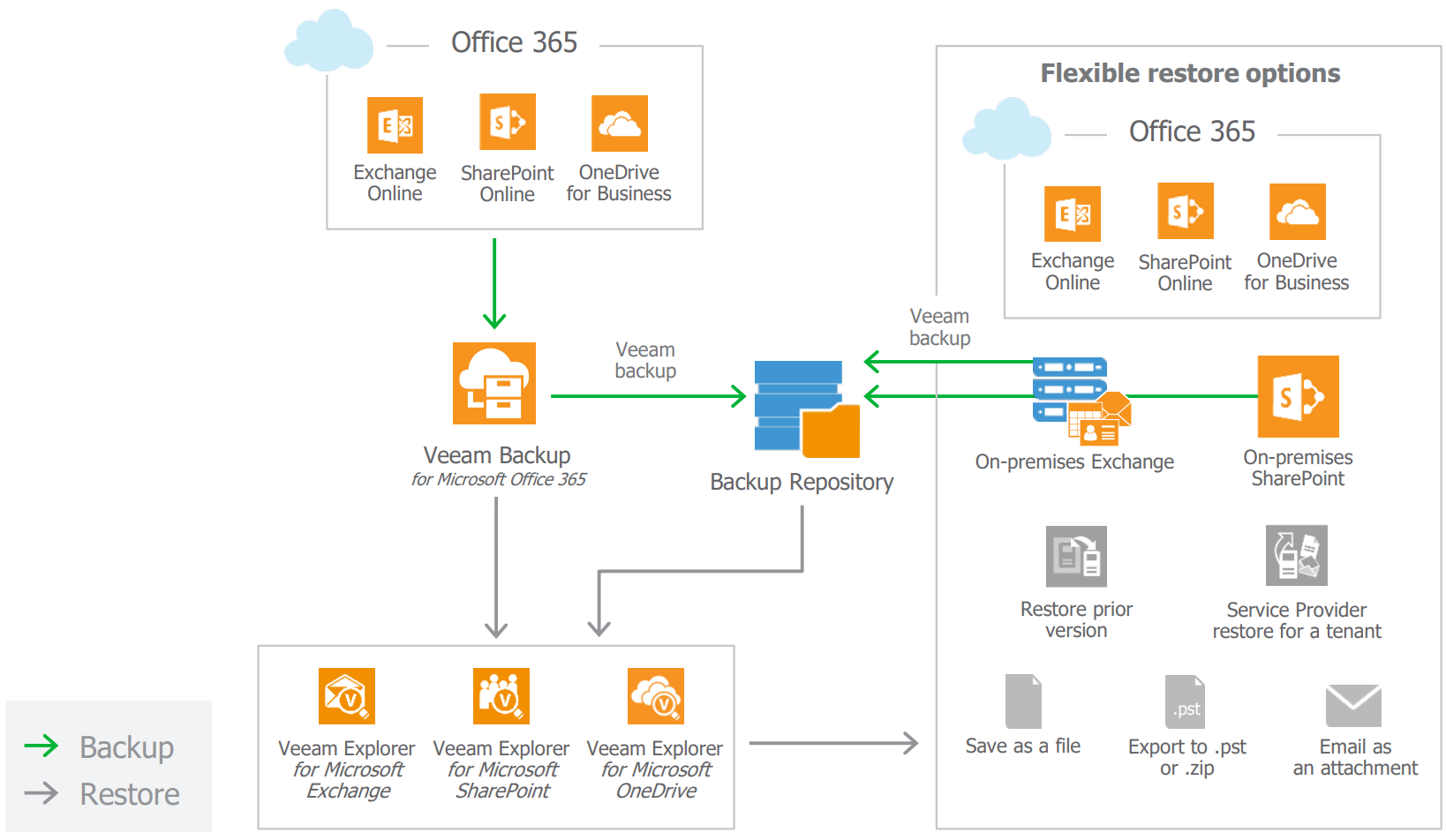
Last week the much anticipated release of Veeam Backup for Office 365 version 2.0 ( build 2.0.0.567 ) went GA. This new version builds on the 1.5 release tha...

Back in May, we held VeeamON in Chicago where we launched Veeam’s vision and strategy to lead the way in intelligent data management. One of the great things...

