Evolution of Apache CloudStack: From Cloud.com to Apache
The cloud computing landscape has witnessed a remarkable transformation with the emergence of open-source platforms. Among these, Apache CloudStack stands ou...
Tag
31 posts
The cloud computing landscape has witnessed a remarkable transformation with the emergence of open-source platforms. Among these, Apache CloudStack stands ou...

NOTE: The following content was transcribed and modified from the Thoughts on X podcast…Click Play if you would like to listen. I think we should all put a p...

NOTE: The following content was transcribed and modified from the Thoughts on X podcast embedded above... Click Play if you would like to listen. Last week, ...
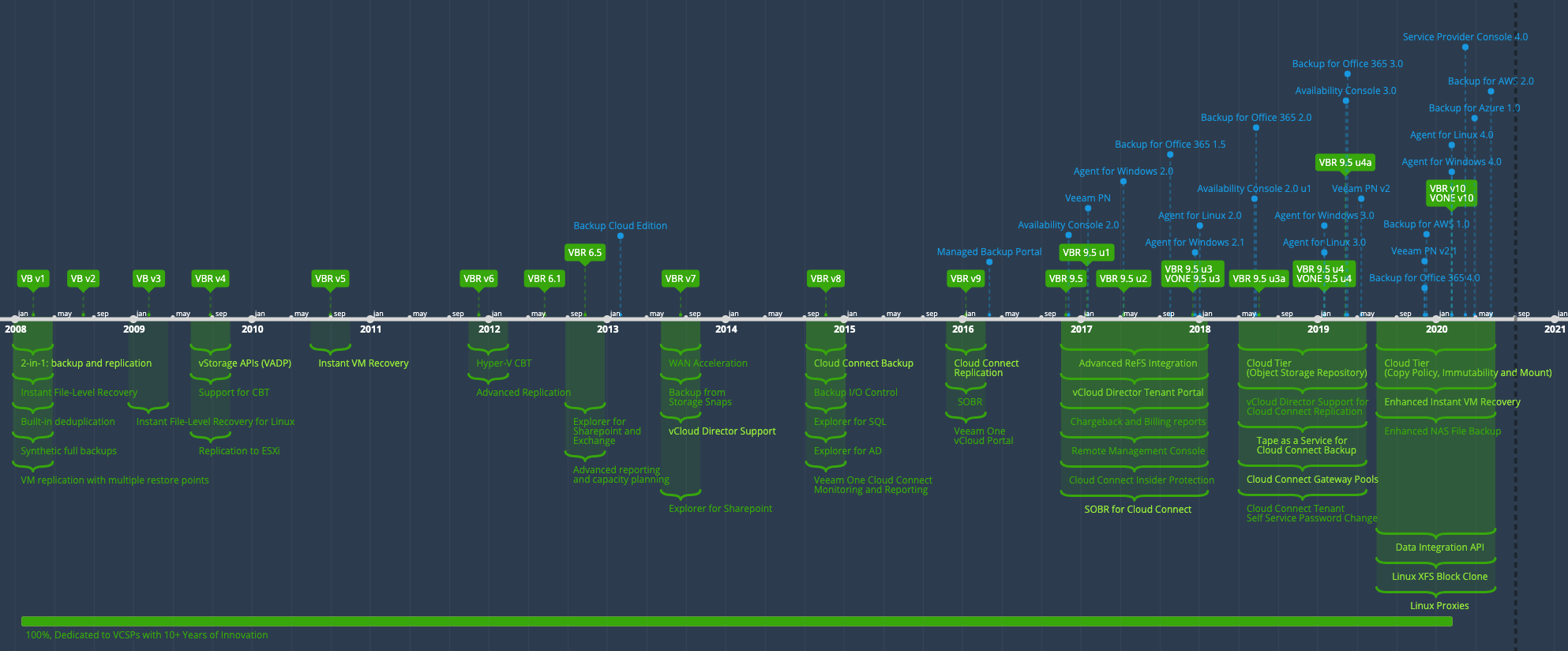
Hard to believe that I've been using Veeam for over ten years now! This blog has been testament to how Veeam has always been close to Cloud and Service Provi...
Last week I had the pleasure of presenting at Cloud Field Day 5 (a Tech Field Day event). Joined by Michael Cade and David Hill, we took the delegates throug...
With the release of Update 4 for Veeam Backup & Replication 9.5 we further enhanced our overall cloud capabilities by adding a number of new features and enh...

