
v11 For Service Providers - Extending Cloud Based Object Storage for Longer Term Retention
When Veeam Backup & Replication v11 went Generally Available on the 24th of February I posted the What’s in it for Service Providers blog. In that post I briefly outlined all the new features and enhancements in v11 as it related to our Veeam Cloud and Service Provider Partners. As mentioned each new major feature and enhancement listed below deserves its own seperate post. While these posts are targeted at Service Providers, the majority of these features can be levered by all types of organizations. In this post I am diving into our third expansion of Object Storage support for the Scale Out Backup Repository, which in v11, adds a new tier and also adds support for Google Cloud Storage…plus more! As a reminder here are the top new features and enhancements in Backup & Replication v11 for VCSPs (with links as created)
- Linux Backup Proxy Enhancements and other Linux Enhancements
- Data Integration API Enhancements supporting more platforms
- Continuous Data Protection for VMware Platforms
- VMware Cloud Director to Cloud Director Replication
- VMware Cloud Director Native HTML5 Tenant Portal, SSP Enhancements and 10.2 Support
- Archive Tier, Object Storage and other SOBR Enhancements
- Hardened Linux Repository for Immutability on Primary Landing Zones
- New PowerShell Module and RESTful API
- Enhanced Linux File-Level Recovery
- Veeam Agents for Windows and Linux v5.0 and Agent for Mac v1.0
Adding Archive Tier to the Scale Out Backup Repository
With v11 we have added a third tier to the Scale Out Backup Repository. The Archive Tier is backed my Amazon S3 Glacier or Microsoft Azure Blob Archive. This third tier is all about moving the bulk of backup data off to super cheap storage for long term retention. The idea here is that you shouldn’t have to access the data, once moved into the Archive Tier almost ever. This allows the Performance Tier landing zone to be for short term backups and the Capacity Tier now becomes a medium to longer term storage repository.
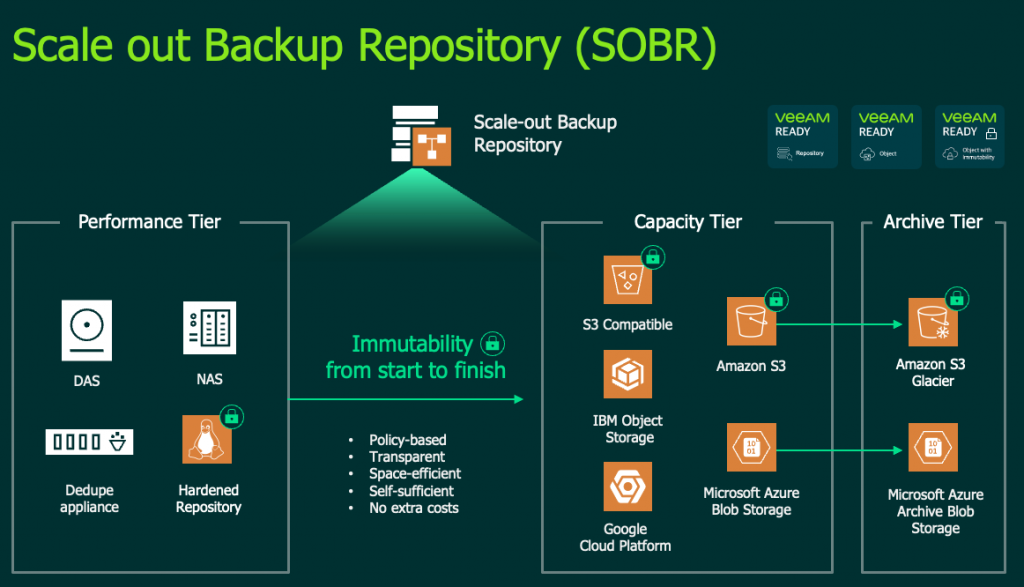
Public Cloud Only Use Case
It is important to point out straight away that you can’t mix and match on-premises Object Storage with Glacier or Blob Archive… that is to say, that if you want to take advantage of the Archive Tier, you will need a SOBR configured with the Object Storage Repository backing the Capacity Tier being of type Amazon or Azure. Data can only be moved from the Capacity Tier to the Archive Tier by going from Amazon S3 to Glacier, or from Azure Blob to Azure Blog Archive. As part of the conversion/move process between Capacity Tier and Archive Tier we deploy a temporary Proxy Appliance into AWS or Azure to undertake the move process which converts blocks to larger object for more efficient storage. There is one temporary proxy per backup chain, so depending on the policy process, multiple proxies could be spun up. There is block cloned de-dupe available for storage but we allow the storing of achieved backups as standalone fulls as well. Benefits here is a longer term self contained backup over what amounts to forward incrementals. The negative is greater cost that comes with the larger storage footprint.
