
Quick Fix: vSphere Storage Provider Offline
It's been a while since i've done a vSphere specific Quick Fix post, but the great thing about tinkering and labbing is that you run into situations and corn...
Tag
23 posts
It's been a while since i've done a vSphere specific Quick Fix post, but the great thing about tinkering and labbing is that you run into situations and corn...
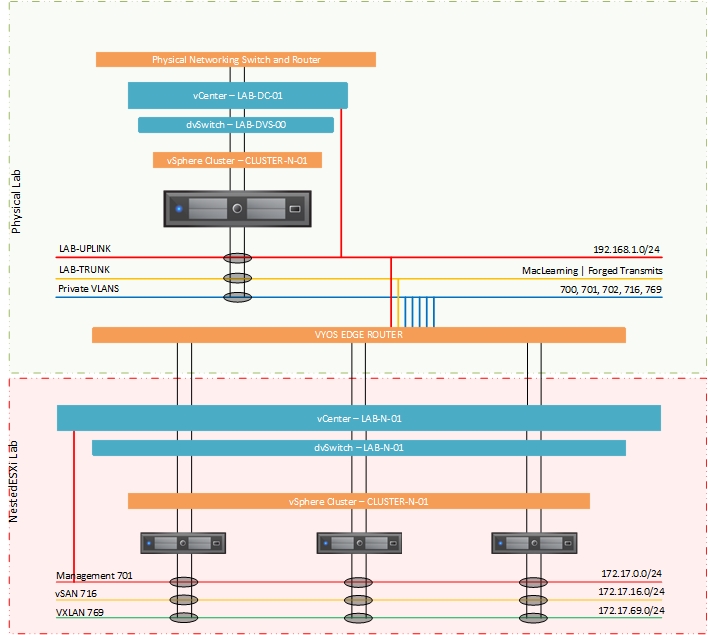
Back for part two of this look at how I went about configuring a single host for NestedESXi deployments. In the previous post I looks at the physical configu...
I've should have written this article a long long time ago! In fact, i've been promising certain people that I would write this up for a number of years. The...

Over the last few years the amount of CBT related issues has decreased significantly from VMware. I remember back in my previous roles of having to deal with...
Late last week VMware released vSphere 6.5 Update 1 which included updated builds of both vCenter and ESXi and as per usual I will go through some of the key...
I originally came across the issue of slow storage performance with the native vmw_ahci driver that comes bundled with ESXi 6.5 just as I was first playing w...
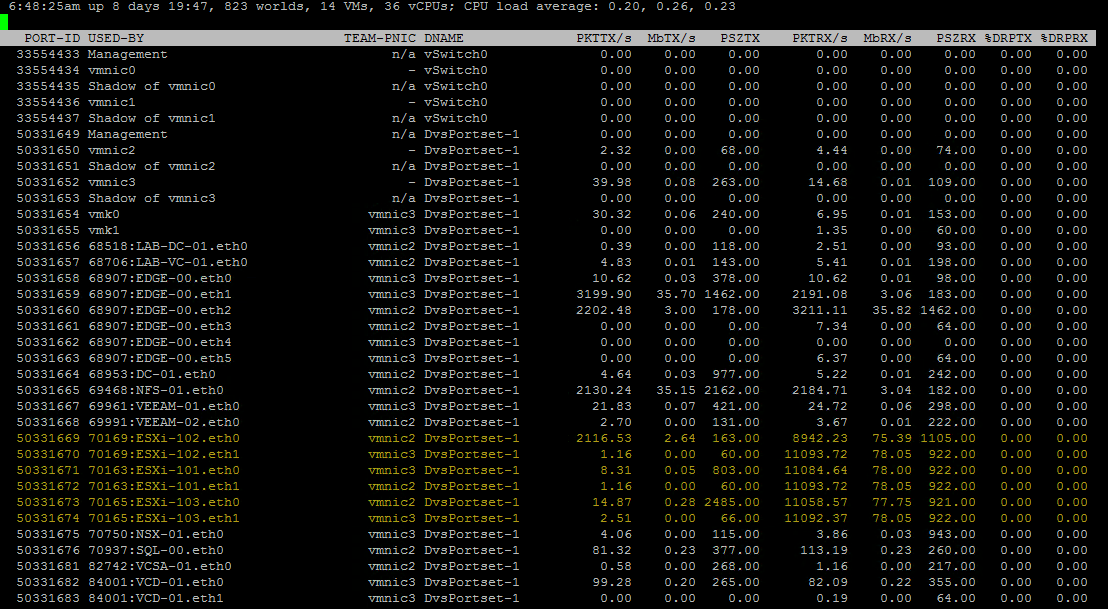
I've been running my NestedESXi homelab for about eight months now but in all that time I had not installed or enabled the ESXi MAC Learning dvFilter . As a ...