We are entering interesting times in the cloud space! We should no longer be talking about the cloud as a destination and we shouldn’t be talking about how c...

As Red October came to a close…at a time when US Tech stocks were taking their biggest battering in a long time the news came out over the weekend that IBM h...

A couple of weeks ago I stumbled upon Zenko via a LinkedIn post. I was interested in what it had to offer and decided to go and have a deeper look. With Veea...
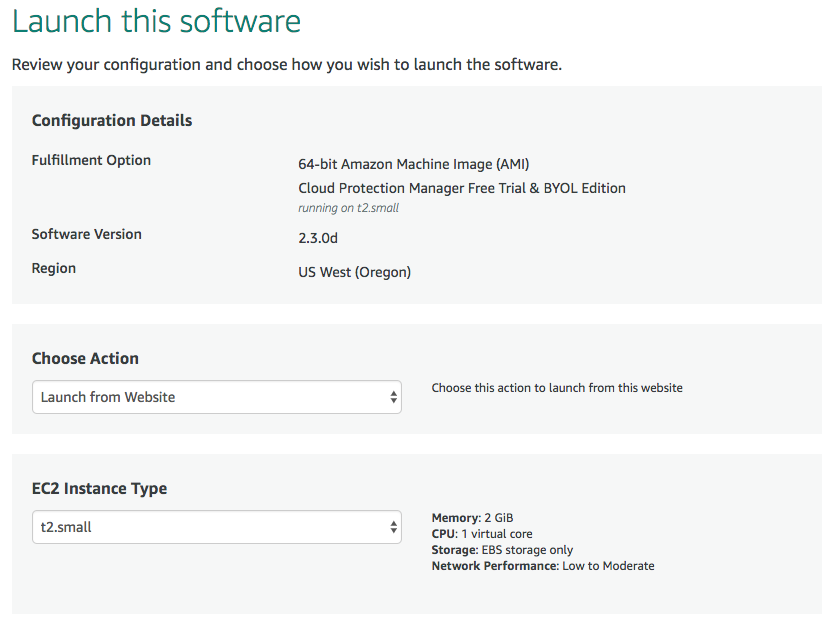
Earlier this year Veeam acquired N2WS after announcements last year of a technology partnership at VeeamON 2017. The more I tinker with Cloud Protection Mana...
I'm ok admitting that I am still learning as I progress through my career and I'm ok to admit when things go wrong. Learning from mistakes is a crucial part ...

VMware has held it's first ever VMware Cloud Briefing today. This is an online, global event with an agenda featuring a keynote from Pat Gelsinger, new annou...

