
v11 For Service Providers - Activating More Data Integration API Enhancements
When Veeam Backup & Replication v11 went Generally Available on the 24th of February I posted the What’s in it for Service Providers blog. In that post I briefly outlined all the new features and enhancements in v11 as it related to our Veeam Cloud and Service Provider Partners. As mentioned each new major feature and enhancement listed below deserves its own seperate post. In this post I am looking at the enhancements with the Data Integration API as we offer the ability to mount and activate data that otherwise sits stagnant in backup repositories. As a reminder here are the top new features and enhancements in Backup & Replication v11 for VCSPs (with links as created)
- Linux Backup Proxy Enhancements and other Linux Enhancements
- Data Integration API Enhancements supporting more platforms
- Continuous Data Protection for VMware Platforms
- VMware Cloud Director to Cloud Director Replication
- VMware Cloud Director Native HTML5 Tenant Portal, SSP Enhancements and 10.2 Support
- Archive Tier, Object Storage and other SOBR Enhancements
- Hardened Linux Repository for Immutability on Primary Landing Zones
- New PowerShell Module and RESTful API
- Enhanced Linux File-Level Recovery
- Veeam Agents for Windows and Linux v5.0 and Agent for Mac v1.0
What is the Data Integration API
The Data Integration API isn’t consumed as an API from an endpoint but can only be run via a set of PowerShell commandlets .This feature is all about the activation of data, the presentation of that data and then, the manipulation of that data to reach some outcome. Basically it’s about making the data remain valuable, when once is was locked away and only required in times of disaster. in v10, the Data Integration API allowed you to represent data of backup files as a mounted Windows folder. You can take a restore point of the backup file, mount it as a Windows folder and access application data that is available in the backup created by Veeam Backup & Replication. This was one of my favourite features that was (https://anthonyspiteri.net/vcsp-important-notice-v10-rtm-is-out-with-cloud-tier-object-storage-enhancements-and-more/). The ability to mount volumes instantly also means there is no time wasted in waiting for what could be long a recovery process and you don’t need to worry about additional storage as the data is read directly from the backup repositories. This technology worked natively with Windows based volumes as we are mounting a volumes via iSCSI to a remote or local Windows Server. When it comes to Linux, the mounting of the volume will still happen, but reading the data in the mounted restore point required a final workaround step as I documented (https://anthonyspiteri.net/linux-data-integration-api/).
Enhancing The Data Integration API in v11
In v11, the Data Integration API has these additional capabilities
- Mount Backups to Linux Servers leveraging FUSE
- Mount all image-based backups including
- VMware Cloud Director
- Veeam Backup for AWS and Azure
- Nutanix AHV
Having a look below at an example, I have run a series of PowerShell commands to mount the latest backup for a Virtual Machine from a VMware Cloud Director Job targeting a Linux server that is under management in Backup & Replication.
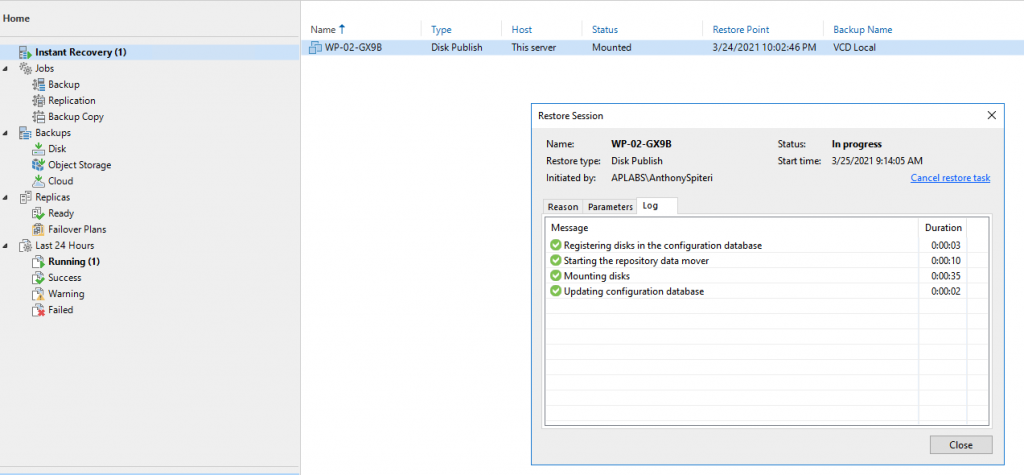 Once complete, on the Linux server we can see the mounted backup data as shown below.
Once complete, on the Linux server we can see the mounted backup data as shown below.
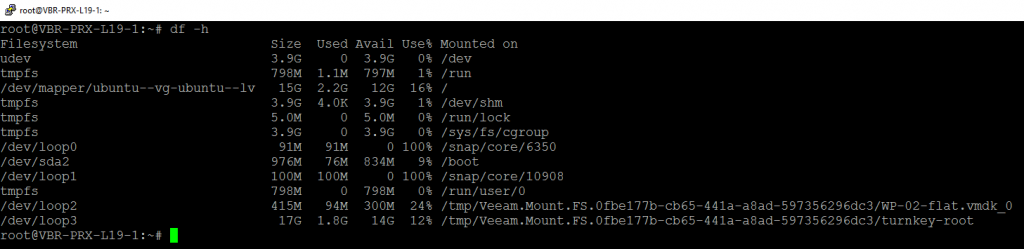 There are two mounts presented, one with the disks as this is effectively a Disk Publishing mechanism. The other mount presented is the actual file system contained in the backup.
There are two mounts presented, one with the disks as this is effectively a Disk Publishing mechanism. The other mount presented is the actual file system contained in the backup.