Last week VMware released a new patch ( ESXi 6.0 Build 5572656 ) that addresses a number of serious bugs with Snapshot operations. Usually I wouldn't blog ab...

[ NOTE ] : I decided to republish this post with a new heading and skip right to the meat of the issue as I've had a lot of people reach out saying that the ...
Last month I wrote a blog post on upgrading vCenter 5.5 to 6.0 Update 2 and during the course of writing that blog post I conducted a survey on which version...

Last week after an extended period of development and beta testing VMware released vSphere 6.5. This is a lot more than a point release and is a major major ...
It's been just over a week since VMware released vSphere 6 Update 2 and I thought I would go through some of the key features and fixes that are included in ...
For the last couple of weeks we have had some intermittent issues where by ESXi network adapters have gone into a disconnected state requiring a host reboot ...

vSphere 5.5 Update 3 was released earlier today and there are a bunch of bug fixes and feature improvements in this update release for both vCenter and ESXi....
In 2008 I vividly remember the impact that leap year/day/seconds can have on systems that are not prepared to handle the changes in time or date. It was the ...
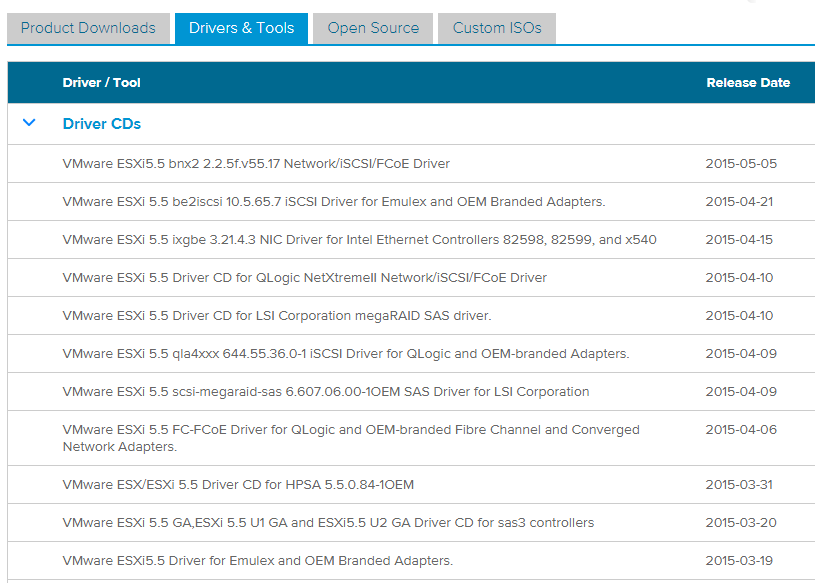
Today I needed to update an Emulex NIC Driver for an new host that I installed using the VMware ESXi 5.5 Update 2 base image. I needed to chase up the latest...
VMware released new builds for vCenter and ESXi 5.5 today. The builds contain mostly bug fixes, but I wanted to point out one fix that had affected those who...

It's fair to say that it's not very often the difference between a 1 and 0 can have such a massive impact on performance...I had read a couple of posts from ...