Earlier this week Update 3a ( Build 9.5.1922 ) for Veeam Backup & Replication was made generally available. This release doesn’t contain any major new featur...
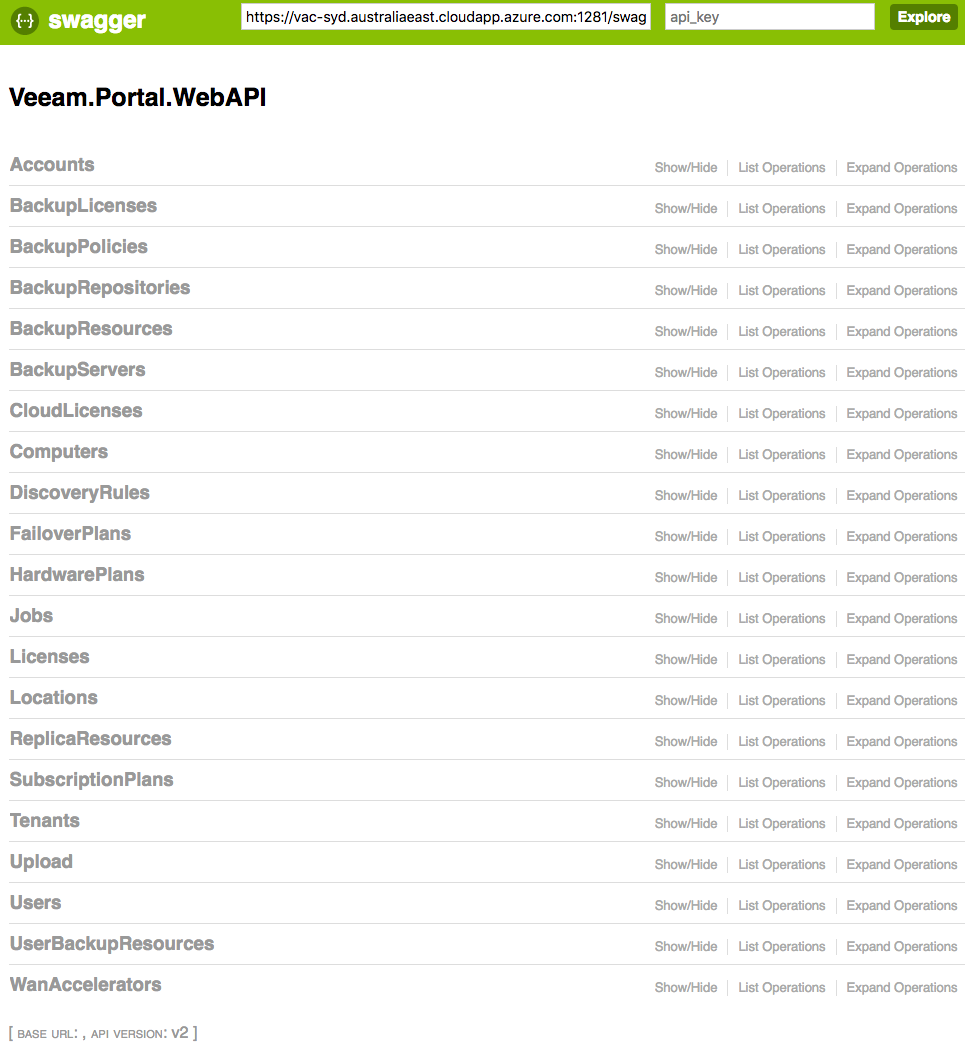
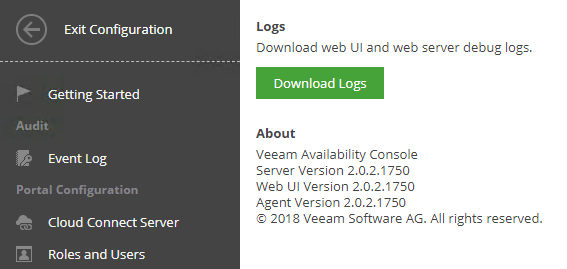
Today, Veeam Availability Console Update 1 (Build 2.0.2.1750) was released . This update improves on our multi-tenant service provider management and reporti...
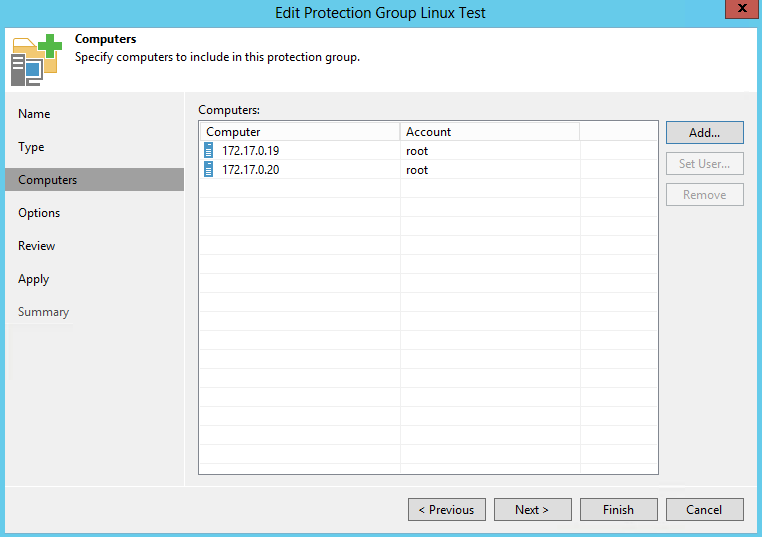
With the release of Update 3 of Veeam Backup & Replication we introduced the ability to manage agent from within the console. This was for both our Windows a...
A month of so ago I wrote a post on deploying Veeam Powered Network into an AWS VPC as a way to extend the VPC network to a remote site to leverage a Veeam L...
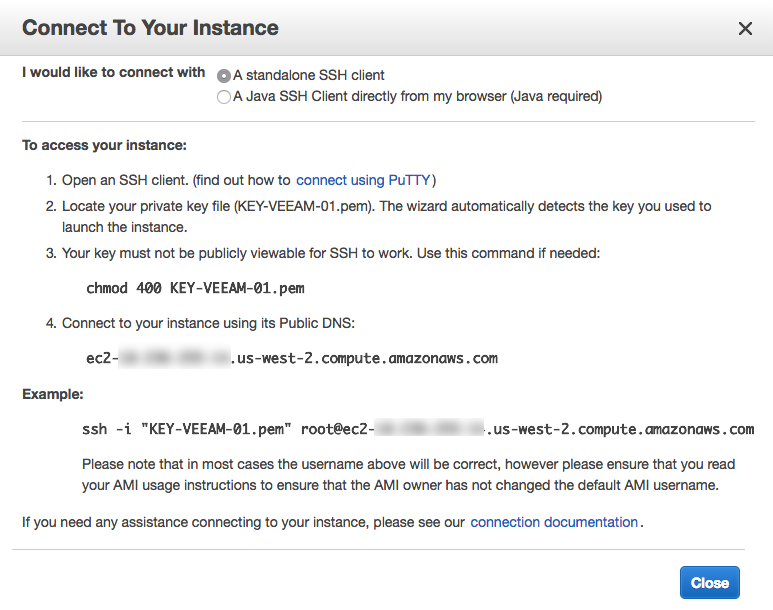
I've been doing a little more within AWS over the past month or so related to my work with VMware Cloud on AWS and the setting up of EC2 instances to use as ...
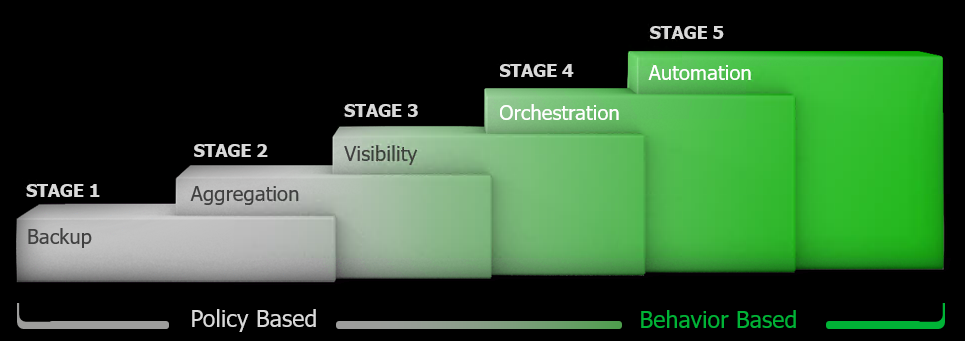
VeeamON has come an gone for another year and it is an exciting time to be in the (hyper) availability industry. There has been a significant shift in the wa...
Yesterday I posted an article highlighting my top picks for VeeamON 2018 . The one thing I didn't list in that post was my own sessions for this years event....

