
First Look - Zenko, Multi-Platform Data Replication and Management
A couple of weeks ago I stumbled upon Zenko via a LinkedIn post. I was interested in what it had to offer and decided to go and have a deeper look. With Veeam launching our vision to be the leader of (http://anthonyspiteri.net/veeamon-2018-recap/) at VeeamON this year, I have been on the lookout for solutions that do smart thing with data that addresses the needs related to controlling the accelerated spread and sprawl of that data. Zenko looks to be on the right track with it’s notion of freedom to avoid being locked into a specific cloud platform whether it’s private or public.
Having come from service provider land I have always been against the idea of a Hyper-Scaler Public Cloud monopoly that forces lock-in and diminishes choice. Because of that, I gravitated to Zenko’s mission statement:
We believe that everyone should be in control of their data. Zenko’s mission is to allow everyone to be in control of their data, while leveraging the efficiency of private and public clouds.
This platform looks to do data mobility across multiple cloud platforms through common communication protocols and by sharing a common set of APIs to manage it’s data sets. Zenko is focused on achieving this multi-cloud capability through a unified AWS S3 API based services with data management and federated search capabilities driving it’s use cases. Data mobility between clouds, whether private or public cloud services it what Zenko is aimed at.
Zenko Orbit:
Zenko Orbit is the cloud portal for data placement, workflows and global search. Focused for application developers and “DevOps” the premise of Zenko Orbit is that those guys can spend less time learning multiple interfaces for different clouds while leveraging the power of cloud storage and data management services without needing to be an expert across different platforms.
