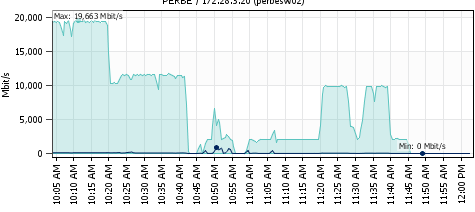
Veeam Data Cloud Vault V2: Cloud Backup for Resilient, Simplified, and Secure Data Protection
Back in 2014, I was fortunate to be part of the launch of Cloud Connect Backup in Veeam Backup & Replication when at Zettagrid , a great moment in cloud data...




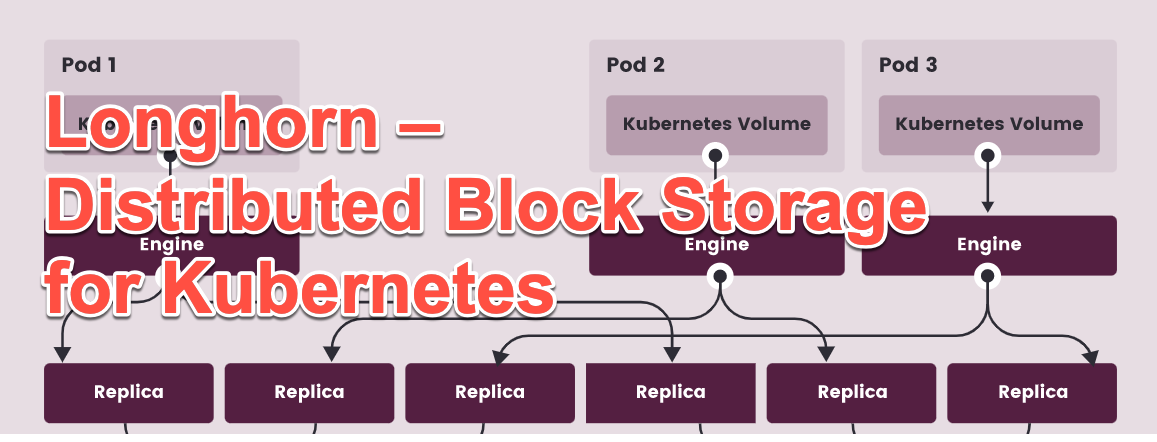