VeeamON is happening next week and the final push towards the event is in full swing. I can tell you that that this years event is going to be extremely valu...
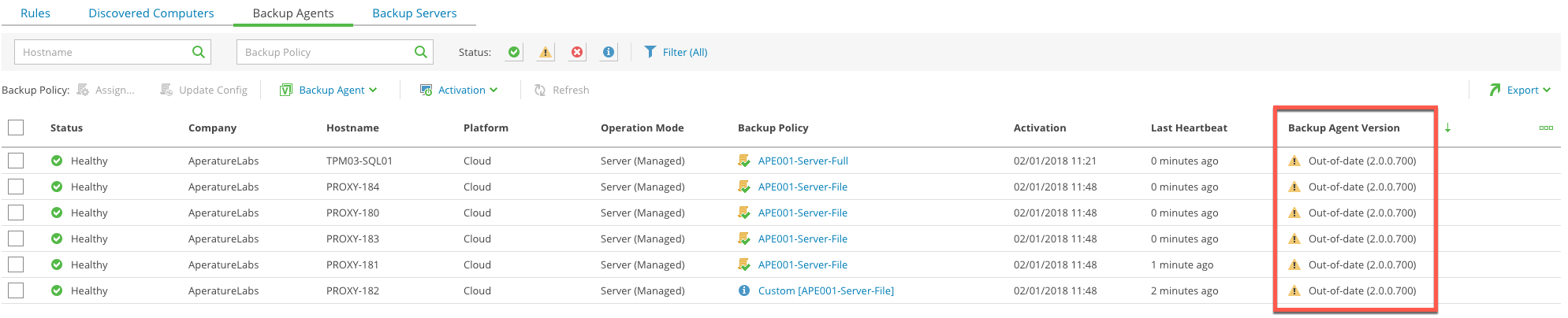
One of the Veeam Availability Console's key features is it's ability to deploy and manage Veeam Agent for Windows. This is done through the VAC Web Console a...