Today is the first day offical day of AWS re:Invent 2017 and things are kicking off with the global partner summit. Today also is my first day of AWS re:Inve...
It’s been exactly a year since VMware announced their partnership with AWS and it’s no surprise that at this year’s VMworld the solution is front and center ...
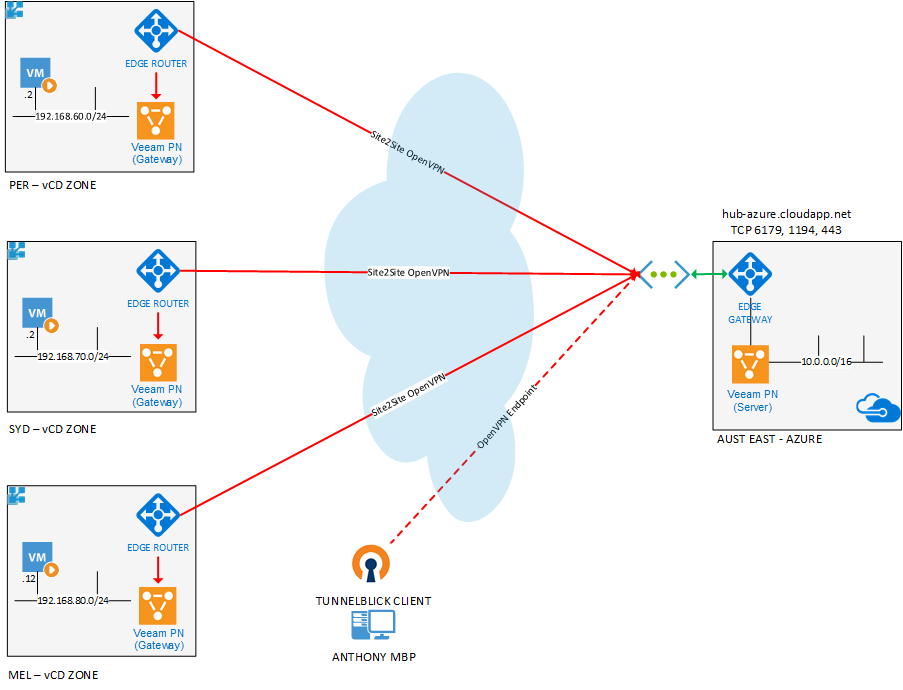
I've written a couple of posts on how Veeam Powered Network can make accessing your homelab easy with it's straight forward approach to creating and connecti...

In July of 2011, Distribute.IT, a domain registration and web hosting services provider in Australia was was hit with a targeted, malicious attack that resul...

I’ve been on the road over the past couple of weeks presenting to Veeam’s VCSP partners and prospective partners here in Australia and New Zealand on Veeam’s...

Last week VMware and Amazon Web Services officially announced their new joint venture whereby VMware technology will be available to run as a service on AWS ...

