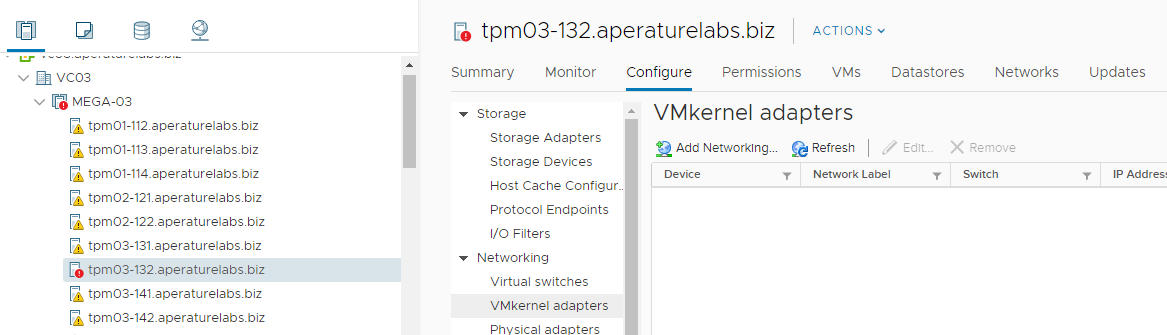
Quick Fix - ESXi loses all Network Configuration... but still runs?
I had a really strange situation pop up in one of my lab environments over the weekend. vSAN Health was reporting that one of the hosts had lost networking c...
Tag
13 posts
I had a really strange situation pop up in one of my lab environments over the weekend. vSAN Health was reporting that one of the hosts had lost networking c...

Last week VMware released a new patch ( ESXi 6.0 Build 5572656 ) that addresses a number of serious bugs with Snapshot operations. Usually I wouldn't blog ab...
NSX-v 6.3 was released last week with an impressive list of new enhancements and I wasted no time in looking to upgrades my NestedESXi lab instance from 6.2....

[ UPDATE ] In light of this post being quoted on The Register I wanted to clarify a couple of things. First off, as mentioned t here is a fix for this issue ...
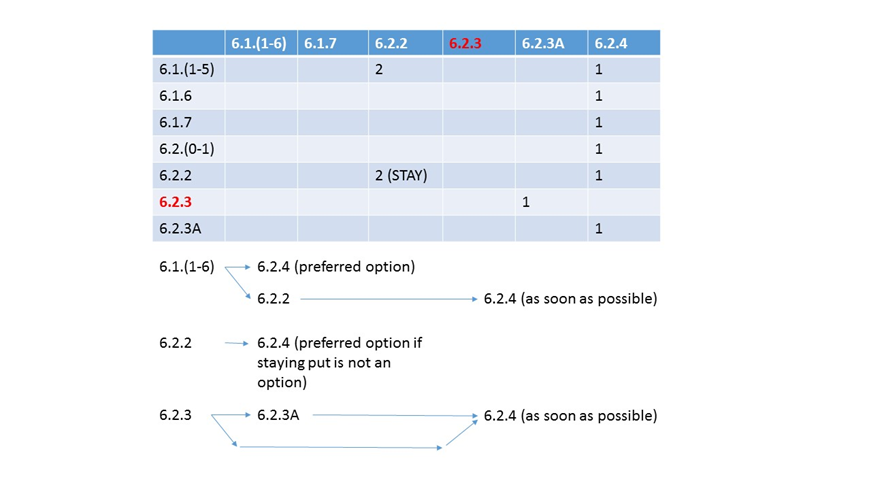
NSX-v 6.2.4 was released the week before VMworld US so might have gotten somewhat lost in the VMworld noise...For those that where fortunate enough to not up...

This is a quick post to alert Veeam users to an issue that was raised in the Veeam Community Forums yesterday...firstly if you are a Veeam customer and are n...

