Cloud Tier Data Migration between AWS and Azure... or anywhere in between!
At the recent Cloud Field Day 5 (CFD#5) I presented a deep dive on the Veeam Cloud Tier which was released as a feature extension of our Scale Out Backup Repository (SOBR) in Update 4 of Veeam Backup & Replication. Since we went GA we have been able to track the success of this feature by looking at Public Cloud Object Storage consumption by Veeam customers using the feature. As of last week Veeam customers have been offloading petabytes of backup data into Azure Blob and Amazon S3…not counting the data being offloaded to other Object Storage repositories. During the Cloud Field Day 5 presentation, Michael Cade talked about the Portability of Veeam’s data format, around how we do not lock our customers into any specific hardware or format that requires a specific underlying File System. We offer complete Flexibility and Agnosticity where your data is stored and the same is true when talking about what Object Storage platform to choose for the offloading of data with the Cloud Tier. I had a need recently to setup a Capacity Tier extent that was backed by an Object Storage Repository on Azure Blob. I wanted to use the same backup data that I had in an existing Amazon S3 backed Capacity Tier while still keeping things clean in my Backup & Replication console…luckily we have built in a way to migrate to a new Object Storage Repository, taking advantage of the innovative tech we have built into the Cloud Tier.
Cloud Tier Data Migration:
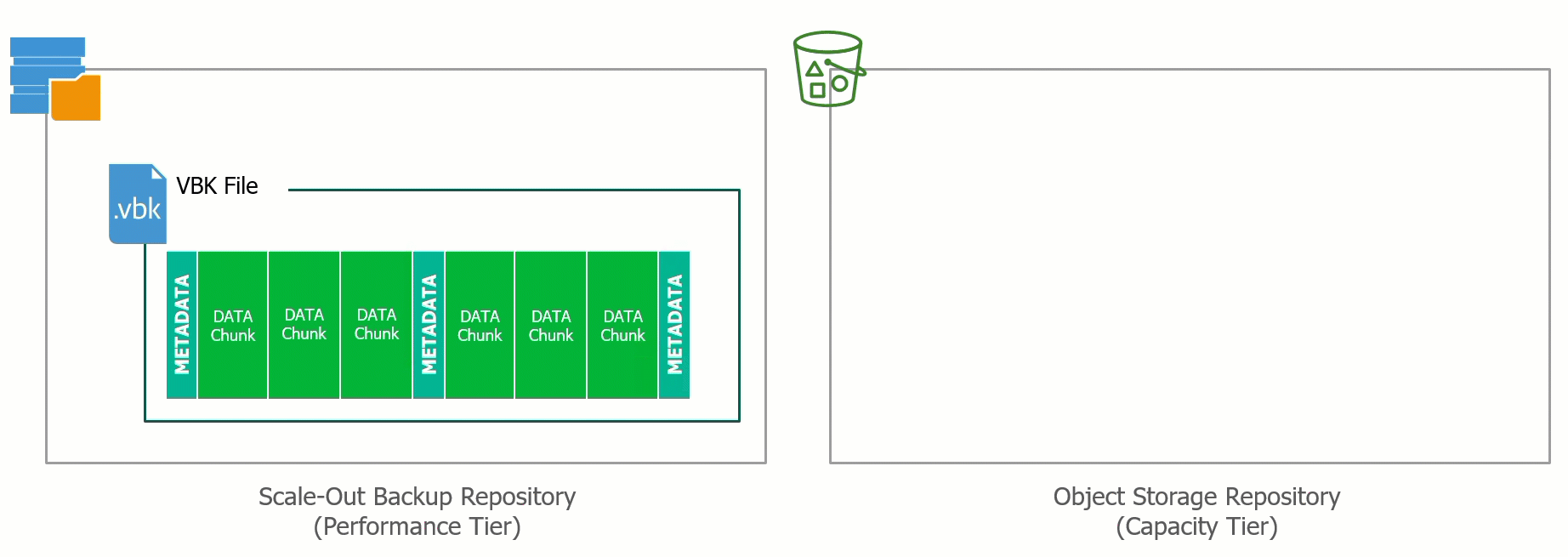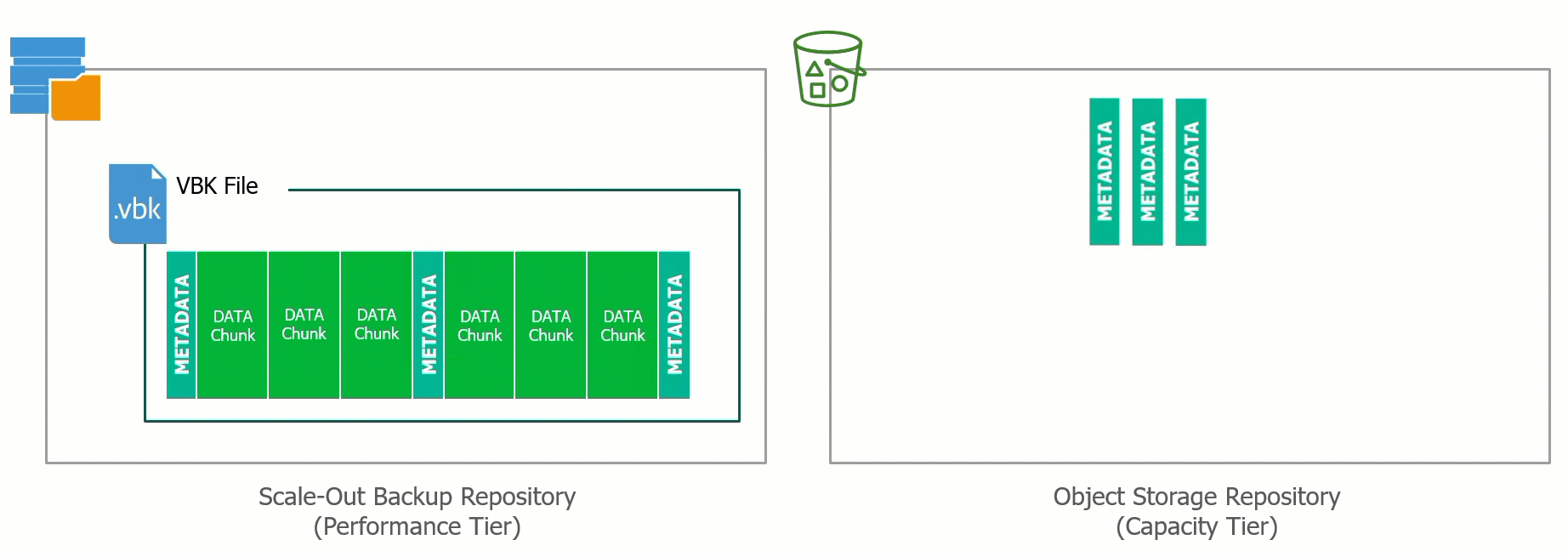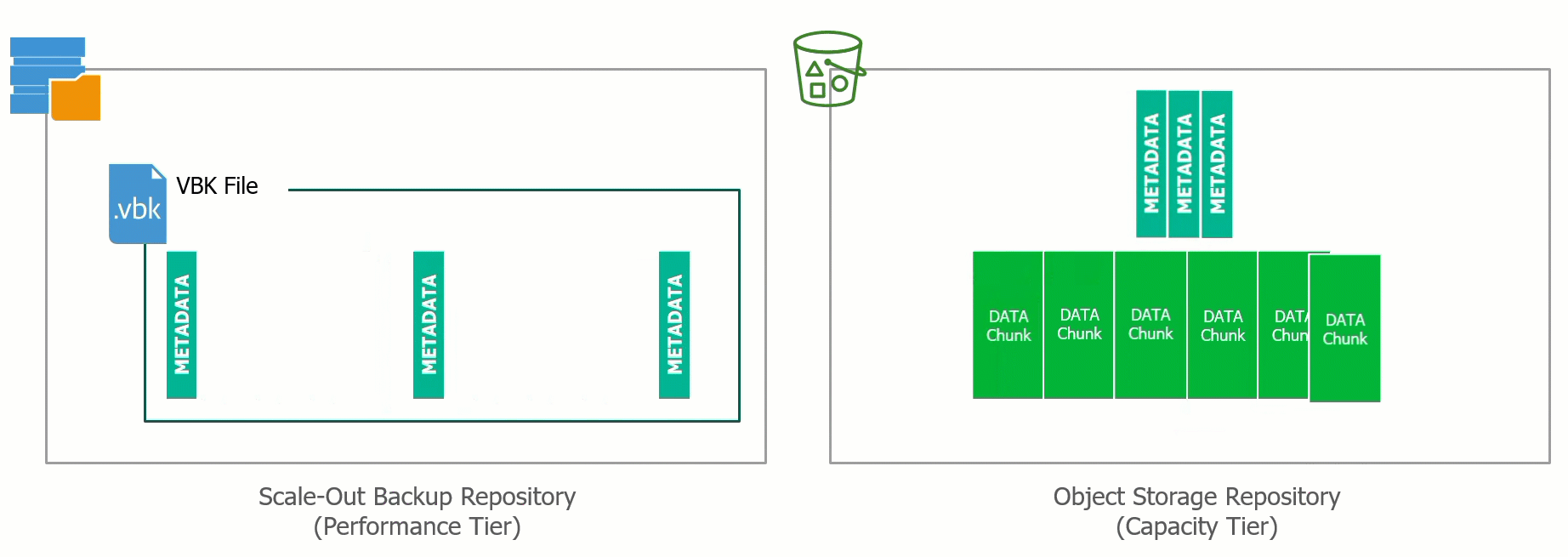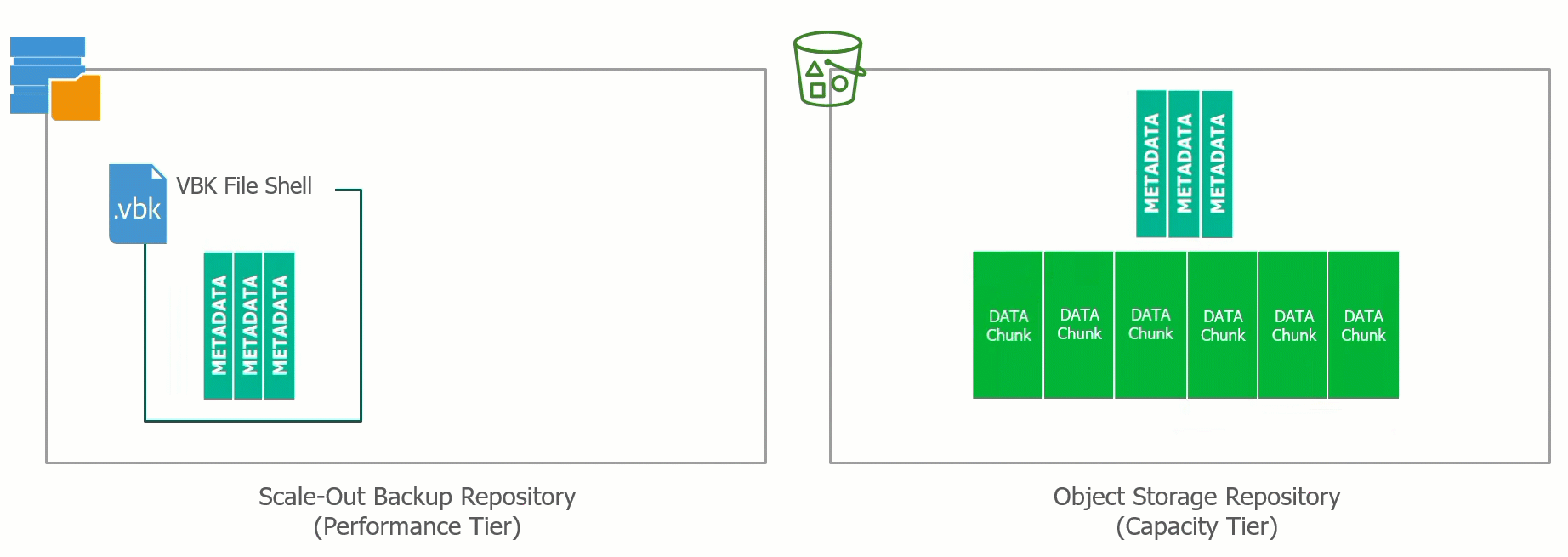
During the offload process data is tiered from the Performance Tier to the Capacity Tier effectively Dehydrating the VBK files of all backup data only leaving the metadata with an Index that points to where the data blocks have been offloaded into the Object Storage.
