
vSphere 7 Update 2 - Tanzu and vSAN Enhancements
I haven't done one of these VMware Update release posts in a while... Having attended the #vExpert pre-brief a couple weeks back I thought there was enough r...
Tag
24 posts
I haven't done one of these VMware Update release posts in a while... Having attended the #vExpert pre-brief a couple weeks back I thought there was enough r...

It didn't seem that long ago that at VMworld 2019 in San Francisco where VMware announced Project Pacific. At the time I wrote about how I thought that it wa...
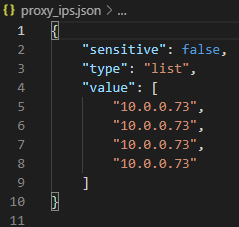
In the continuing work I've been doing with Terraform, i've come across a number of gotchyas when working with VM Templates and deploying them on mass. The n...
I've been working on a project over the last couple of weeks that has enabled me to sharpen my Terraform skills. There is nothing better than learning by doi...
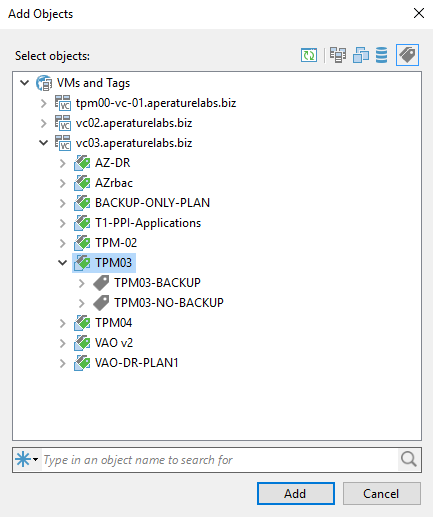
vSphere Tags are used to add attributes to VMs so that they can be used to help categorise VMs for further filtering or discovery. vSphere Tags have a number...
Terraform from HashiCorp has been a revelation for me since I started using it in anger last year to deploy VeeamPN into AWS . From there it has allowed me t...
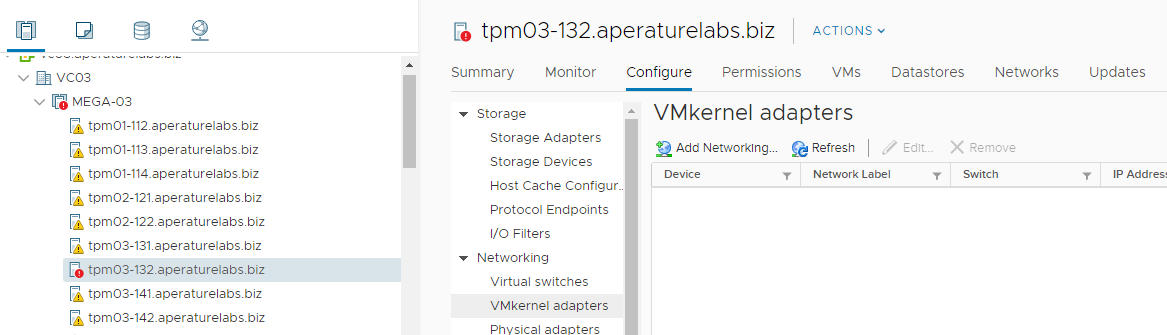
I had a really strange situation pop up in one of my lab environments over the weekend. vSAN Health was reporting that one of the hosts had lost networking c...
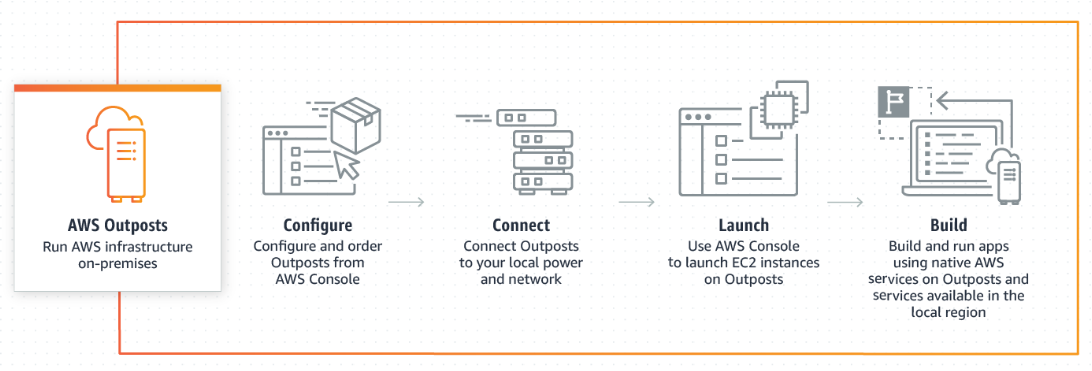
Now that AWS re:Invent 2018 has well and truly passed...the biggest industry shift to come out of the event from my point of view was the fact that AWS are g...