True innovation is solving a real problem ...and though for the most, it's startups and tech giants that are seen to be the innovators, their customers and p...
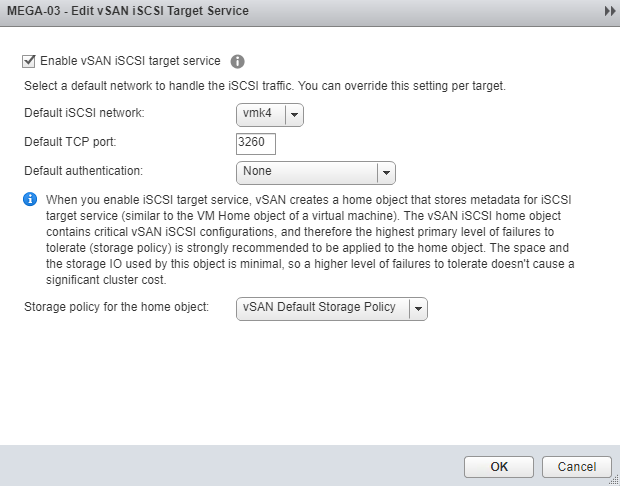
Probably one of the least talked about features of vSAN is it's ability to serve out iSCSI volumes. The feature was released with vSAN 6.5 and was primarily ...
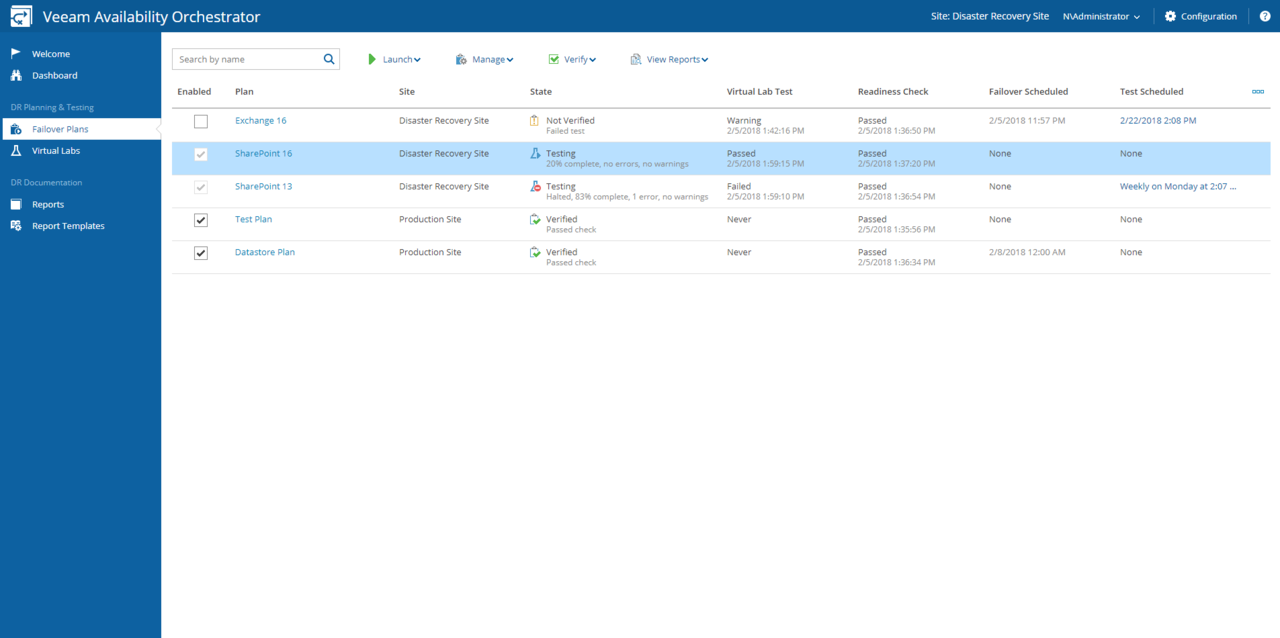
Welcome to the 10th edition of Veeam Vault and the first one for 2018. It's pretty crazy to think that we have already completed two months of the year. Afte...

In recent weeks i've become reacquainted with an old friend...There was a time where eighty to ninety percent of my day job was working in and around Exchang...
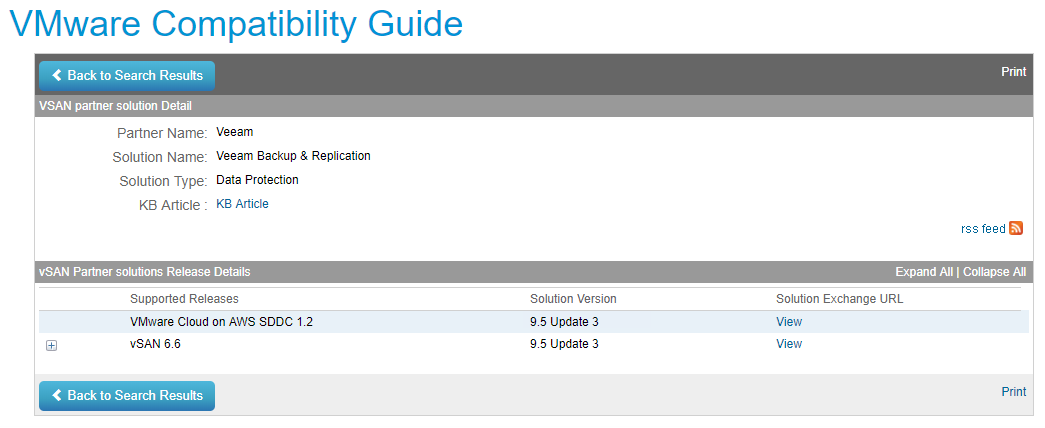
At VMworld 2017 Veeam was announced as one of only two foundation Data Protection partners for VMware Cloud on AWS. This functionality was dependant on the r...
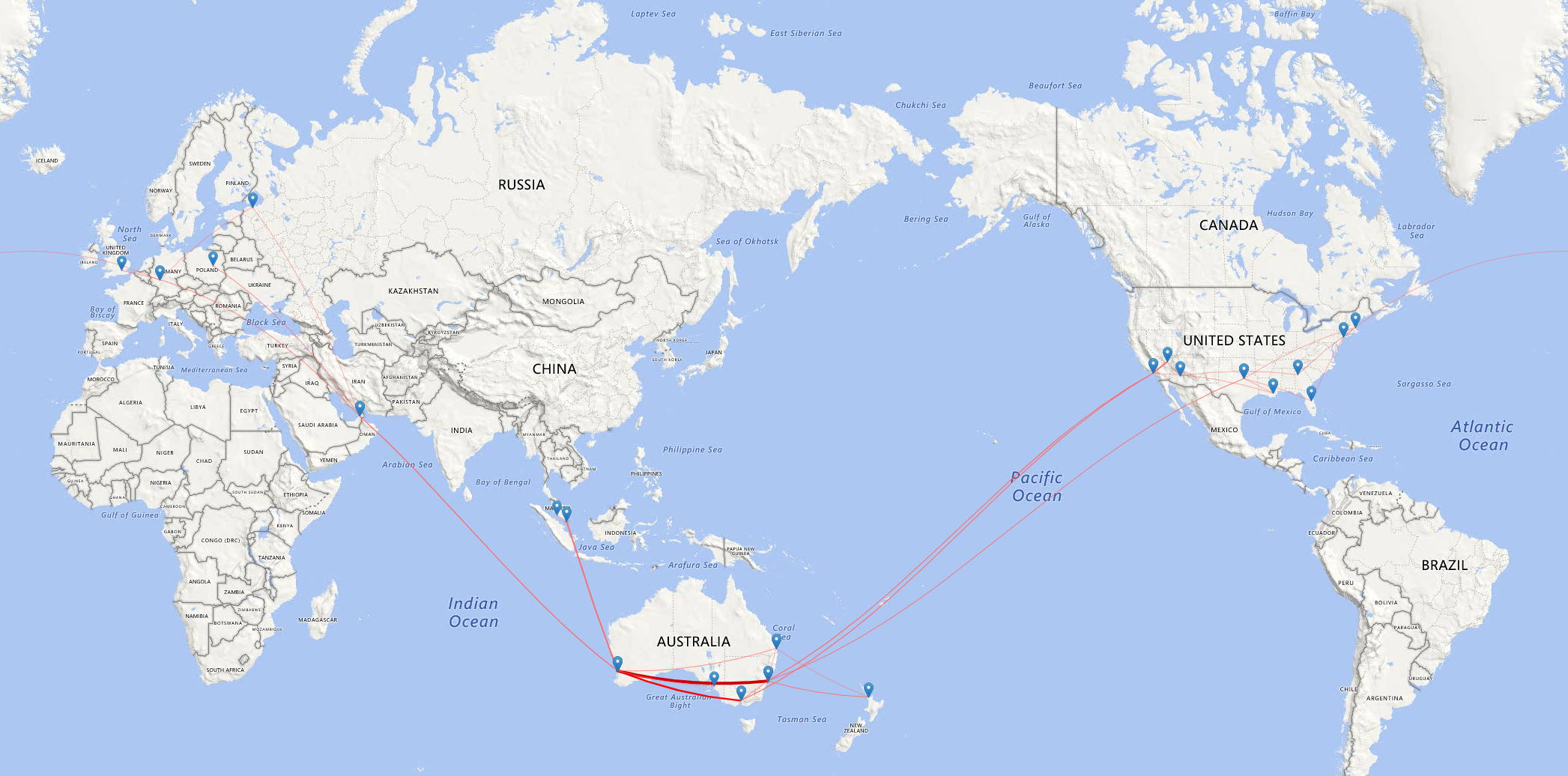
This year was my first full year working for Veeam and my role being global, requires me to travel to locations and events where my team presents content and...
Last week, Veeam Powered Network ( Veeam PN ) was released to GA. As a quick reminder Veeam PN allows administrators to create, configure and connect site-to...