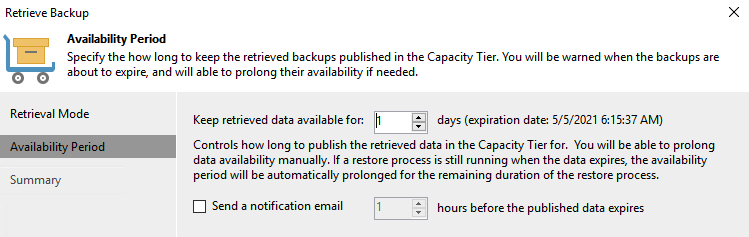
Trade Off on Retrieval Time and Costs
The trade off that comes with bulk longer term backup data at much cheaper storage rates is the fact that there is a penalty on time and cost to retrieve the data. I’m not going to go through the specifics of the cost differences but when a backup is required to be pulled back from the Capacity Tier, we give three options as seen below.
 From there, we stage the data from the Archive Tier, into the Capacity Tier. It is kept there for a period of time based on what is shown below and/or what is dictated by the time to restore the data from the Capacity Tier.
From there, we stage the data from the Archive Tier, into the Capacity Tier. It is kept there for a period of time based on what is shown below and/or what is dictated by the time to restore the data from the Capacity Tier.
Google Cloud Storage Support
For the Capacity Tier, you can now leverage Google Cloud Storage as the Object Storage platform. There really isn’t anything much to add here apart from the fact that this gives another Public Cloud option which can be translated to more service level classes for Service Providers. We support Standard and Nearline Storage Classes.

Other Enhancements
Apart from the above, we also added other enhancements to do with security, scalability and reliability.
- For the Archive Tier we can take advantage of Amazon S3’s Object Lock mechanisms to have the backups marked as immutable as they move to the Archive Tier Repository.
- Added VeeamZip and Export to .vbk support. These backups can be copied and moved to the Capacity and Archive Tiers
- We have introduced Load Management by limited concurrent tasks against the Object Storage Repository. This is more for on-premises S3 platforms and looks to reduce CPU and RAM overheads.
- Added support for Amazon Snowball Edge (technically a 10a addition)
Benefit to Service Providers
Building on the Capacity Tier Move and Copy functionality, the addition of the Archive Tier allows Service Providers to further differentiate storage offerings for their BaaS or IaaS Backups. I have been preaching this to VCSPs since we released 9.5 Update 4. My argument is that where possible, a fundamental shift in how backup repositories are architected and designed occurs. Reducing the size of the primary landing zone by being able to take advantage of faster storage types for super quick restores by having the bulk of your backup points on Object Storage extents. The Capacity Tier can now be classified as a place to store medium term backup points with the Archive Tier used to store long term points that might never be touched. With the addition of Move, Copy functions as well as the Immutability option, VCSPs can create multiple levels of Backup Storage Classes at graduating prices which gives their customers more choice and also more potential revenue.
Content and Materials https://helpcenter.veeam.com/docs/backup/vsphere/archive_tier.html?ver=110https://helpcenter.veeam.com/docs/backup/powershell/sobr_archive_tier.html?ver=110 https://anthonyspiteri.net/v11-adding-archive-tier/
6 Commentsarchived