Orbit provides an easy way to create replication workflows between difference cloud storage platforms…weather it be Amazon s3, Azure Blog, GCP Storage or others. You then have the ability to search across a global namespace for system and user-defined metadata.
Quick Walkthrough:
Given this is open source you have the option to download and install a Zenko instance which will then be registered against the Orbit cloud portal or you can pull the whole stack from GitHub. They also have a sandboxed instance hosted by them that can be used to take the system for a test drive.
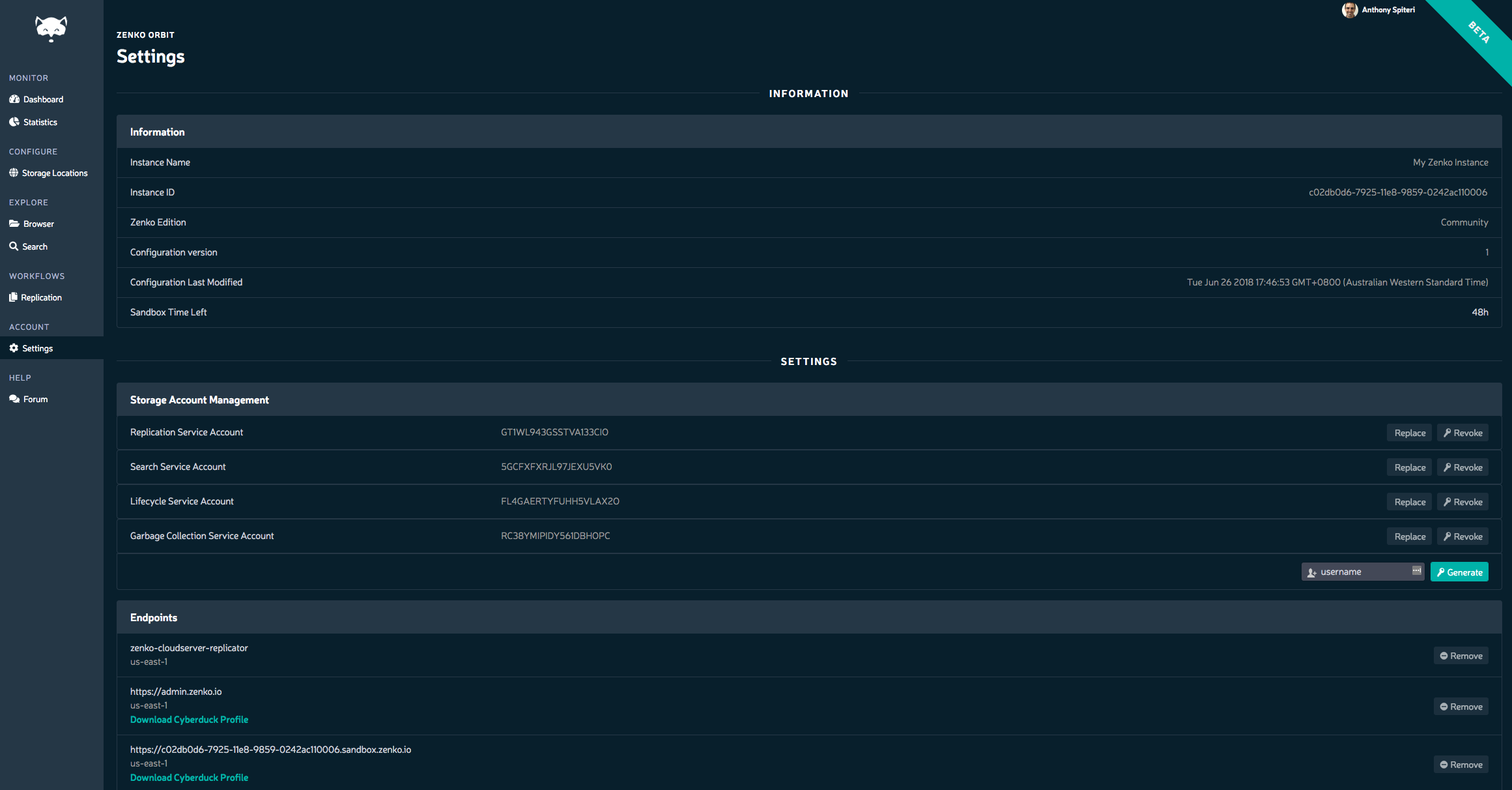
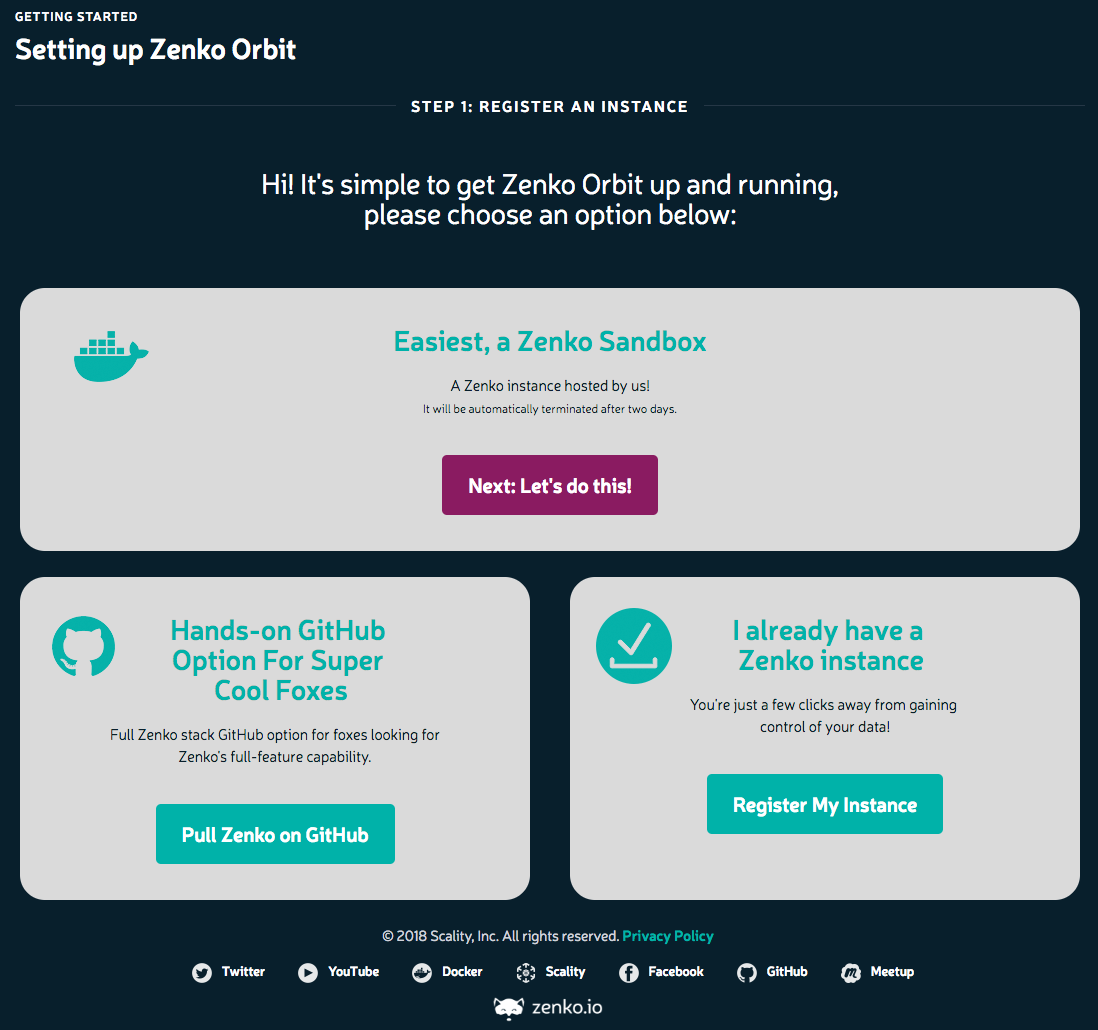 Once done, you are presented with a Dashboard that gives you an overview of the amount of data and