Earlier today we at Veeam released Update 3 for Veeam Backup & Replication 9.5 ( Build 9.5.0.1536 ) and with it comes a couple of very anticipated new featur...

Earlier this week, Veeam made available to our VCSP partners the RTM of Update 3 for Backup & Replication 9.5 ( Build 9.5.0.1335 ). Update 3 is what we term ...
Today, the Veeam Availability Console was made GA meaning that after a long wait our new multi-tenant service provider management and reporting platform is a...
Last week Corey Romero announced the inaugural members of the vExpert Cloud sub-program . This is the third vExpert sub-program following the vSAN and NSX pr...
Earlier this year at VeeamON we announced Veeam PN as part of the Restore to Microsoft Azure product. While Veeam PN is still in RC, I've written a series of...

Both VMworld US and Europe have come and gone in quick time this year and while I only attended VMworld US my team and other Veeam staff featured at Europe a...
It’s been exactly a year since VMware announced their partnership with AWS and it’s no surprise that at this year’s VMworld the solution is front and center ...

I'm sitting in the airport lounge waiting to board the first leg of my 26 hour journey to Las Vegas for VMworld 2017 and I thought it was no better time to w...

A few weeks ago I wrote an article on how Veeam Powered Network can make accessing your homelab easy with it's straight forward approach to creating and conn...