Microsoft's World Wide Partner Conference is currently on again in Toronto and even though my career has diverged from working on the Microsoft stack (no pun...
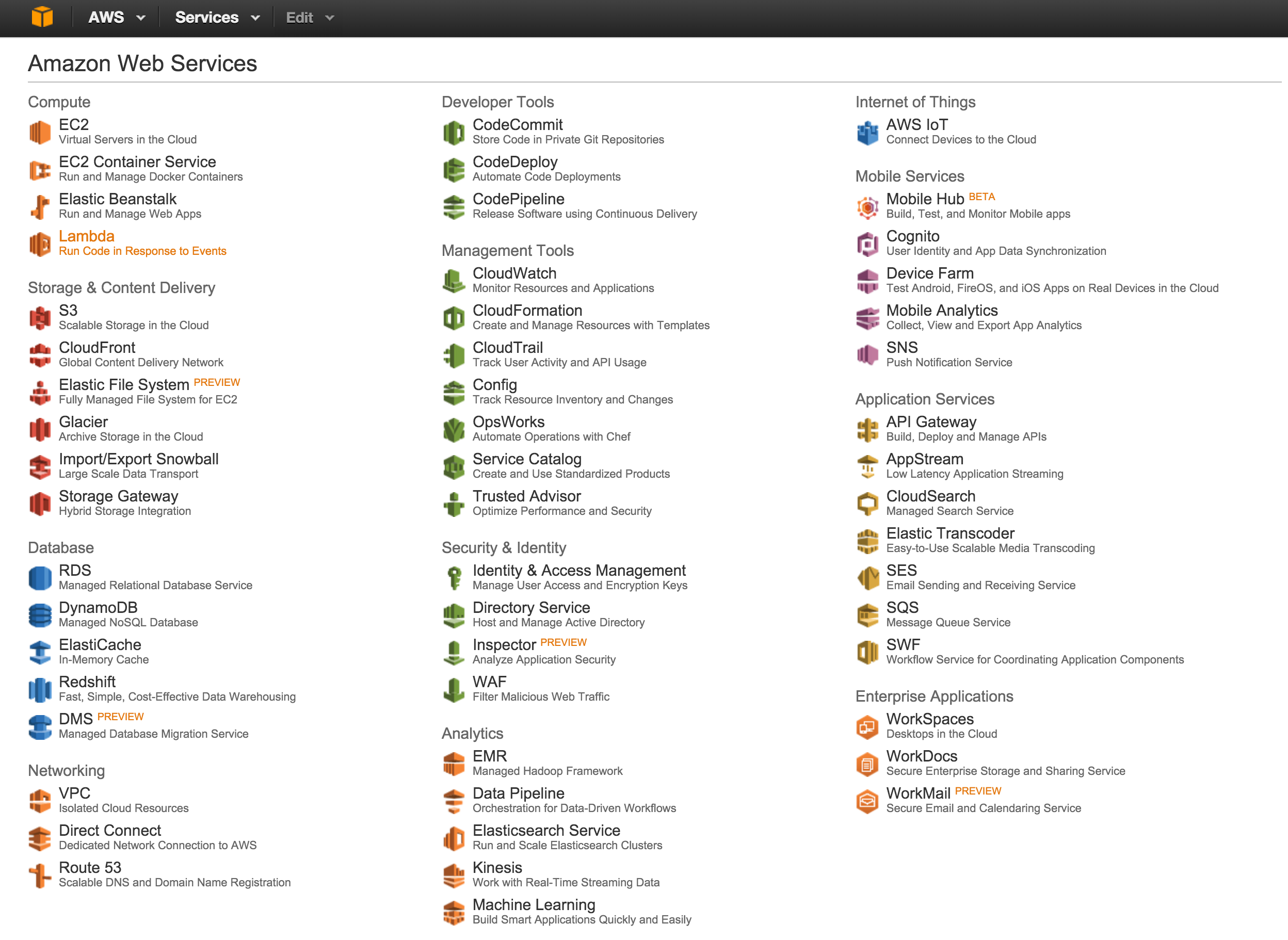
I came across a tweet over the weekend which showed a screen grab of the AWS product catalog (shown below) and a comment pointing out the fact that the sheer...

I’ve been wanting to write some commentary around the vCloud Air and Virtustream merger since rumours of it took place just before VMworld in Auguest and I’v...

Today Ninefold (an Australian based IaaS and PaaS) provider announced that they where closing their doors an would be migrating their clients to their parent...

A couple of weeks ago Microsoft raised the prices of Azure , Office 365, CRM Online and other enterprise cloud services across Australia, Canada and Europe. ...