other metric contained in your instance. Looking at the Settings area you are given details about the instance, account details and endpoints to use to connect up into. They also other the ability to download pre generated Cyberduck Profiles.
Once done, you are presented with a Dashboard that gives you an overview of the amount of data and other metric contained in your instance. Looking at the Settings area you are given details about the instance, account details and endpoints to use to connect up into. They also other the ability to download pre generated Cyberduck Profiles.
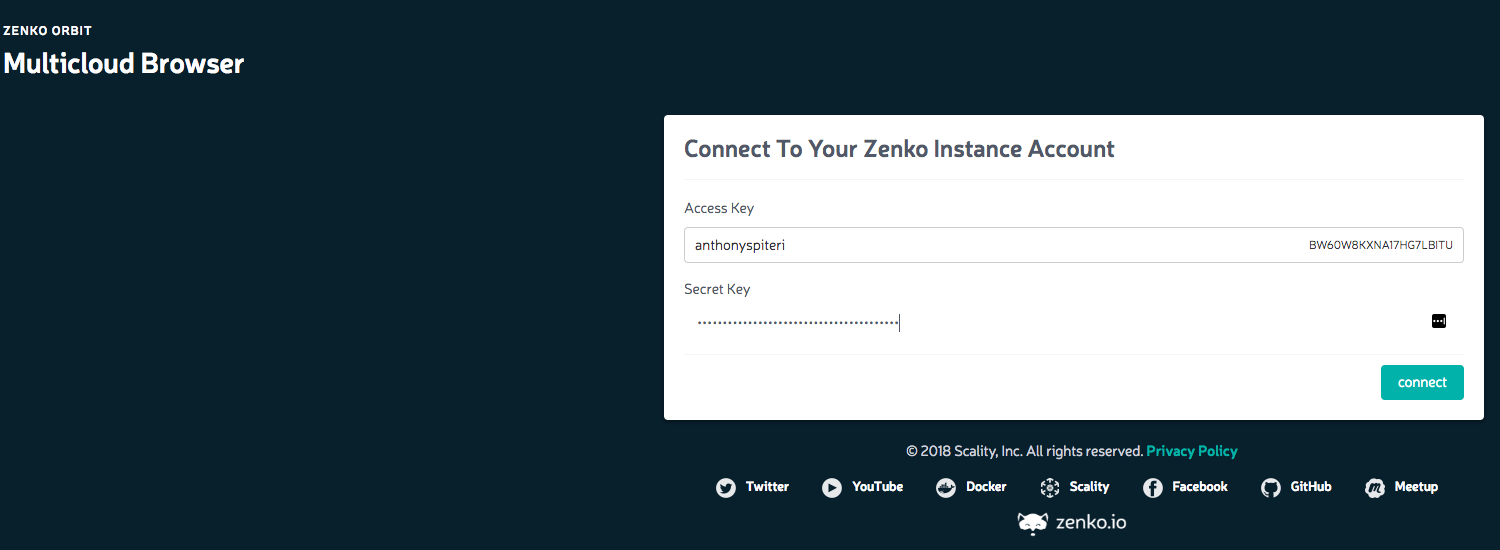
You need to create a storage management account to be able to browse your buckets in the Orbit portal.
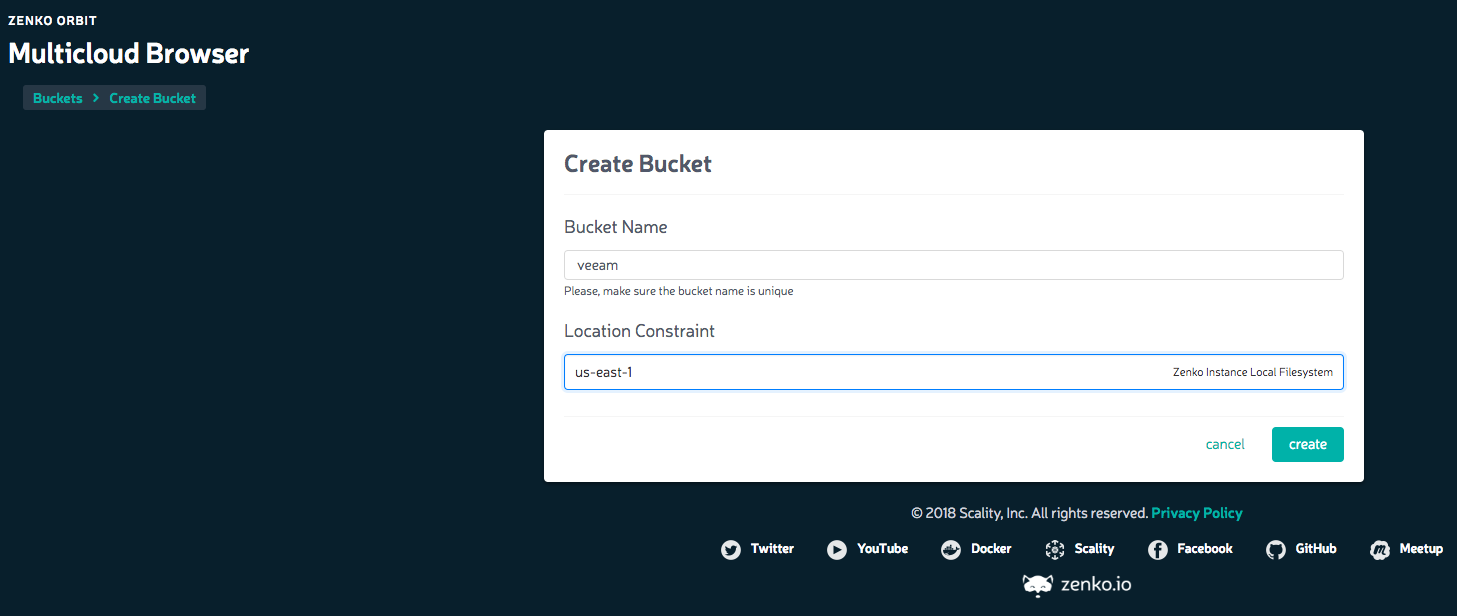
 Once that’s been done you can create a bucket and select a location which in the sandbox defaults to AWS us-east-1.