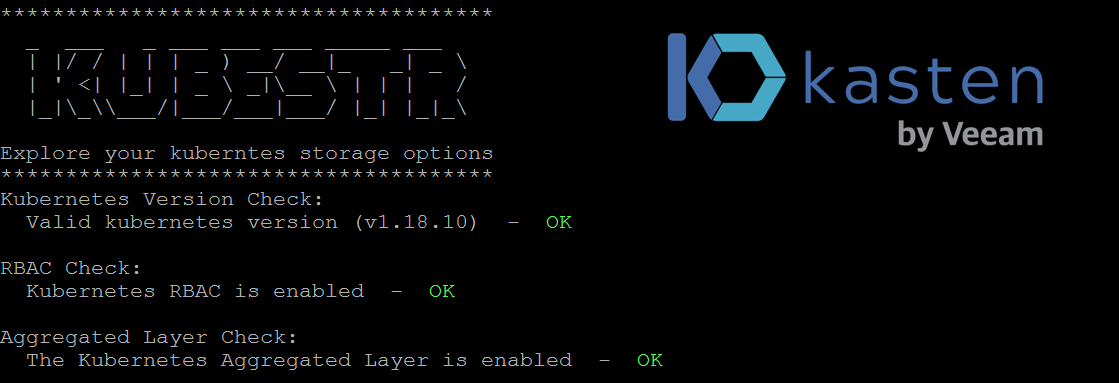


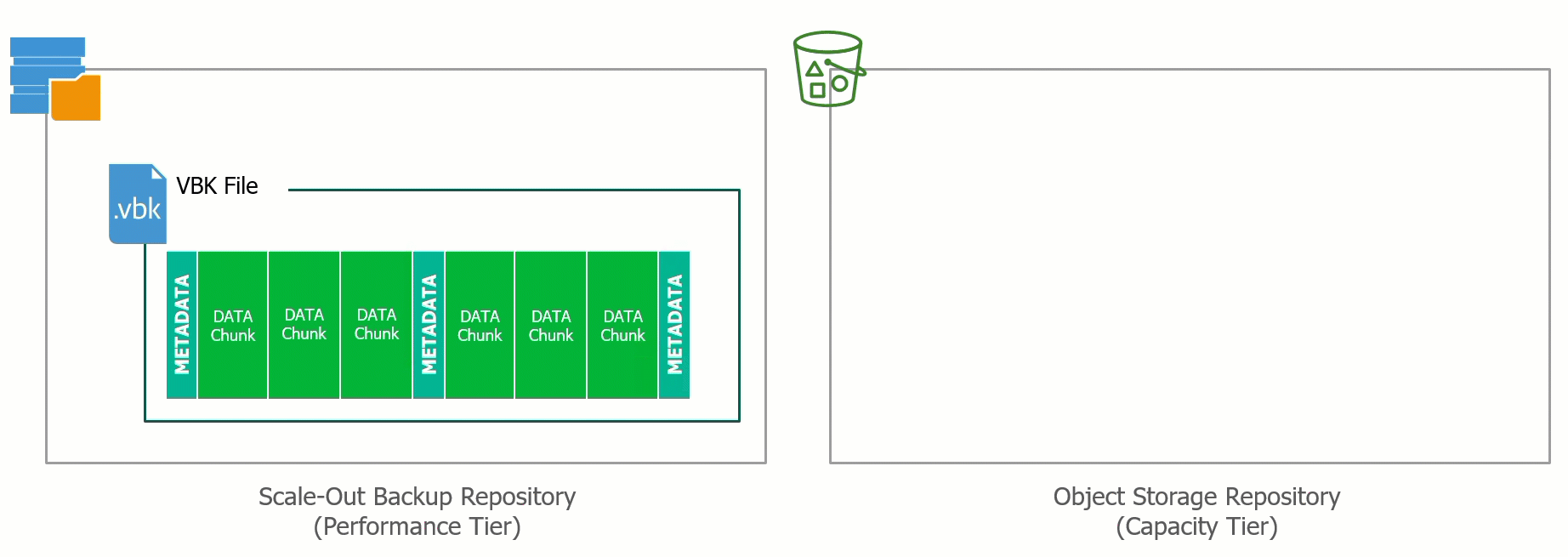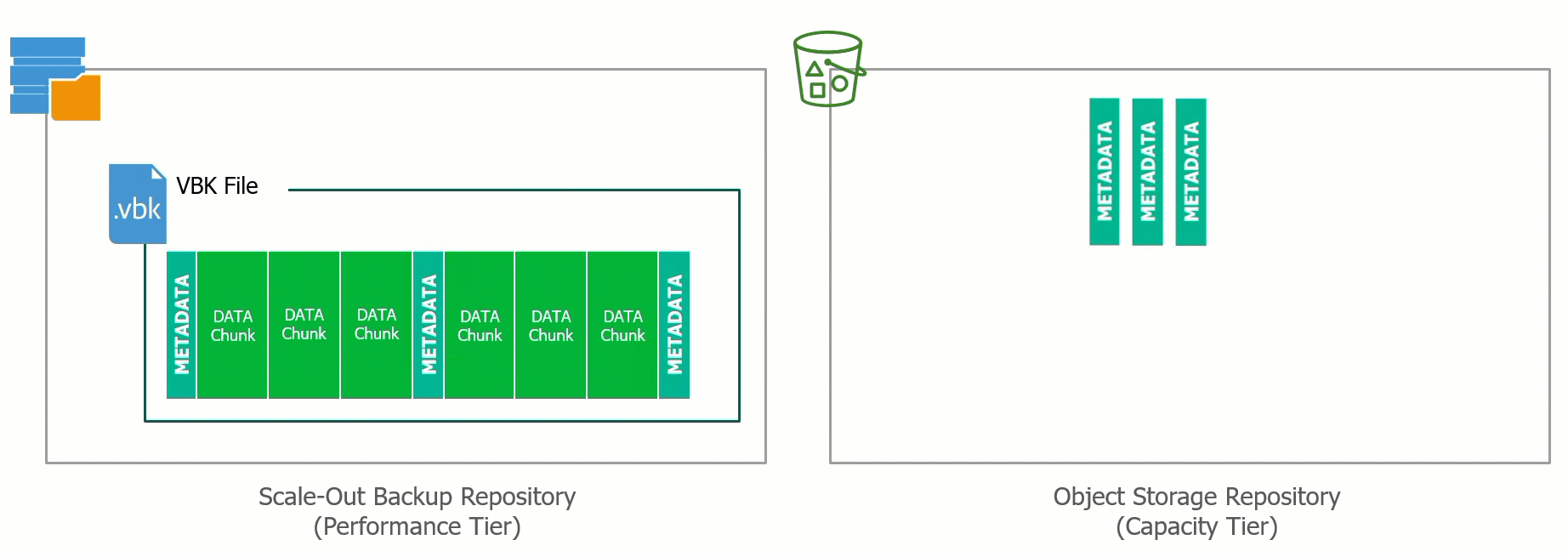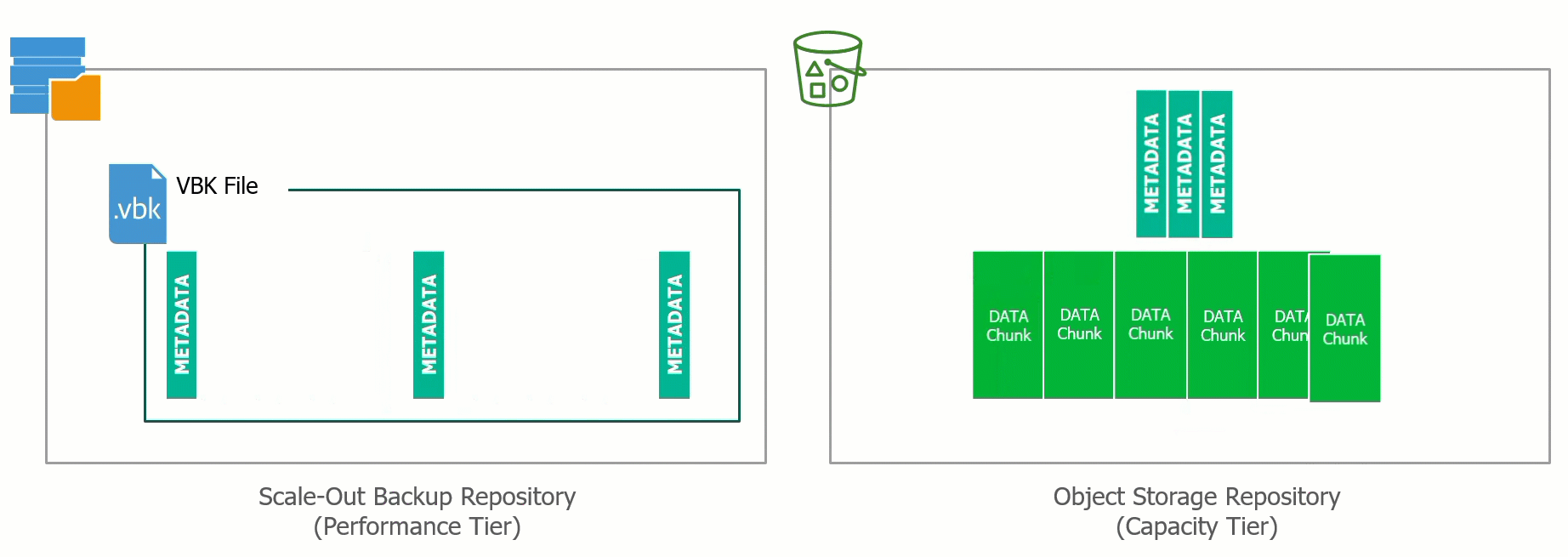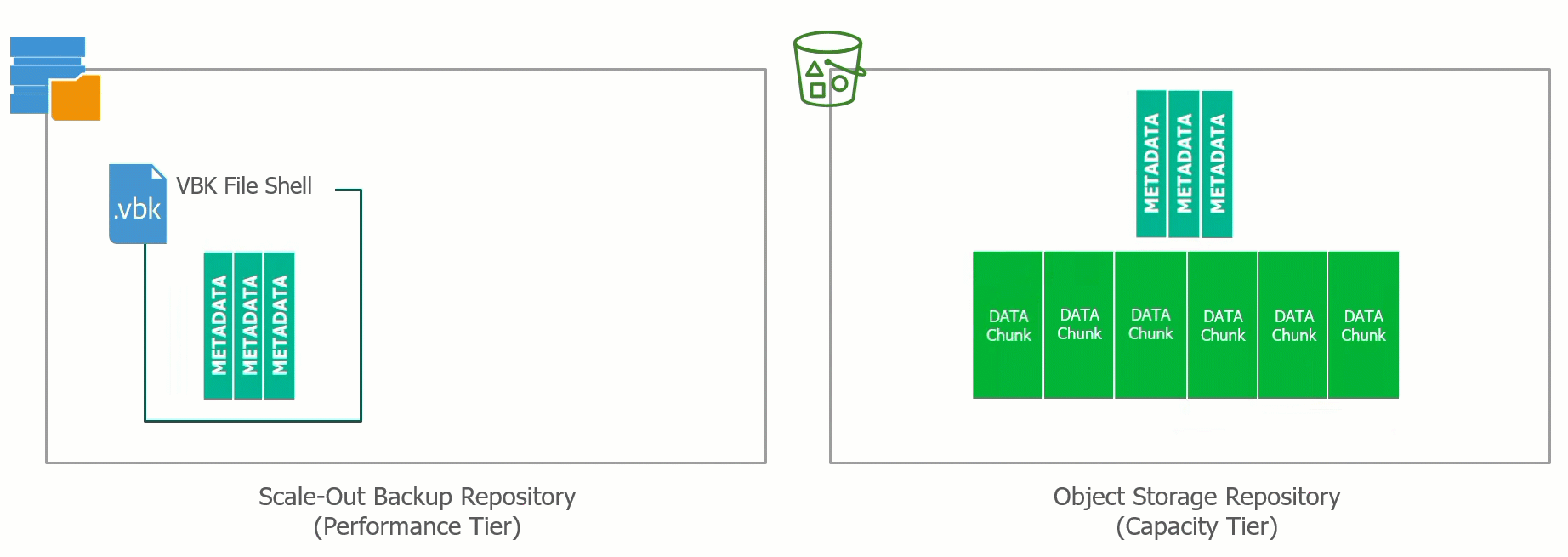