VeeamON 2017 has come and gone and even though I left New Orleans on Friday afternoon, I just arrived back home…54 hours of travel, transit and delays has me...
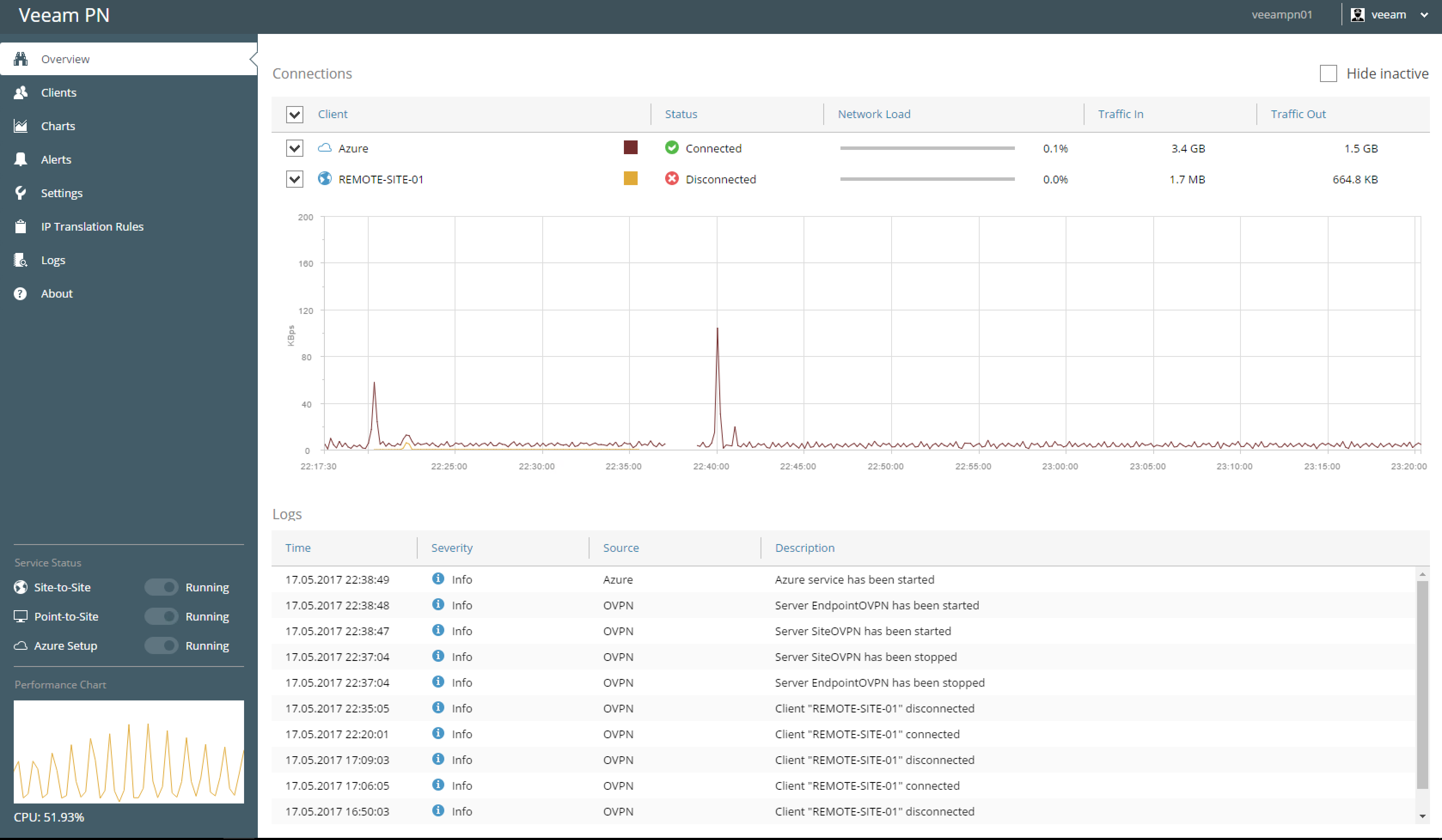
Today at VeeamON 2017 we announced the Release Candidate of Veeam PN (Veeam Powered Network) which together with our existing feature, Direct Restore to Micr...
Today at VeeamON 2017 we announced two very important enhancements to our DRaaS capabilities around Cloud Connect Replication and Tape Backup for our Veeam C...

Time flies quickly when you're having fun! VeeamON 2017 kicks off in New Orleans kicks off in just a few days and to say that it's been a hectic period for t...

Last Friday, Veeam made available to our VCSP partners the RTM of Update 2 for Backup & Replication 9.5 ( Build 9.5.0.1038 ). Update 2 for Backup & Replicati...

VeeamON is less than three weeks away and I can tell you that that this years event is going to be huge! This is going to be my second VeeamOn, but for the f...

Yesterday (30th of March) was Veeam's World Availability Day . This is a day that Veeam has declared to make people aware about how availability plays a part...

Last week I attended the Sydney and Melbourne VMUG UserCons and apart from sitting in on some great sessions I came away from both events with a renewed sens...

Welcome to the fifth edition of the Veeam Vault and the second of 2017. It's been a busy four or so weeks for me since the last update preparing for a number...
Welcome to the fourth edition of my Veeam Vault series and the first for 2017. It's been a busy first month of 2017 with trips to Orlando where I attended my...

Last Friday, we at Veeam made available for download Update 1 for Backup & Replication ( Build 9.5.0.823 ), Veeam One ( Build 9.5.0.3254 ) as well as for Bac...
Welcome to the third edition of my Veeam Vault series. As most of you know I am now working at Veeam as a Technical Evangelist focusing on Veeam’s Service Pr...
Since Backup and Replication 7 Veeam have continued to develop new features in enhancements to support their Cloud and Service Provider community. This start...

As most of you know I am now working at Veeam as a Technical Evangelist focusing on Veeam's Service Provider products and working with VCSP's to help enhance...
As most of you know I am now working at Veeam as a Technical Evangelist focusing on Veeam’s Service Provider products and working with VCSP’s to help enhance...
Last week Veeam released to GA version 9.5 of our Backup & Replication product. Even though this is a point release it’s a significant release for Veeam and ...
A couple of weeks ago Veeam released the RTM Build of Backup & Replication 9.5 to it's Cloud and Service Provider partners. This was to ensure that any keen ...

Last week (we at) Veeam dropped the RTM build of Veeam 9.5 to it’s Cloud Service Provider partners. As a VCSP partner you need to be ready for the v9.5 GA da...

Three and a half years ago I was given a brilliant opportunity to join what was at the time Australia's leading vCloud Powered Service Provider...Zettagrid. ...

A couple of week ago I participated in the APAC leg of the Top 15 Easy Performance Optimization with Rasmus Haslund looking at how to make Veeam Backup & Rep...

Today Veeam has made a number of huge announcements around their plans for the future of availability in the form of a live 90 minute keynote where they unve...