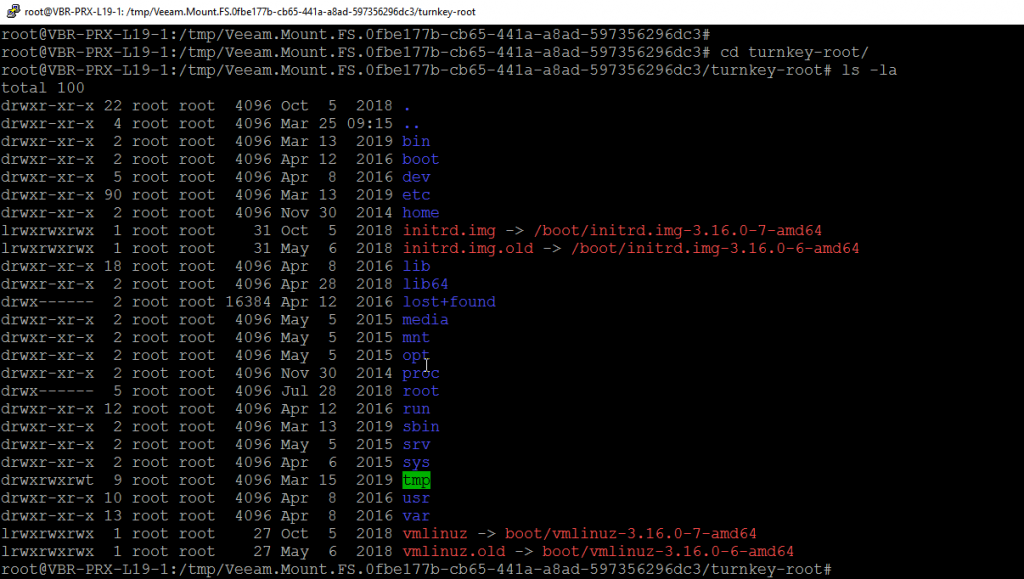
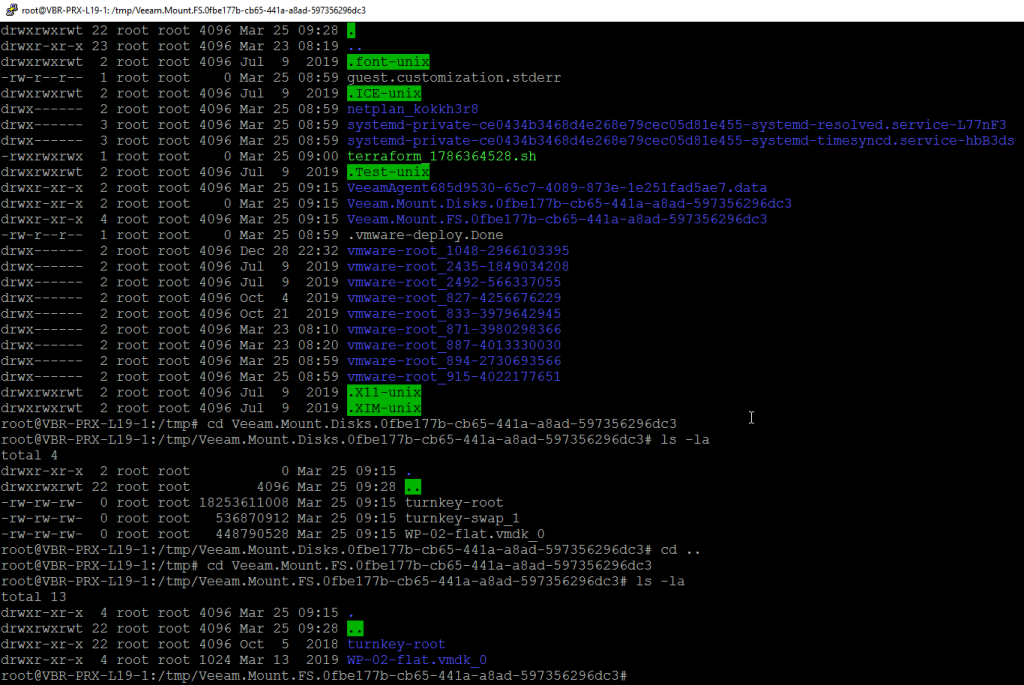 Getting to the File System Mount folder we can see the point in time instance of the Virtual Machines file system ready for manipulation. It is worth pointing out that this is not a Read Only mount and you can add and delete files and folders. Changes are not written back to the backup repository once the mount session has been terminated.
Getting to the File System Mount folder we can see the point in time instance of the Virtual Machines file system ready for manipulation. It is worth pointing out that this is not a Read Only mount and you can add and delete files and folders. Changes are not written back to the backup repository once the mount session has been terminated.
Benefit to Service Providers
As I have talked about since the v10 release, this presented Service Providers with the ability to offer services around data reuse and activation. I often talk about this as the ability to do “stuff” with the data once it has been mounted from via the API. A great example of this is running some form of proactive, non invasion security checks on data contained within the backups with some 3rd part tool or service. The ability now in v11 to extend this functionality for all image-based backups, but more importantly VMware Cloud Director means VCSPs can get creative in offering new services based on the feature. The addition of Linux is also important as there is now a native, direct way to mount Linux workloads with the added benefit of levering Linux based 3rd Party tooling for scanning and security.
Data Integration API Blog Posts and Working POCs
https://www.veeam.com/blog/v10-data-integration-api.html https://forums.veeam.com/powershell-f26/data-integration-api-getting-started-t64939.html https://foonet.be/2020/02/20/veeam-backup-replication-v10-data-integration-api-example/ https://benyoung.blog/getting-started-with-the-veeam-data-integration-api/ https://benyoung.blog/machine-learning-on-your-veeam-backups-sure-via-the-data-integration-api/
3 Commentsarchived