It's been a bad couple of weeks for cloud services both around the world and locally...Over the last three days we have seen AWS have issues which may have b...
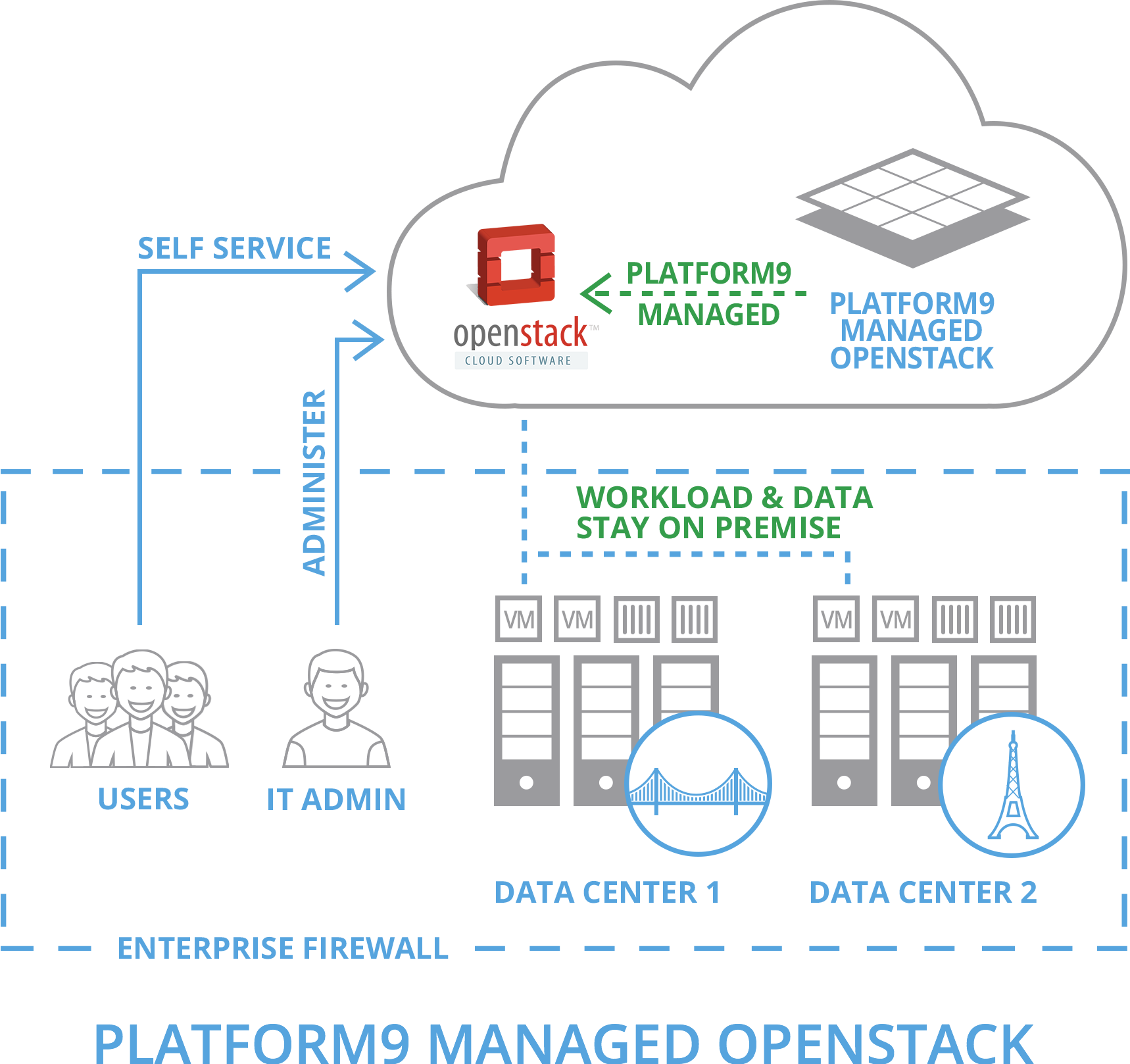
I came across Platform9 while wandering the back halls of the VMWorld Solutions Exchange last year in San Francisco…as a fan of the movie District 9 I was dr...

As mentioned in a previous post I was lucky enough to be able to present a #vBrownBag Tech Talk at this years VMworld. Even though the timing meant a smallis...