A couple of weeks ago Veeam Cloud Service Provider would have received an email informing them that Update 2 for Veeam 9 Backup & Replication had been RTM'ed...
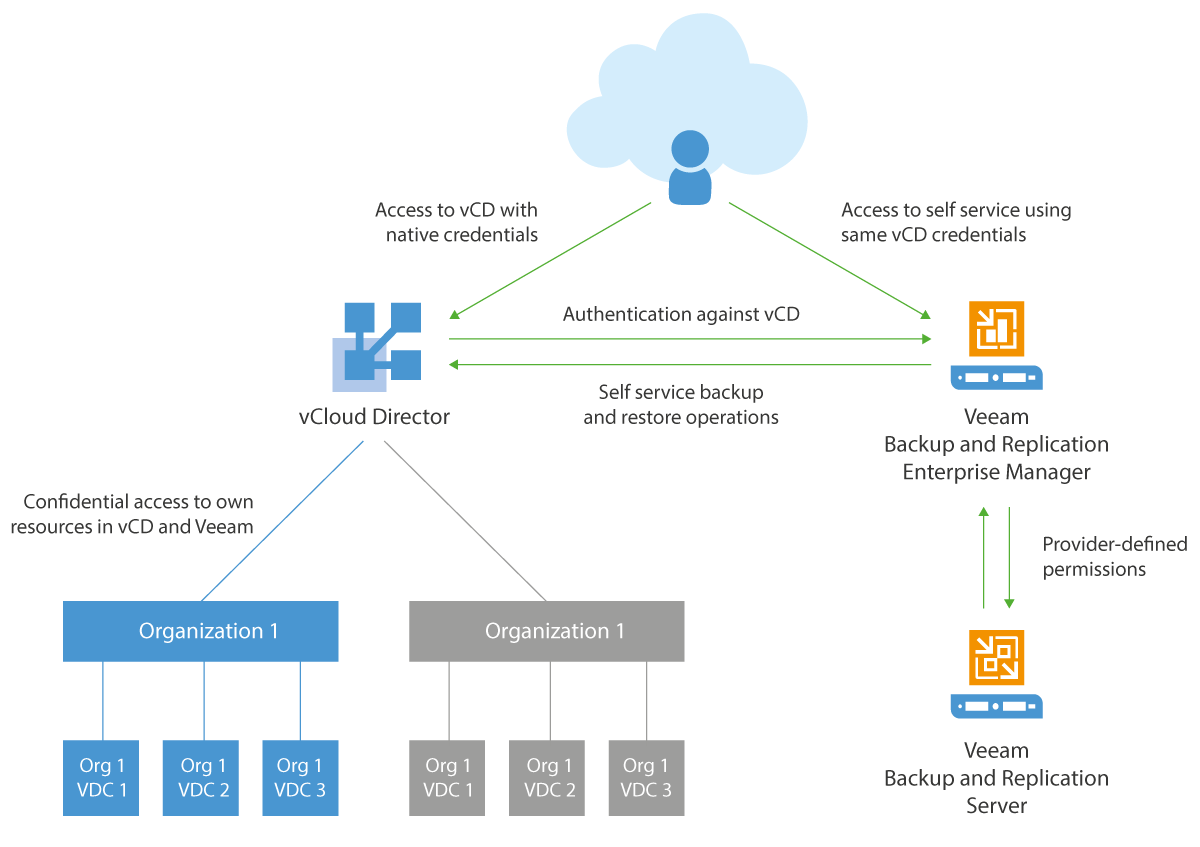
Last month Veeam announced that they had significantly enhanced the capabilities around the backup and recovery of vCloud Director . This will give vCloud Ai...

A couple of weeks ago I was lucky enough to be in London attending the Veeam Vanguard Symposium organised and hosted by the Veeam Evangelist Team headed by R...
Veeam have only announced two features of their upcoming v9.5 release of Backup & Replication but it's exciting to announce that they have chosen to release ...
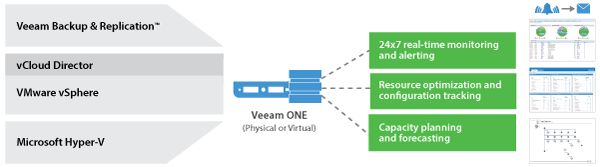
Veeam don't just do awesome Backup & Replication software ...they also have, what I think is a highly underrated operations and management and capacity plann...

This is a quick post to alert Veeam users to an issue that was raised in the Veeam Community Forums yesterday...firstly if you are a Veeam customer and are n...
Overnight Veeam released Hotfix Rollup 1 for Veeam Backup & Replication v9 targeting Veeam Cloud Connect VCSP partners. This is to fix a couple of small perf...
Today (30th of March) is Veeam's World Availability Day . This is a new day that Veeam has declared to make people aware about how availability plays a part ...

Last Friday the Veeam Cloud Service Provider members would have received an email informing them that Update 1 for Veeam 9 Backup & Replication had been RTM'...
Last week Veeam released v9 of their Backup & Replication platform and I went through an listed out the top new general features of the v9 release . In that ...

This week Veeam released to GA version 9 of their Backup & Recovery product. It's a significant release for Veeam for a number of reasons and after having at...

[Update] There is a patch upgrade for v9 (build 9.0.0.773) that needs to be applied before GA which will take the build to build 9.0.0.902. Late last week Ve...

Last week Veeam held their second VeeamOn Conference in Las Vegas at the Aria Resort and Casino . Before the event kicked off last Sunday I wrote a post on m...
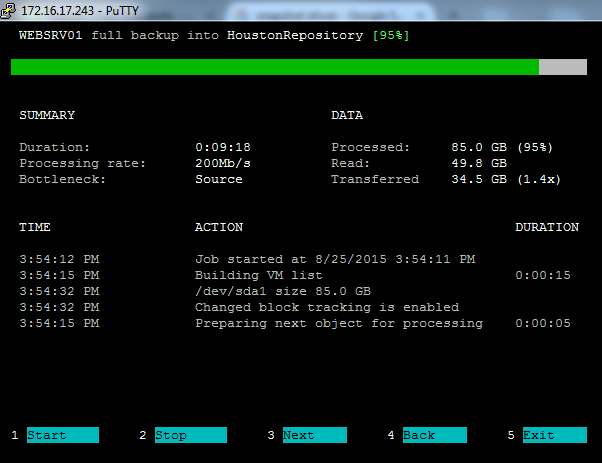
Today during the VeeamOn Keynote, one of the big announcements was that Veeam would be releasing a new Endpoint Backup product that extends support to Linux ...