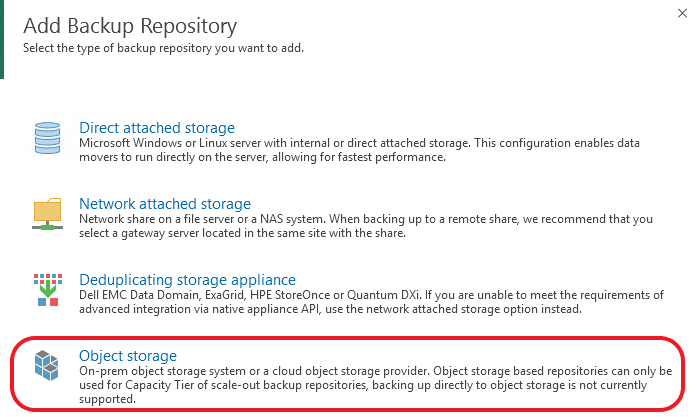
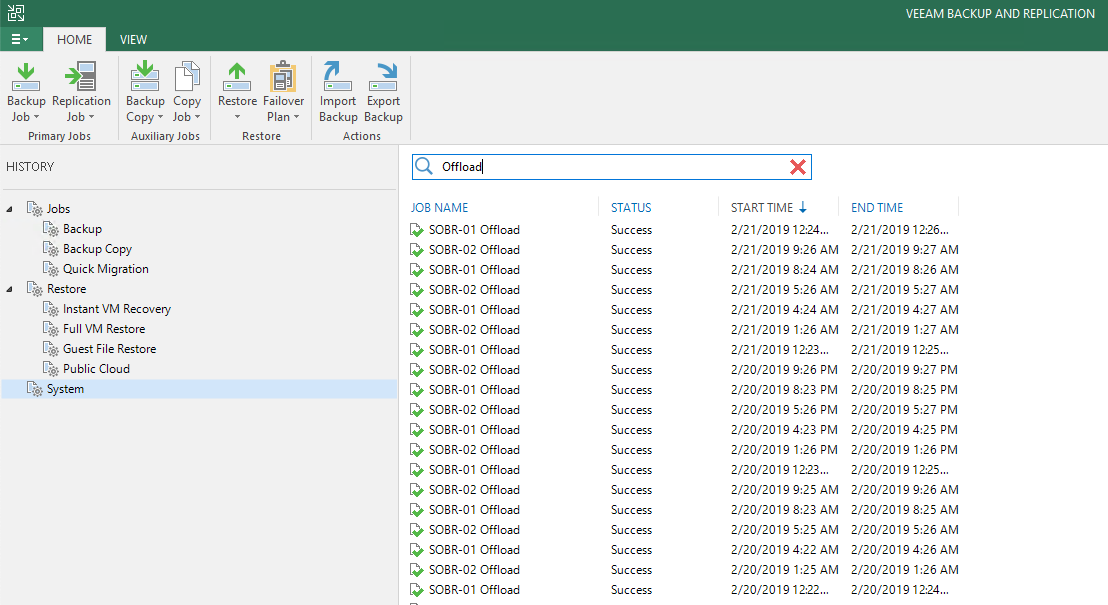
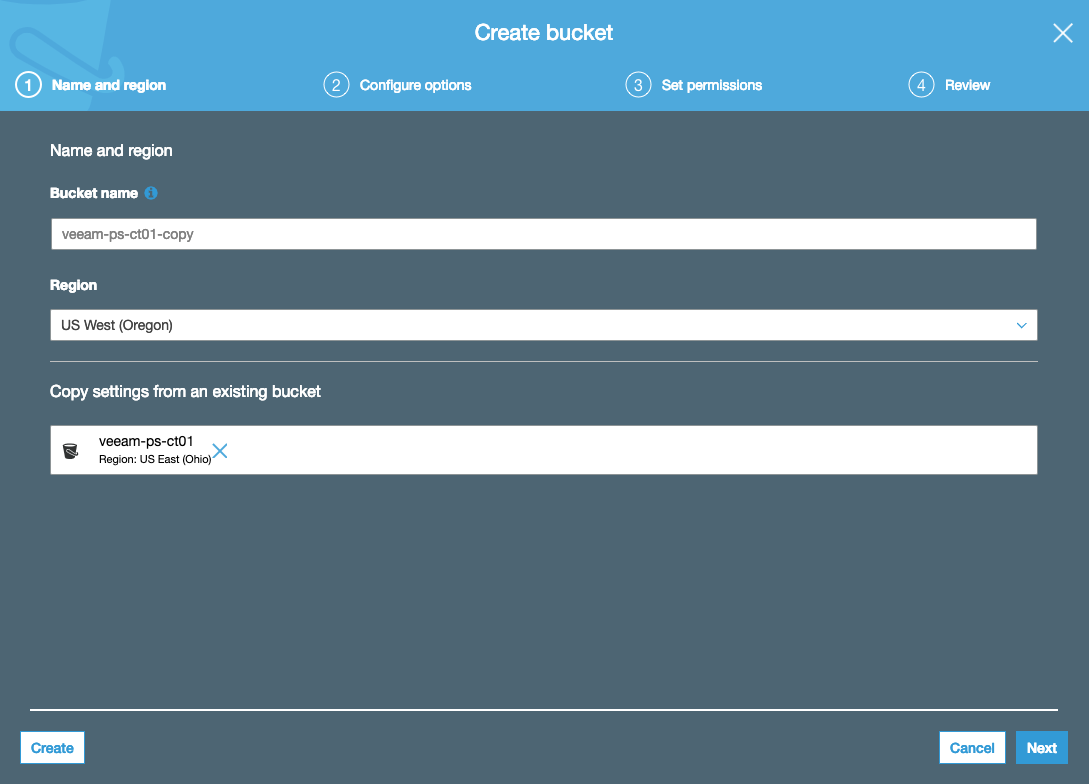
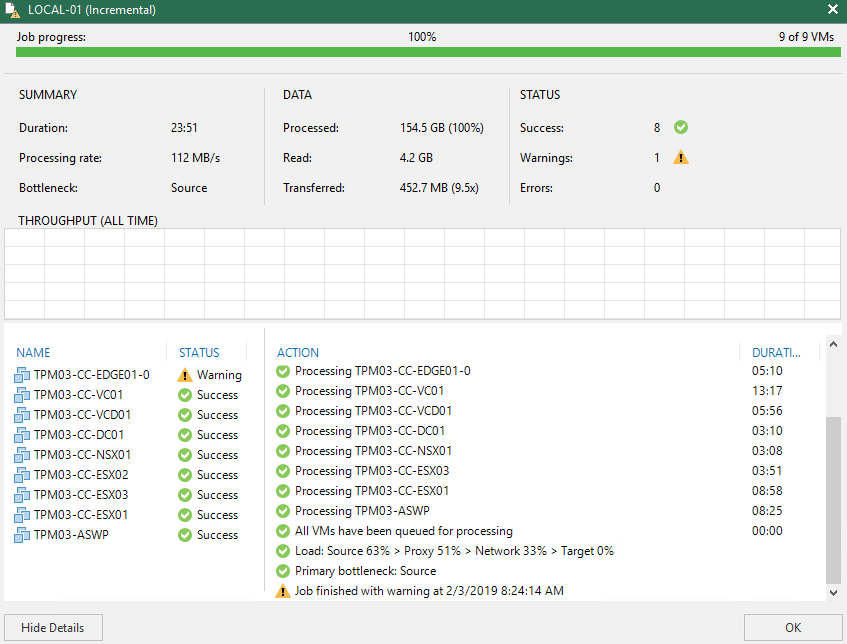