This process can also be reversed and the VBK file can be rehydrated. The ability to bring the data back from Capacity Tier to the Performance Tier means that if there was ever a requirement to evacuate or migrate away from a particular Object Storage Provider, the ability to do so is built into Backup & Replication.
In this small example, as you can see below, the SOBR was configured with a Capacity Tier backed by Amazon S3 and using about 15GB of Object Storage.
 The first step is to download the data back from the Object Storage and rehydrate the VBK files on the Performance Tier extents.
There are two ways to achieve the rehydration or download operation.
The first step is to download the data back from the Object Storage and rehydrate the VBK files on the Performance Tier extents.
There are two ways to achieve the rehydration or download operation.
- Via the Backup & Replication Console
- Via a PowerShell Cmdlet
Rehydration via the Console:
From the Home Menu under Backups right click on the Job Name and select Backup Properties. From here there is a list of the Files contained within the job and also the objects that they contain. Depending on where the data is stored (remembering that the data blocks are only even in one location… the Performance Tier or the Capacity Tier) the icon against the File name will be slightly different with files offloaded represented with a Cloud.
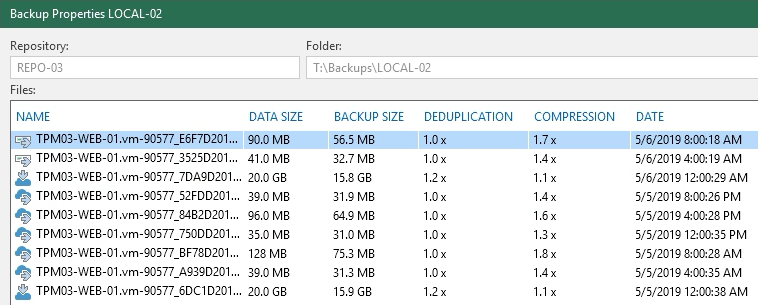 Right Clicking on any of these files will give you the option to Copy the data back to the Performance Tier. You have the choice to copy back the backup file or the backup files and all its dependancies.
Right Clicking on any of these files will give you the option to Copy the data back to the Performance Tier. You have the choice to copy back the backup file or the backup files and all its dependancies.
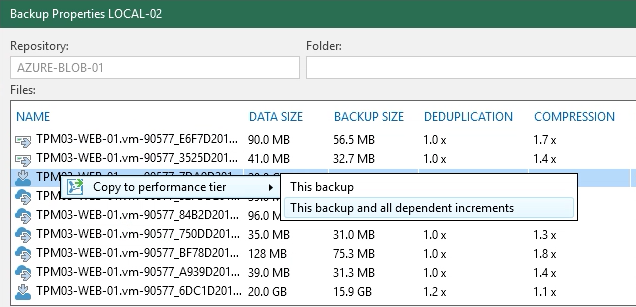 Once this is selected, a SOBR Download job is kicked off and the data is moved back to the Performance Tier. It’s important to note that our Intelligent Block Recovery will come into play here and look at the local data blocks to see if any match what is trying to be downloaded from the Object Storage… if so it will copy them from the Performance Tier, saving on egress charges and also speeding up the process.
Once this is selected, a SOBR Download job is kicked off and the data is moved back to the Performance Tier. It’s important to note that our Intelligent Block Recovery will come into play here and look at the local data blocks to see if any match what is trying to be downloaded from the Object Storage… if so it will copy them from the Performance Tier, saving on egress charges and also speeding up the process.
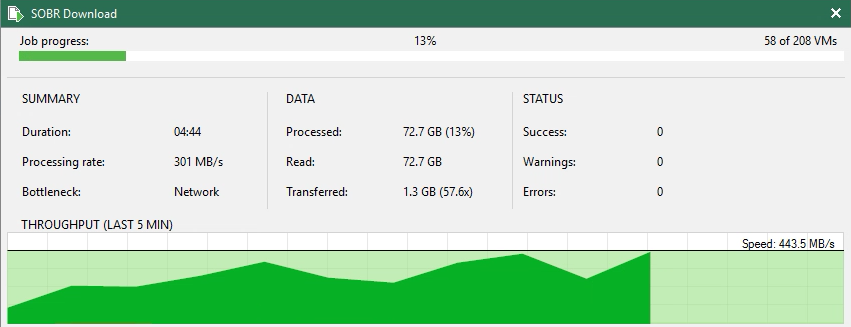
 In the image above you can see the Download Job working and only downloaded 95.5MB from Object Storage with 15.1GB copied from the Performance Tier… meaning the data blocks for the most that are local are able to be used for the rehydration.