VMware is at an interesting place at this point in time...there is still no doubting that ESXi and vCenter are the market leaders in terms of Hypervisor Plat...
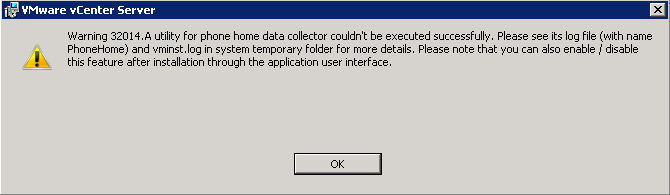
This week I've been upgrading vCenter in a couple of our labs and came across this issue during and after the upgrade of vCenter from 5.5 Update 2 to 5.5 Upd...
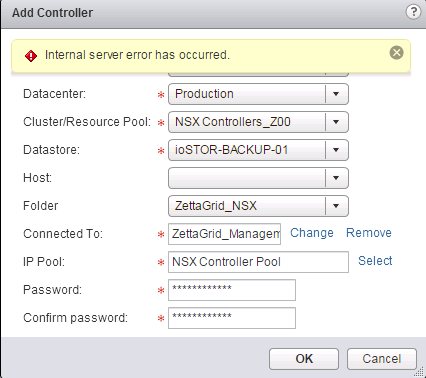
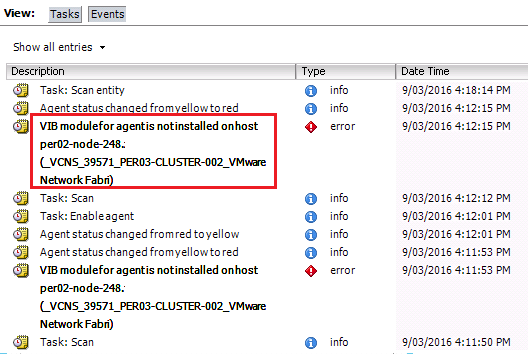
During my initial work with NSX-v I was running various 6.0.x Builds together with vCD 5.5.2 and vCenter/ESXi 5.5 without issue. When NSX 6.1 was released I ...

We are currently in the process of upgrading all of our vCenter Clusters from ESXi 5.1 to 5.5 Update 2 and have come across a bug whereby the vMotion of VMs ...

A few months ago I wrote a quick post on a bug that existed in vCloud Director 5.1 in regards to IP Sub Allocation Pools and IP's being marked as in use when...
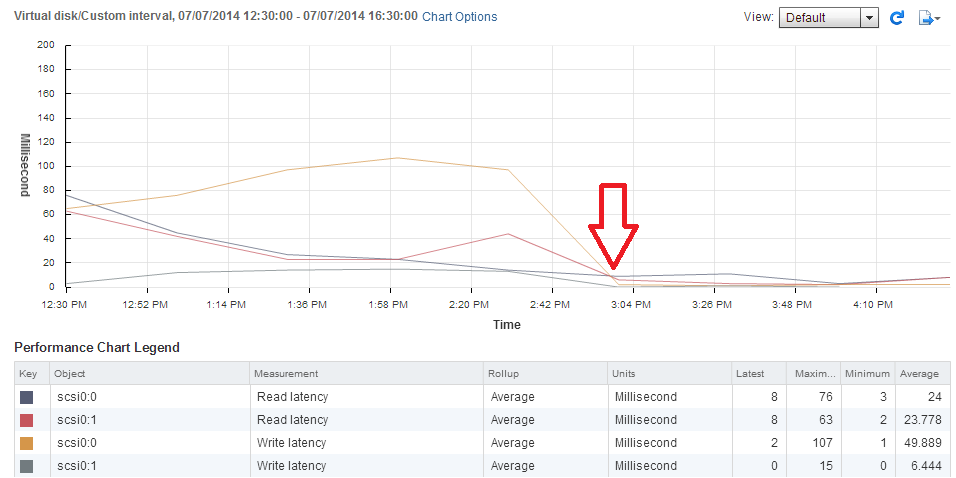
There is another NFS bug hidden in the latest ESXi 5.x releases...while not as severe as the 5.5 Update 1 NFS Bug it's been the cause of increased Virtual Di...
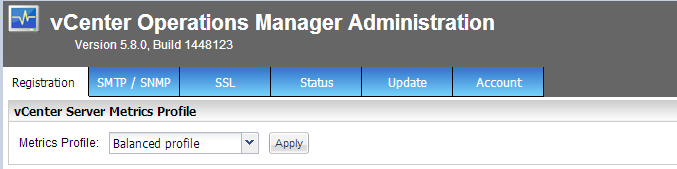
UPDATE : VMware Global Support supplied me with vCOPs 5.8.0 Hot Fix 01 Build 1537842 which is available via a support request. This is a complete .pak update...