[ UPDATE ] - This feature will not be available for Cloud Connect in the initial releases but will be supported in future updates.... Hopefully sooner rather...

Last week Veeam released Update 3 for Backup & Replication 8 taking the build number to 8.0.0.2084 and with the update, Veeam have released a couple new feat...
After not being able to share for a month or so it's a honour to announce that I have been selected to be part of the inaugural Veeam Vanguard Program. The V...
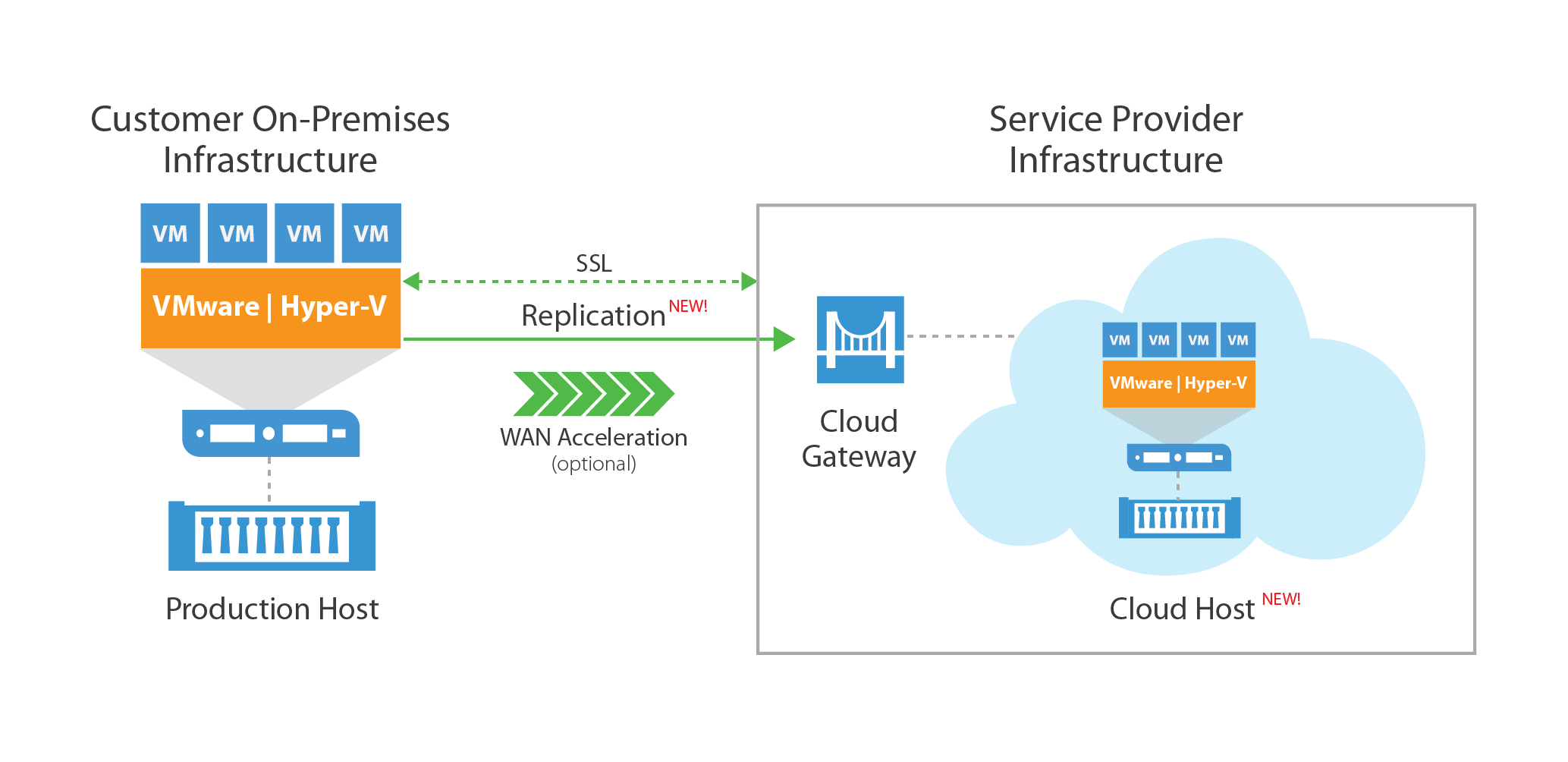
Last week Veeam announced that version 9 of Backup & Replication will feature a new addition to it's Cloud Connect product...Replication for Service Provider...

When Veeam 8 went GA in November of last year I put together a post where I reviewed the best New Features of the v8 release . Last week Veeam released Patch...
Today I went through and upgraded our Veeam Backup and Replication Platform from v7 to v8. Overall the in place upgrade was painless, quick and efficient...h...
VMware released new builds for vCenter and ESXi 5.5 today. The builds contain mostly bug fixes, but I wanted to point out one fix that had affected those who...
Received an email this morning from Veeam letting me know that a zero day patch was available that addresses the CBT Bug mentioned in my previous New Feature...

Last Friday Veeam released version 8 of their Backup and Replication product and like the previous releases the features keep on coming with improvements to ...

I've written a couple of posts around the pain of backup products and I've talked about a world where we backup independent of the Application. Storage platf...
Last weekend I signed up for an account at MEGA . This is @KimDotCom 's new venture attempting to send a big F-U to the regulatory forces that are accusing...