The one caveat to this method is that you can’t select bulk files or multiple backup jobs so the process to rehydrate everything from the Capacity Tier can be tedious.
In the image above you can see the Download Job working and only downloaded 95.5MB from Object Storage with 15.1GB copied from the Performance Tier… meaning the data blocks for the most that are local are able to be used for the rehydration.
The one caveat to this method is that you can’t select bulk files or multiple backup jobs so the process to rehydrate everything from the Capacity Tier can be tedious.
Rehydration via PowerShell:
To solve that problem we can use PowerShell to call the Start-VBRDownloadBackupFile (https://helpcenter.veeam.com/docs/backup/powershell/object_storage_data_transfer.html?ver=95u4) to do the bulk of the work for us. Below are the steps I used to get the backup job details, feed that through to variable that contains all the file names, and then kick off the Download Job.
PS C:\> $backup = Get-VBRBackup -Name LOCAL-02
PS C:\> $files = Get-VBRBackupFile -Backup $backup
PS C:\> $files
Path Id
---- --
TPM03-WEB-01.vm-90577_E6F7D2019-05-06T080018.vib 3c117f7f-c00c-4604-a720-04ab3f852e29
TPM03-WEB-01.vm-90577_14C3D2019-05-04T000245.vbk 237bbf73-cbdb-47d0-a10f-12bcb33e5744
TPM03-WEB-01.vm-90577_BF78D2019-05-05T080028.vib 1b849c73-6e94-4f3c-a710-211a62c2898e
TPM03-WEB-01.vm-90577_7DA9D2019-05-06T000254.vbk e685fa44-0bd3-4548-b473-30914d03ca88
TPM03-WEB-01.vm-90577D2019-05-06T120021_852F.vib 77957ade-0a28-4a3f-ac3f-329b5d9bd302
TPM03-WEB-01.vm-90577_52FDD2019-05-05T200026.vib a16b6e7e-f85e-4aee-b888-36dd172781d9
TPM03-WEB-01.vm-90577_2A5CD2019-05-04T200022.vib 8ede425c-b82b-4f18-9edc-4099d49b3267
TPM03-WEB-01.vm-90577_F346D2019-05-04T120017.vib 2a596d08-7638-41aa-8dcb-523d8e4a8ccc
TPM03-WEB-01.vm-90577_84B2D2019-05-05T160028.vib 3c3d37b3-125e-4e21-9862-726c5d38655f
TPM03-WEB-01.vm-90577_750DD2019-05-05T120035.vib d0a5bfee-926b-45ca-9413-7eed6ebbae11
TPM03-WEB-01.vm-90577_BA36D2019-05-04T160028.vib 156aa82d-cd0c-4f8b-8cbb-8e85d03e972d