Once that’s been done you can create a bucket and select a location which in the sandbox defaults to AWS us-east-1.
 From here, you can add a new storage location and configure the replication policy. For this, I created a new Azure Blob Storage account as shown below.
From here, you can add a new storage location and configure the replication policy. For this, I created a new Azure Blob Storage account as shown below.
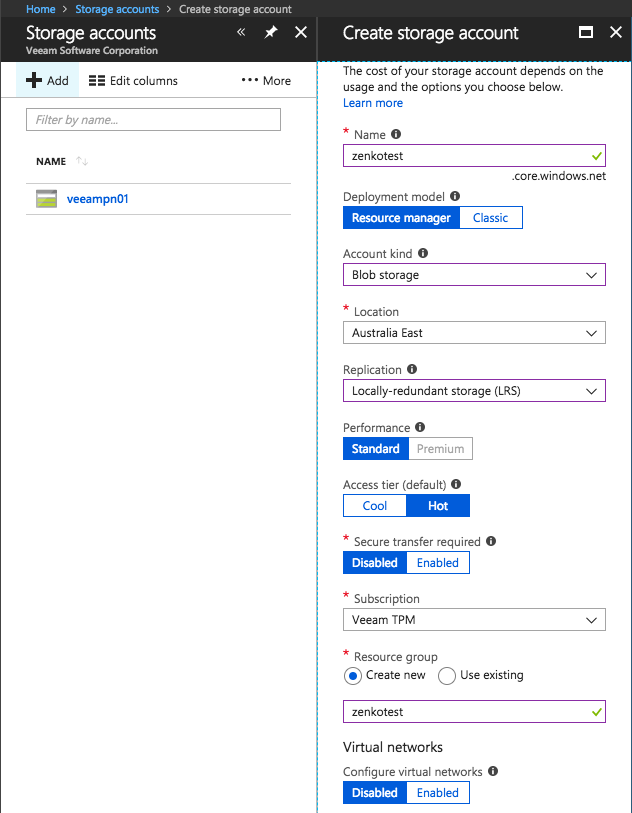 From the Orbit menu, I then added a New Storage Location.
From the Orbit menu, I then added a New Storage Location.
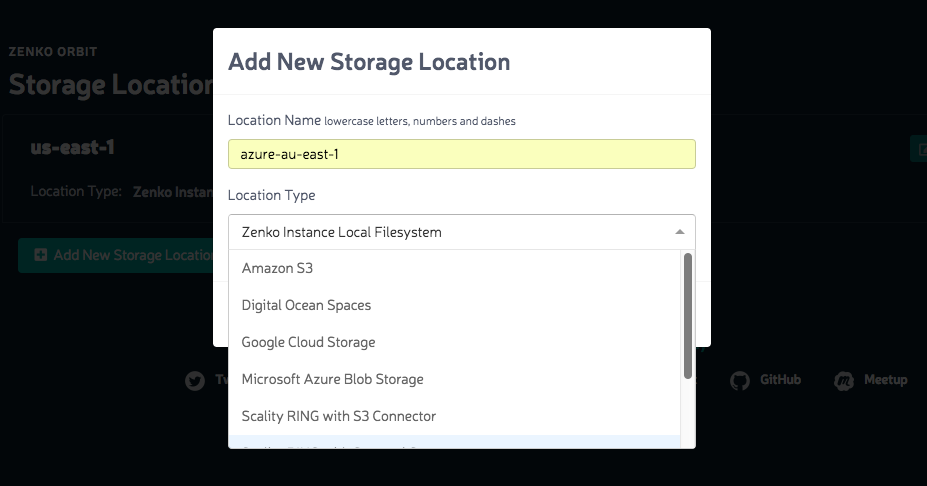
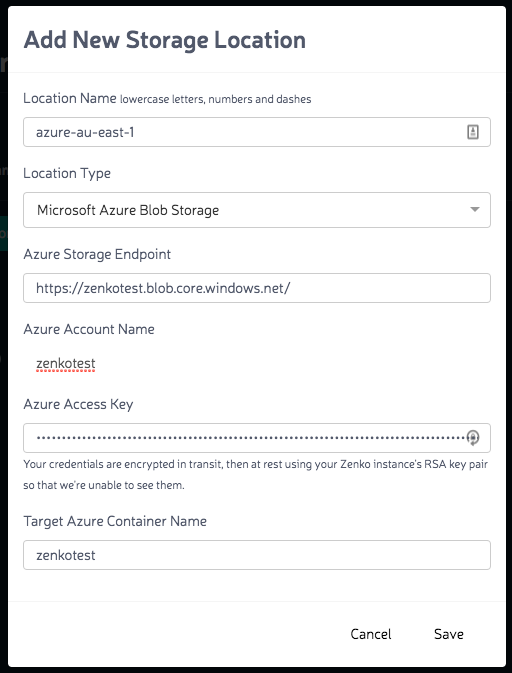