I've written a couple of posts around the pain of backup products and I've talked about a world where we backup independent of the Application. Storage platf...
During last weeks #APACVirtual Podcast ( Episode 70 – Engineers Anonymous pt1 – Engineer2PreSales ) the panelists (of which, I was one) where discussing...
Last weekend I signed up for an account at MEGA . This is @KimDotCom 's new venture attempting to send a big F-U to the regulatory forces that are accusing...
There where some pretty big announcements and reveals at VMworld 2012, but unless I missed something (which was totally possible had any accouncement been ma...
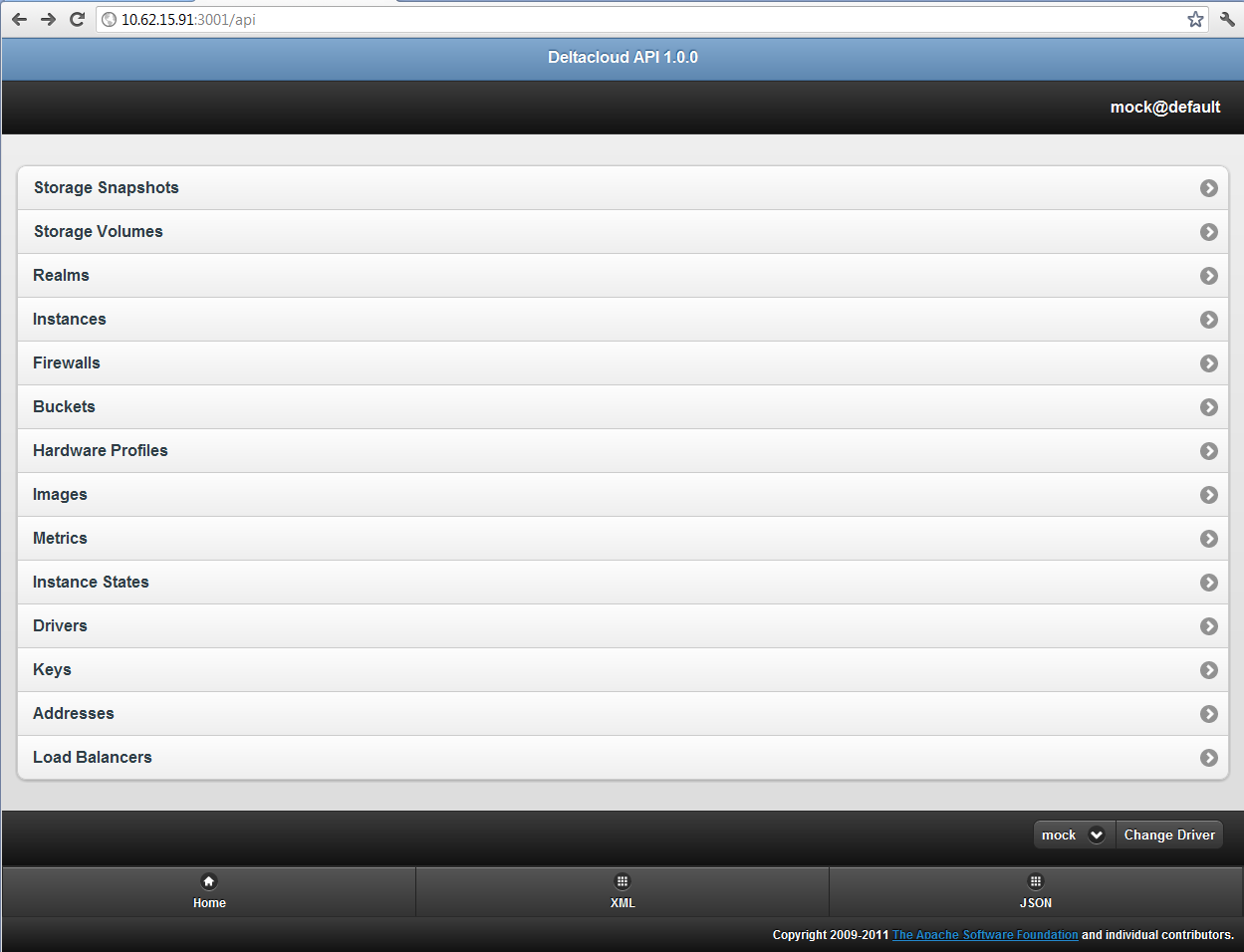
As I was browsing my Twitter feed last night I can across a tweet that talked about the 1.0 Release of Apache DeltaCloud. As described on the website : Delta...