TPM03-WEB-01.vm-90577_DFF4D2019-05-04T040030.vib f77e8b6b-4a05-4891-96ea-a4e6a4a7d0aa
TPM03-WEB-01.vm-90577_A939D2019-05-05T040035.vib a50f7b4b-95eb-43ed-b259-a76f1e77461e
TPM03-WEB-01.vm-90577_3525D2019-05-06T040019.vib 23ac4b0a-8b05-41f5-9f58-bf33641c1b0e
TPM03-WEB-01.vm-90577_6DC1D2019-05-05T000324.vbk 56917a68-a862-4677-99bb-cdd792992096
TPM03-WEB-01.vm-90577_75BBD2019-05-04T080029.vib 21f3ed5d-474b-48ba-8914-eb0bb518e239
PS C:\> Start-VBRDownloadBackupFile -BackupFile $files -ThisBackupAndIncrements
CreationTime : 5/6/2019 2:42:26 PM
EndTime : 5/6/2019 2:42:32 PM
JobId : 3f86363c-5821-4d48-8764-a6192fc794a2
Result : Success
State : Stopped
Id : 6d1c4c11-549c-4452-85ad-252fde1d6181
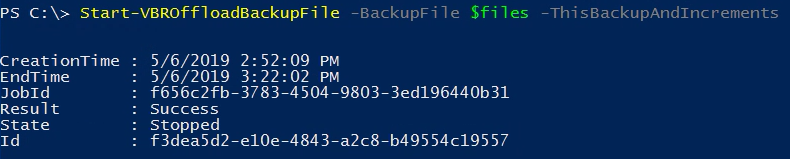
PS C:\> Start-VBROffloadBackupFile -BackupFile $files -ThisBackupAndIncrements
CreationTime : 5/6/2019 2:52:09 PM
EndTime : 5/6/2019 3:22:02 PM
JobId : f656c2fb-3783-4504-9803-3ed196440b31
Result : Success
State : Stopped
Id : f3dea5d2-e10e-4843-a2c8-b49554c19557The PowerShell window will then show the Download Job running
Completing the Migration:
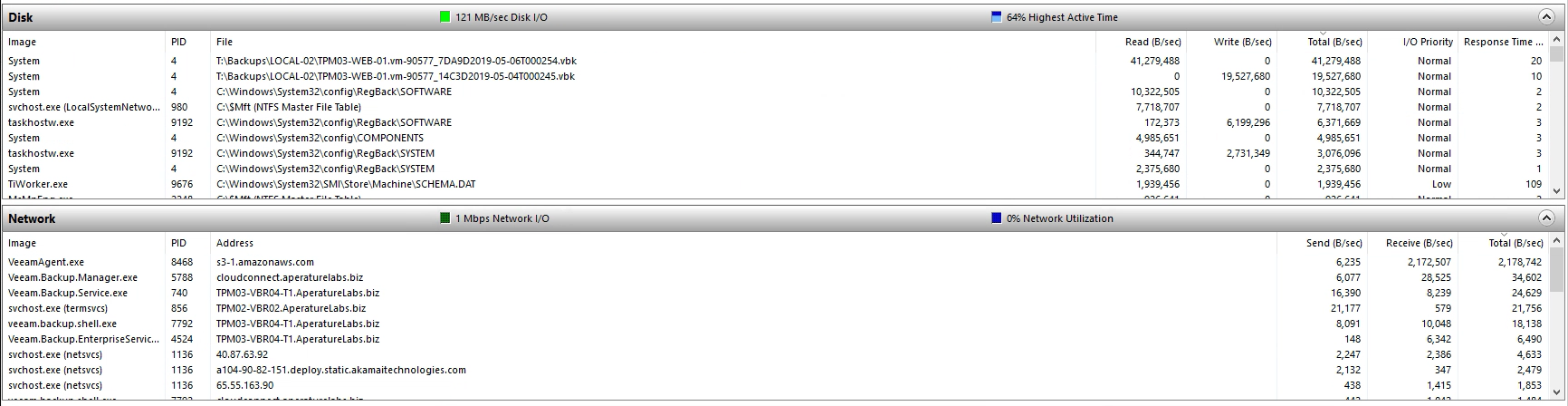
No matter which way the Download job is initiated, we can see the progress form the Backup & Replication Console under the Jobs section.
 And looking at the Disk and Network sections of Windows Resource Monitor we can see connections to Amazon S3 pulling the required blocks of data down.
And looking at the Disk and Network sections of Windows Resource Monitor we can see connections to Amazon S3 pulling the required blocks of data down.
 Once the Download job has been completed and all VBKs have been rehydrated, the next step is to change the configuration of the SOBR Capacity Tier to point at the Object Storage Repository backed by Azure Blob.
Once the Download job has been completed and all VBKs have been rehydrated, the next step is to change the configuration of the SOBR Capacity Tier to point at the Object Storage Repository backed by Azure Blob.