Last week VMware released vSphere 6.7 Update 1 . While the buzz around this release was less than the previous release it still contains a ton of enhancement...

A few weeks ago after much anticipation VMware released vSphere 6.7 . Like 6.5 before it, this is a lot more than a point release and represents a major upgr...
Late last week VMware released vSphere 6.5 Update 1 which included updated builds of both vCenter and ESXi and as per usual I will go through some of the key...
I originally came across the issue of slow storage performance with the native vmw_ahci driver that comes bundled with ESXi 6.5 just as I was first playing w...
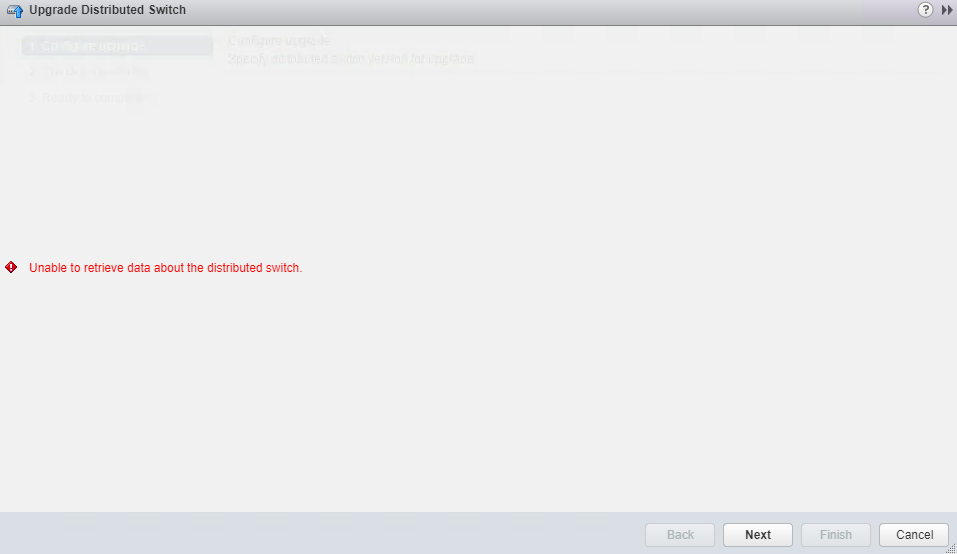
This week I upgraded (and migrated) my SliemaLabs NestedESXi vCenter from a Windows 6.0 server to a 6.5 VCSA ...everything went well, but ran into an issue w...

Over the past few years i've written a couple of articles on upgrading vCenter from 5.5 to 6.0. Firstly an in place upgrade of the 5.5 VCSA to 6.0 and then m...

Just after I joined Zettagrid in June of 2013 I decided to load up vSphere 5.1 Clustering Deepdive by Duncan Epping and Frank Denneman on my iPad to read on ...

Last month I wrote a blog post on upgrading vCenter 5.5 to 6.0 Update 2 and during the course of writing that blog post I conducted a survey on which version...
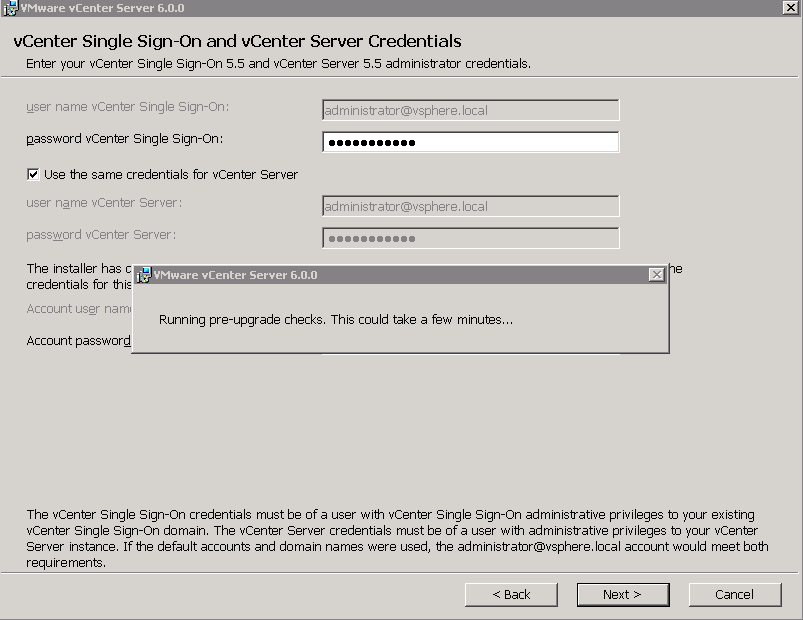
Yes that's not a typo...this post is focusing on upgrading Windows vCenter 5.5 to 6.0 via an in-place upgrade. There is the option to use the vSphere 6.0 Upd...