We are currently in the process of upgrading all of our vCenter Clusters from ESXi 5.1 to 5.5 Update 2 and have come across a bug whereby the vMotion of VMs ...
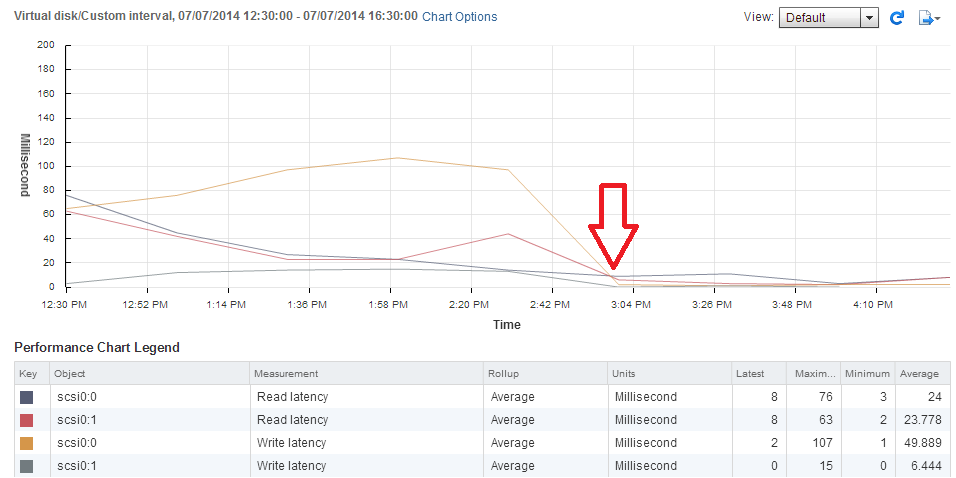
There is another NFS bug hidden in the latest ESXi 5.x releases...while not as severe as the 5.5 Update 1 NFS Bug it's been the cause of increased Virtual Di...
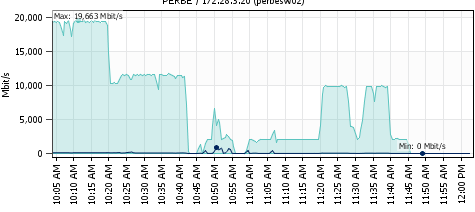
We have been conducting performance and stress testing of a new NFS connected storage platform over the past month or so and through that testing we have see...
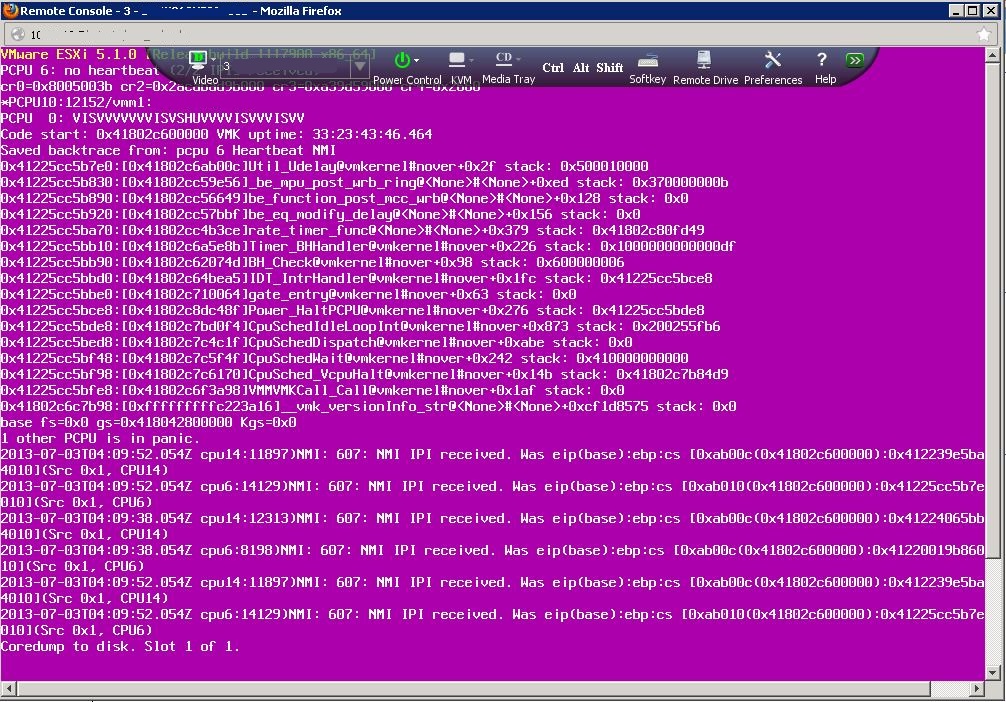
This is a quick informational post to warn anyone running an Emulex based 10GbE Converged Ethernet adapter in an IBM Blade Center with HS23 Series Blade serv...
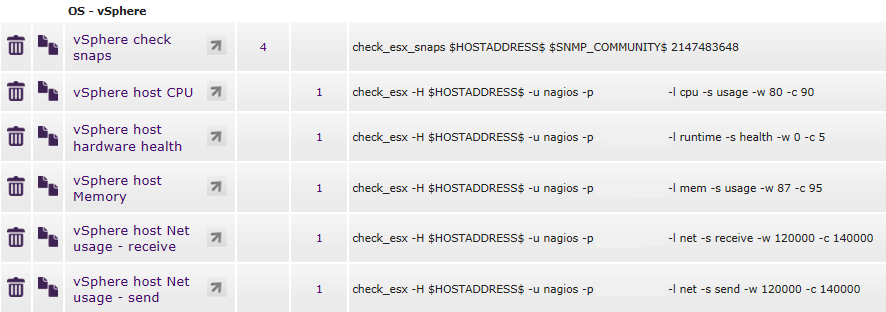
Unless my Google skills are seriously on the decline I wasn't able to find a definitive post on correctly setting up a nagios user to facilitate esx_chec...