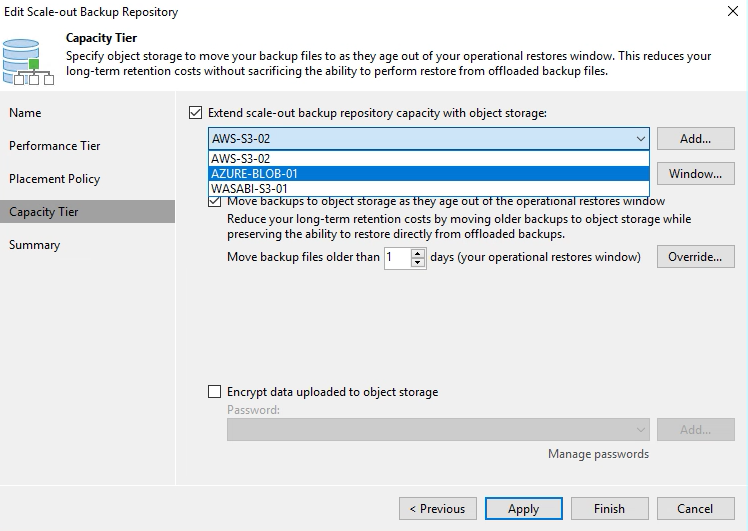
 The final step is to initiate an offload to the new Capacity Tier via an Offload Job…this can be triggered via the console or via Powershell (as shown in the last command of the PowerShell code above) and because we have already a set of data that satisfies the conditions for offload (sealed chains and backups outside the operational restore window) data will be dehydrated once again…but this time up to Azure Blob.
The final step is to initiate an offload to the new Capacity Tier via an Offload Job…this can be triggered via the console or via Powershell (as shown in the last command of the PowerShell code above) and because we have already a set of data that satisfies the conditions for offload (sealed chains and backups outside the operational restore window) data will be dehydrated once again…but this time up to Azure Blob.
 The used space shown below in the Azure Blob Object Storage matches the used space initially in Amazon S3
The used space shown below in the Azure Blob Object Storage matches the used space initially in Amazon S3 All recovery operations show Restore Points on the Performance Tier and on the Capacity Tier as dictated by the operational restore window policy.
All recovery operations show Restore Points on the Performance Tier and on the Capacity Tier as dictated by the operational restore window policy.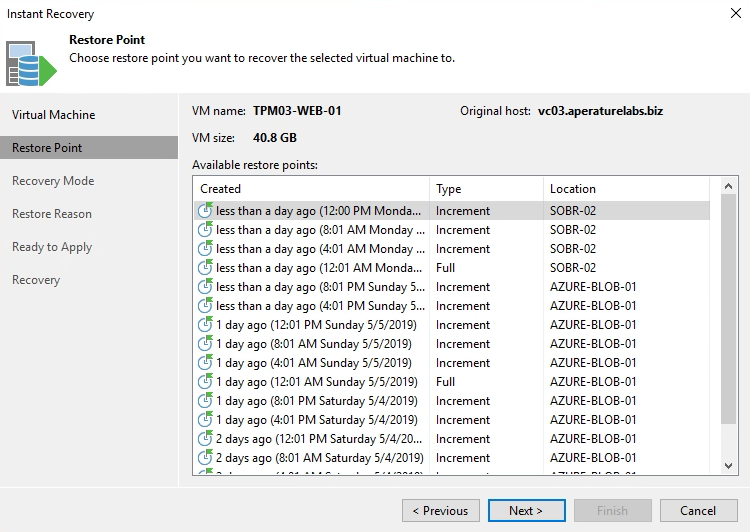 Conclusion:
As mentioned in the intro, the ability for Veeam customers to have control of their data is an important principal revolving around data portability. With the Cloud Tier we have extended that by allowing you to choose the Object Storage Repository of your choice for cloud based storage or Veeam backup data…but also given you the option to pull that data out and shift when and where desired. Migrating data between AWS, Azure or any platform is easily achieved and can be done without too much hassle.
References:
https://helpcenter.veeam.com/docs/backup/powershell/object_storage_data_transfer.html?ver=95u4
Conclusion:
As mentioned in the intro, the ability for Veeam customers to have control of their data is an important principal revolving around data portability. With the Cloud Tier we have extended that by allowing you to choose the Object Storage Repository of your choice for cloud based storage or Veeam backup data…but also given you the option to pull that data out and shift when and where desired. Migrating data between AWS, Azure or any platform is easily achieved and can be done without too much hassle.
References:
https://helpcenter.veeam.com/docs/backup/powershell/object_storage_data_transfer.html?ver=95u4