First Look: On Demand Recovery with Cloud Tier and VMware Cloud on AWS
Since Veeam Cloud Tier was released as part of Backup & Replication 9.5 Update 4, i’ve written a lot about how it works and what it offers in terms of offloading data from more expensive local storage to what is fundamentally cheaper remote Object Storage. As with most innovative technologies, if you dig a little deeper… different use cases start to present themselves and unintended use cases find their way to the surface.
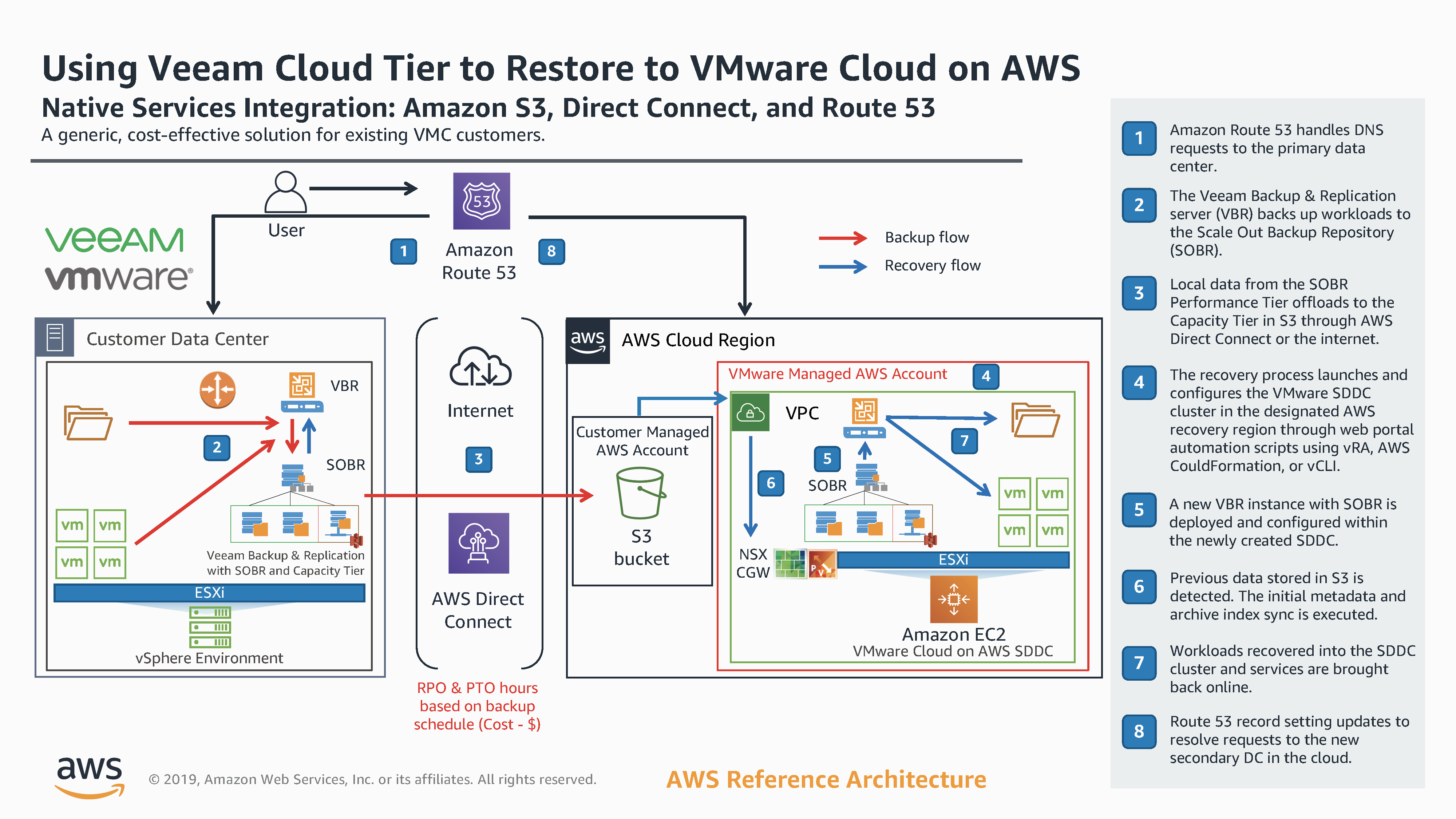
Such was the case when, together with AWS and VMware, we looked at how Cloud Tier could be used as a way to allow on demand recovery into a cloud platform like VMware Cloud on AWS. By way of a quick overview, the solution shown below has Veeam backing up to a Scale Out Backup Repository which has a Capacity Tier backed by an Object Storage repository in Amazon S3. There is a minimal operational restore window set which means data is offloaded quicker to the Capacity Tier.
Once there, if disaster happens on premises, an SDDC is spun up, a Backup & Replication Server deployed and configured into that SDDC. From there, a SOBR is configured with the same Amazon S3 credentials that connects to the Object Storage bucket which detects the backup data and starts a resync of the metadata back to the local performance tier. ((http://anthonyspiteri.net/disaster-recovery-and-resiliency-with-veeam-cloud-tier/)) Once the resync has finished workloads can be recovered, streamed directly from the Capacity Tier.
The diagram above has been published on the AWS Reference Architecture page, and while this post has been brief, there is more to come by way of an offical AWS Blog Post co-authored by myself Frank Fan from AWS around this solution. We will also look to automate the process as much as possible to make this a truely on demand solution that can be actioned with the click of a button.
For now, the concept has been validated and the hope is people looking to leverage VMware Cloud on AWS as a target for disaster and recovery look to leverage Veeam and the Cloud Tier to make that happen.
References: AWS Reference Architecture