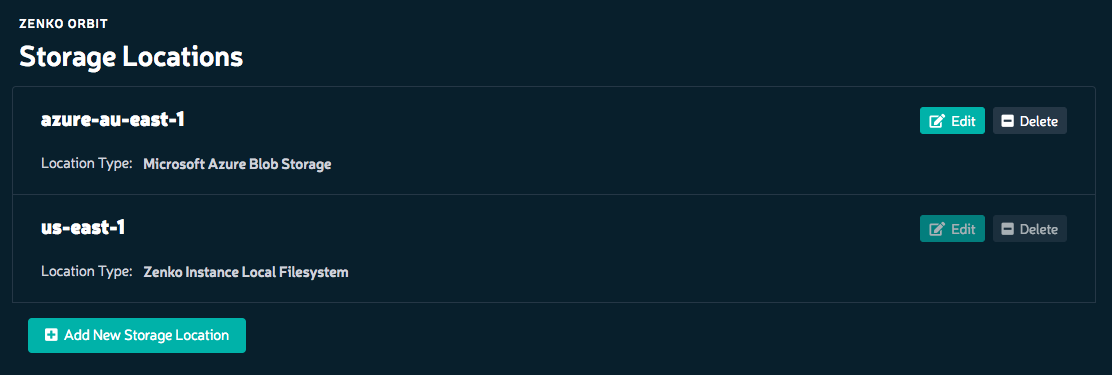 Once the location has been added you can configure the bucket replication. This is the cool part that is the premise of the platform. Being able to setup policies to replicate data across multiple cloud platforms. From the sandbox, the policy is one way meaning there is no directional replication. Simply select the source and destination and the bucket from the menu.
Once the location has been added you can configure the bucket replication. This is the cool part that is the premise of the platform. Being able to setup policies to replicate data across multiple cloud platforms. From the sandbox, the policy is one way meaning there is no directional replication. Simply select the source and destination and the bucket from the menu.