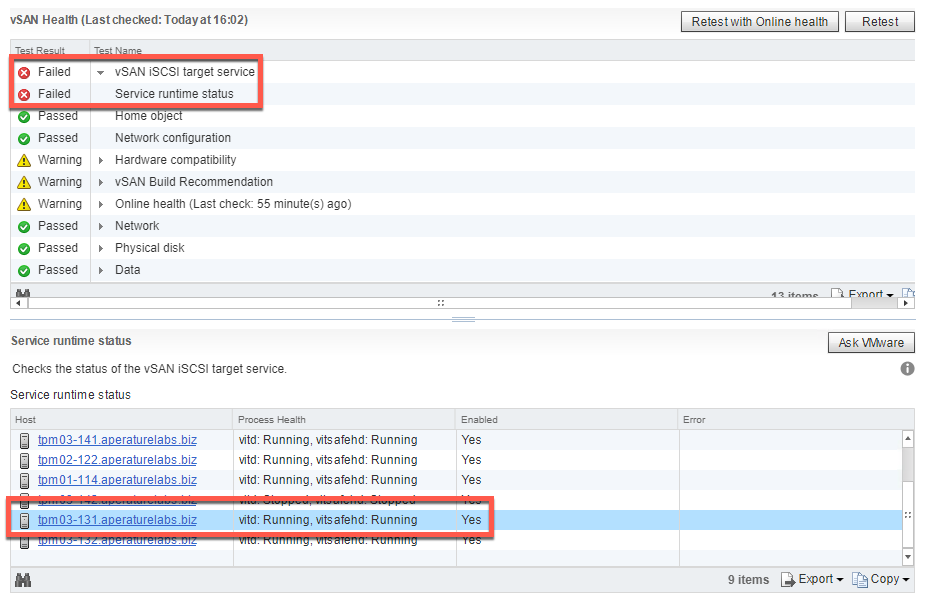




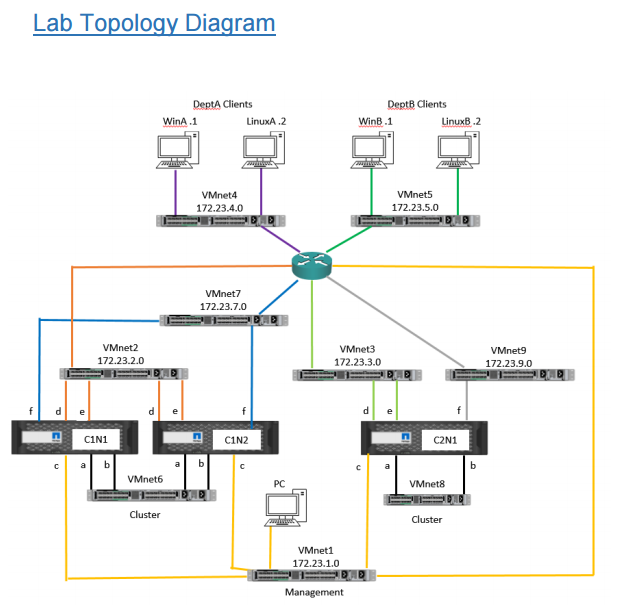
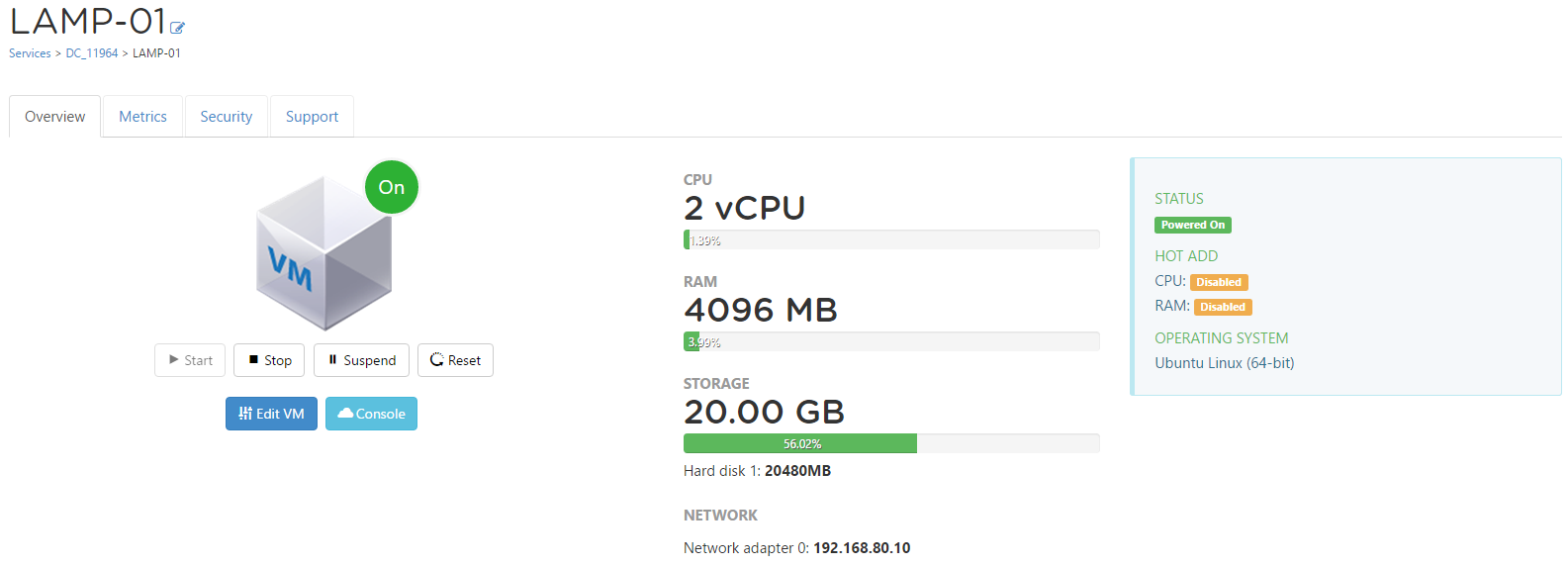

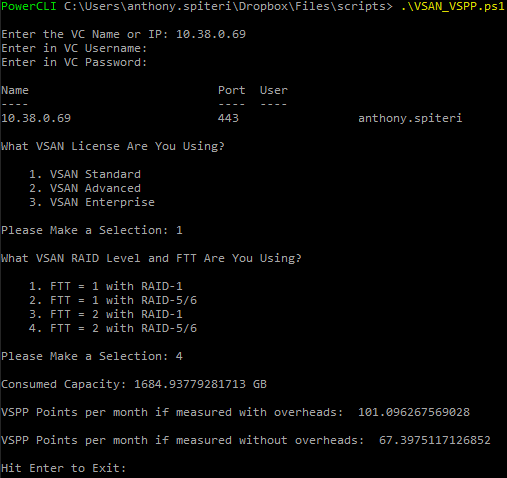

