Disaster Recovery and Resiliency with Veeam Cloud Tier
Yesterday at Cloud Field Day 5, I presented a deep dive on our Cloud Tier feature that was released as a feature for Scale Out Backup Repository (SOBR) in Veeam Backup & Replication Update 4. The section went through an overview of its value proposition as well as deep dive into how we are tiering the backup data into Object Storage repositories via the Capacity Tier Extend of a SOBR. I also covered the space saving and cost saving efficiencies we have built into the feature as well as looking at the full suite of recoverability options still available with data sitting in an Object Storage Repository. This included a live demo of a situation where a local Backup infrastructure had been lost and what the steps would be to leverage the Cloud Tier to bring that data back at a recovery site.
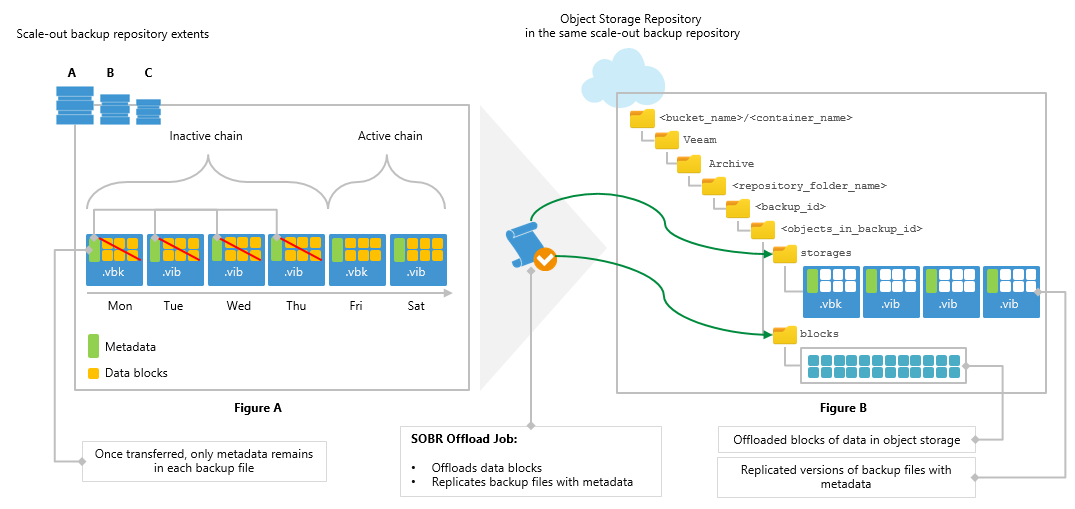
Quick Overview of Offload Job and VBK Dehydration:
Once a Capacity Tier Extent has been configured, the SOBR Offload Job is enabled. This job is responsible for validating what data is marked to move from the Performance Tier to the Capacity Tier based on two conditions.
- The Policy defining the Operational Restore Window
- If the backup data is part os a sealed backup chain
The first condition is all about setting a policy on how many days you want to keep data locally on the SOBR Performance Tiers which effectively become your landing zone. This is often dictated by customer requirements and now can be used to better design a more efficient approach to local storage with the understanding that the majority of older data will be tiered to Object storage.
The second is around the sealing of backup chains which means they are no longer under transformation. This is explained in (https://helpcenter.veeam.com/docs/backup/vsphere/capacity_tier_inactive_backup_chain.html?ver=95u4) and I also go through it in the CFD#5 session video here.
Once those conditions are met, the job starts to dehydrate the local backup files and offload the data into Object Storage leaving a dehydrated shell with only the metadata.
The importance of this process is that because we leave the shell locally with all the metadata contained, we are able to still perform every Veeam Recovery option including Instant VM Recovery and Restore to Azure or AWS.
Resiliency and Disaster Recovery with Cloud Tier:
Looking at the above image of the offload process you can see that the metadata is replicated to the Object Storage as well as the Archive Index which keeps track of which blocks are mapped to what backup file. In fact for every extent we keep a resilient copy of the archive index meaning that if an extent is lost, there is still a reference. Why this is relevant is because it gives us disaster recovery options in the case of a loss of whole a whole backup site or the loss of an extent. During the synchronization, we download the backup files with metadata located in the object storage repository to the extents and rebuild the data locally before making it available in the backup console. After the synchronization is complete, all the backups located in object storage will become available as imported jobs and will be displayed under the Backups and Imported in the inventory pane. But what better way to see this in action than a live demo…Below, I have pasted in the Cloud Field Day video that will start at the point that I show the demo. If the auto-start doesn’t kick in correctly the demo starts at the 31:30 minute mark. https://youtu.be/3hOCJ9Rj-zE?t=1873 References: https://helpcenter.veeam.com/docs/backup/vsphere/capacity_tier_offload_job.html?ver=95u4