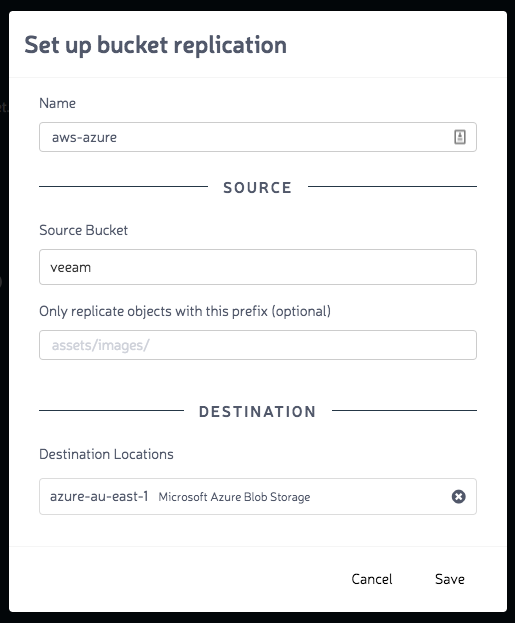
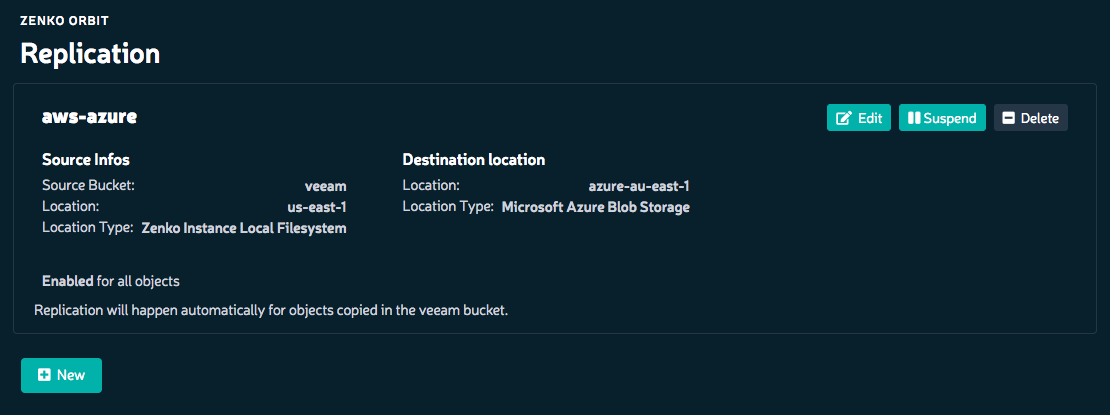 Once that has been done you can connect to the endpoint and upload files. I tested this out with the setup above and it worked as advertised. Using the CyberDuck profile I connected in, uploaded some files and monitored the Azure Blog storage end for the files to replicate.
Once that has been done you can connect to the endpoint and upload files. I tested this out with the setup above and it worked as advertised. Using the CyberDuck profile I connected in, uploaded some files and monitored the Azure Blog storage end for the files to replicate.

 Conclusion:
While you could say that Zenko feels like DFS-R for the multi-platform storage world, the solution has impressed me. Many would know that it’s not easy to orchestrate the replication of data between different platforms. They are also talking up their capabilities around (https://www.zenko.io/community/extensions/) of the platform as is relates to data management, backend storage plugins and search.
I think about this sort of technology and how it could be extended to cloud based backups. Customers could have the option to tier into cheaper cloud based storage and then further protect that data by replicating it to another cloud platform which could be cheaper yet. This could achieve added resiliency while offering cost benefits. However there is also the risk that the more spread out the data is, the harder it is to control. That’s where intelligent data management comes into play…interesting times!
References:
https://www.zenko.io/admin/
Conclusion:
While you could say that Zenko feels like DFS-R for the multi-platform storage world, the solution has impressed me. Many would know that it’s not easy to orchestrate the replication of data between different platforms. They are also talking up their capabilities around (https://www.zenko.io/community/extensions/) of the platform as is relates to data management, backend storage plugins and search.
I think about this sort of technology and how it could be extended to cloud based backups. Customers could have the option to tier into cheaper cloud based storage and then further protect that data by replicating it to another cloud platform which could be cheaper yet. This could achieve added resiliency while offering cost benefits. However there is also the risk that the more spread out the data is, the harder it is to control. That’s where intelligent data management comes into play…interesting times!
References:
https://www.zenko.io/admin/