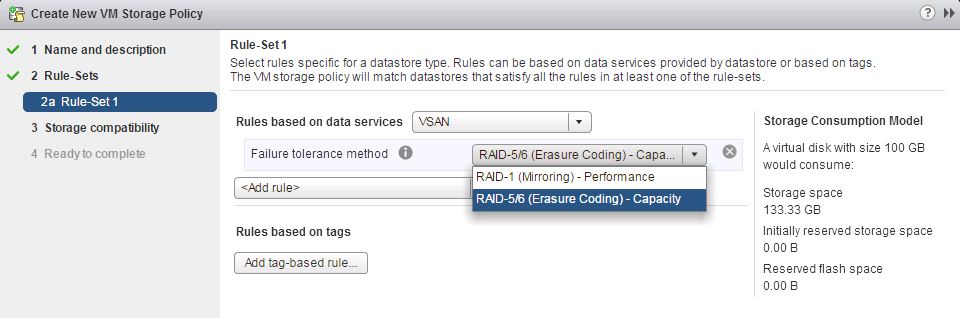
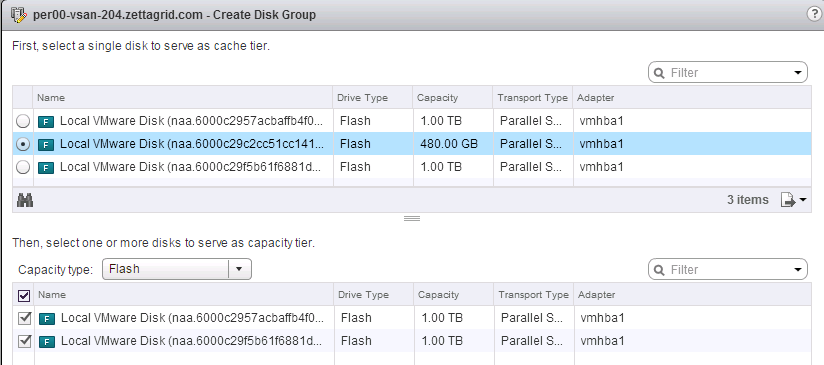
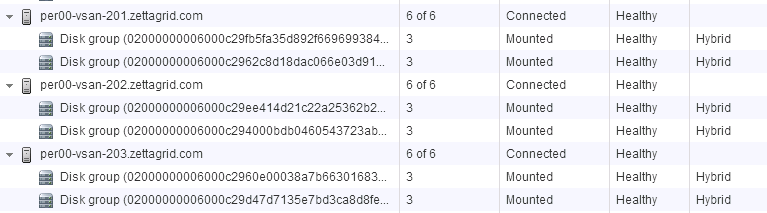

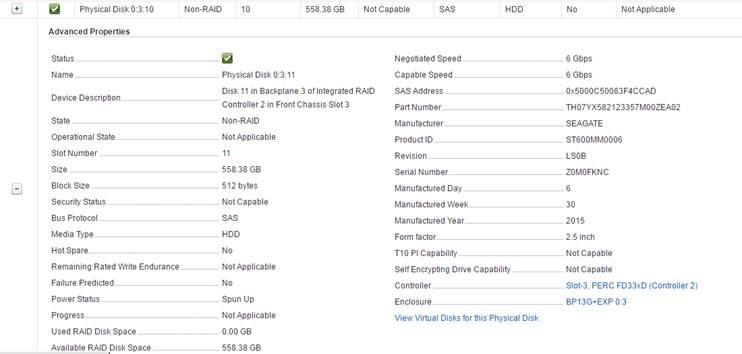