Last week after an extended period of development and beta testing VMware released vSphere 6.5. This is a lot more than a point release and is a major major ...

Over the past week there have been a number of posts around the new vSphere Beta which is the first step in testing the next major release from VMware follow...
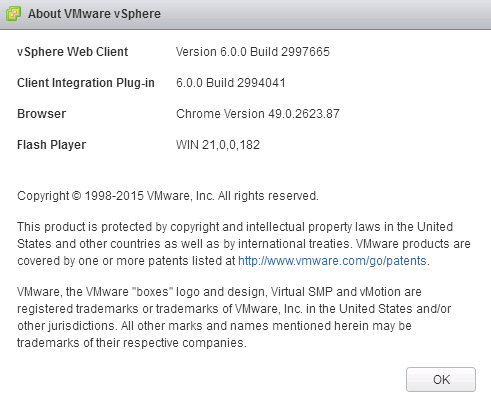
It's been just over a week since VMware released vSphere 6 Update 2 and I thought I would go through some of the key features and fixes that are included in ...

vSphere 5.5 Update 3 was released earlier today and there are a bunch of bug fixes and feature improvements in this update release for both vCenter and ESXi....
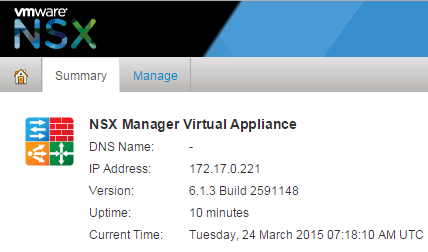
Earlier today NSX-v 6.1.3 was released. This update brings vSphere 6.0 Support as well as bug fixes and a couple minor feature enhancements. https://www.vmwa...
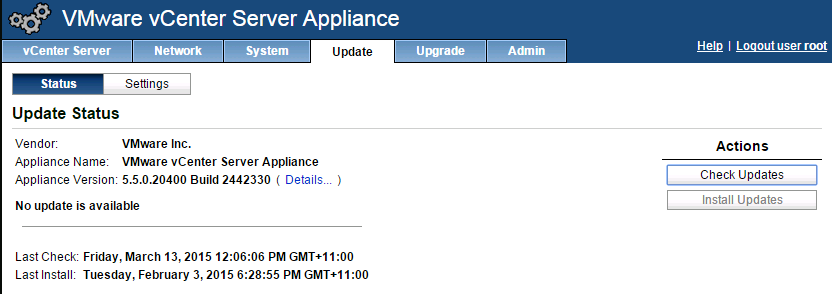
Like most VMware Junkies over the past 24 hours I've downloaded the vSphere 6.0 bits and had them ready and primed to deploy and discover all the new feature...
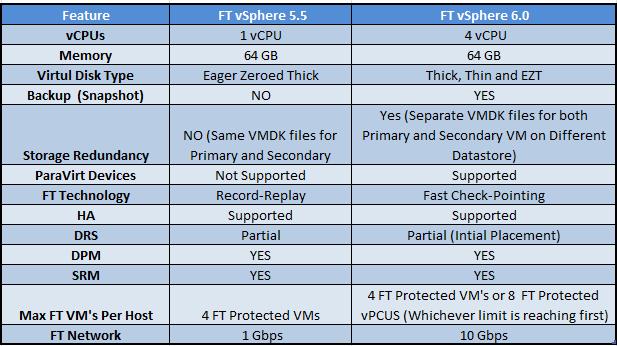
Today vSphere 6.0 was officially announced and will be GA in about 6-8 weeks...I've had limited time myself to tinker with the BETA in great depth, however I...