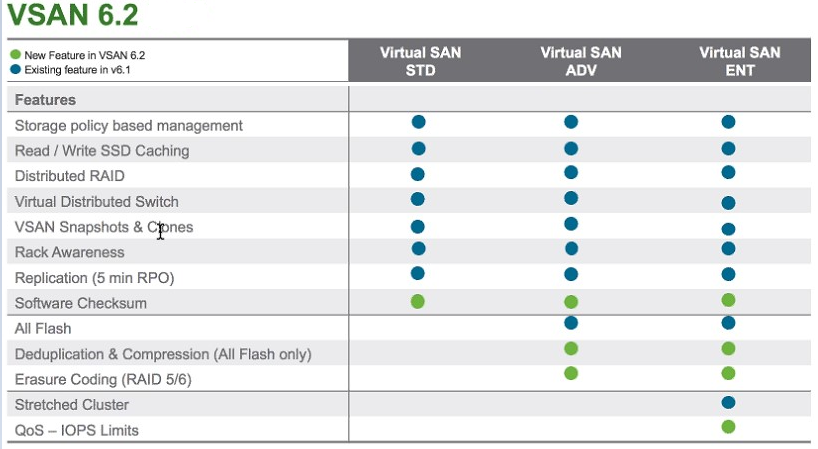
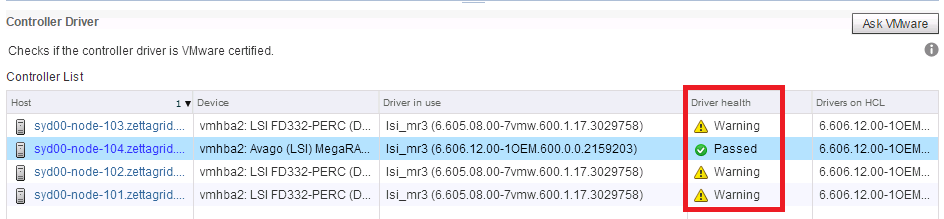


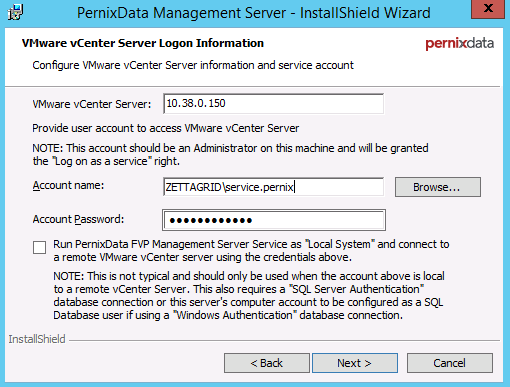

![CloudPhysics: Enhanced Storage Analytics Cards [Part 2] – Snapshots Gone Wild 2](/images/2014/05/snap.png)
![CloudPhysics: Enhanced Storage Analytics Cards [Part 1] - Datastore Contention](/images/2014/04/cp_s_1.png)