
14 Years on WordPress. Done in an Afternoon.
I've been wanting to move off WordPress and onto a static site for years. What always stopped me was the complexity. Here's how Claude Code knocked it out in an afternoon.
Category
190 posts
I've been wanting to move off WordPress and onto a static site for years. What always stopped me was the complexity. Here's how Claude Code knocked it out in an afternoon.

In today’s tech world, keeping up with the latest trends is more important than ever. On last week’s Veeam Industry Insights, myself and Leah Troscianecki to...
In the latest episode of the Great Things with Great Tech podcast, we delve into the challenges of IT management in today's fragmented channel. We explore ho...

We are well into 2024 now, with January all but done and dusted... but before we really dive into 2024, let's take a look ahead as we move forward into what ...
That is a tightrope of a blog title as ever i've written... so let's see how this goes! I had the pleasure of joining host Jeremy Balius, on the Filament pod...

In our digital era, data is the lifeblood that flows through the veins of both corporations and individuals. Security breaches, unfortunately, have evolved f...

The releases keep coming in 2023 from Veeam! This week, we have released the GA of Veeam Backup for Microsoft 365 (VBM) version 7.0 ( Build 7.0.0.2911 ). Thi...

There is no doubt we are moving into a new era of infrastructure to host applications and workloads on. And as organisations start to move back to on-premise...

One of the best parts about travelling to tech conferences, expos and shows is the opportunity to talk on various panels and be interviewed by media outlets....

NOTE: The following content was transcribed and modified from the Thoughts on X podcast embedded above... Click Play if you would like to listen. Last week, ...

Don't call this a reboot! It's no secret that i've been caught by the Podcast bug...in fact consuming information via audio has become the number one way tha...
I’m currently heading over to the newly renamed VMware Explore and it’s not been lost on me that this is the 10th anniversary of my very first VMworld back i...
I'm currently flying back from a week away in Austin Texas attending the first Veeam Tech Expo (inside technical training) in person since June of 2019. It w...

Late last year, I was part of a working group that aimed to come up with the top tech trends in data protection for 2022 and beyond. Being a Technologist, pa...
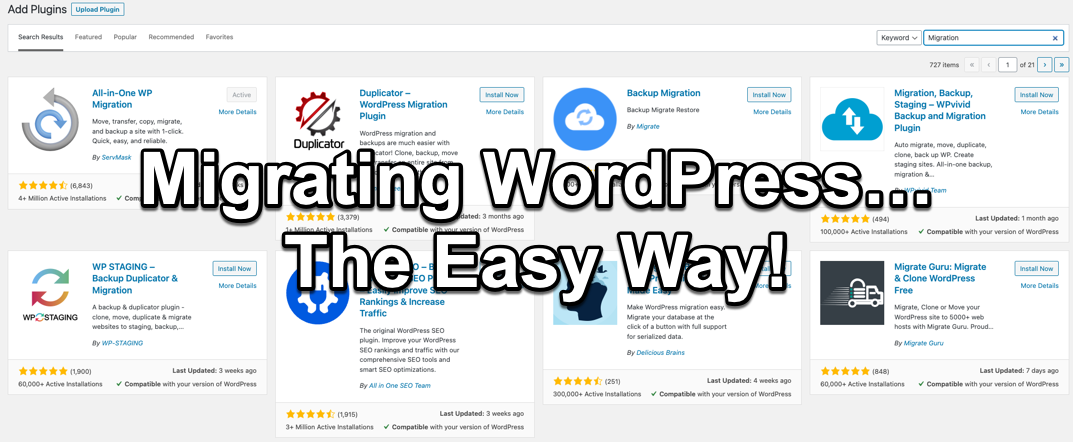
Yes... I still prefer WordPress! Just like how I prefer running MacOS these days for its relative simplicity and minimal operating overheads, so to have I co...

I've been looking for alternative Wordpress blogging options for a while and the one that keeps on coming up is Ghost . Now, Ghost has been around for a long...
Well... sort of! When I started blogging back in 2012, I wasn't sure how long it would last...but over 700 posts and more than a couple million views later V...
Beyond the Elon tweets and the promise of massive profits that is drawing more people than ever into the world of crypto there is something else brewing lite...

Before I joined Veeam I spent all my career working for service providers. I spent my first 7 years working for a hosting provider working on Windows and Lin...

Lets Encrypt has issued over a billion SSL certificates since starting out and has all but ended any reason for not having trusted SSL certificates installed...

I've had a few people ask me about my initial experiences with my new Mac Mini M1 with Apple Silicon, so I thought I would write down my first impressions af...

I've recently gotten my hands on the new Mac Mini M1 which comes with MacOS Big Sur as the default operating system. Being new, and on Apple Silicon, I expec...

We have almost gone a whole week now in 2021 and it has not been the hard pivot that most were hoping for... in fact things around the world seem to be getti...

Four days into 2021 and I am doing my final retrospectives on the year just gone. I can't/won't even type in the year as most of you reading this wish it abs...
While the Veeam Product Strategy Team had our wings clipped this year by Covid, together with Veeam as a whole, we adjusted to this by trying to get to the m...

One of the positive things to come out of 2020 for me was the launch of Great Things with Great Tech . This was something that I had been thinking about for ...

For those in the gaming world, you would be well aware of the much anticipated release of Cyberpunk 2077... a game that was first announced back in 2013 and ...
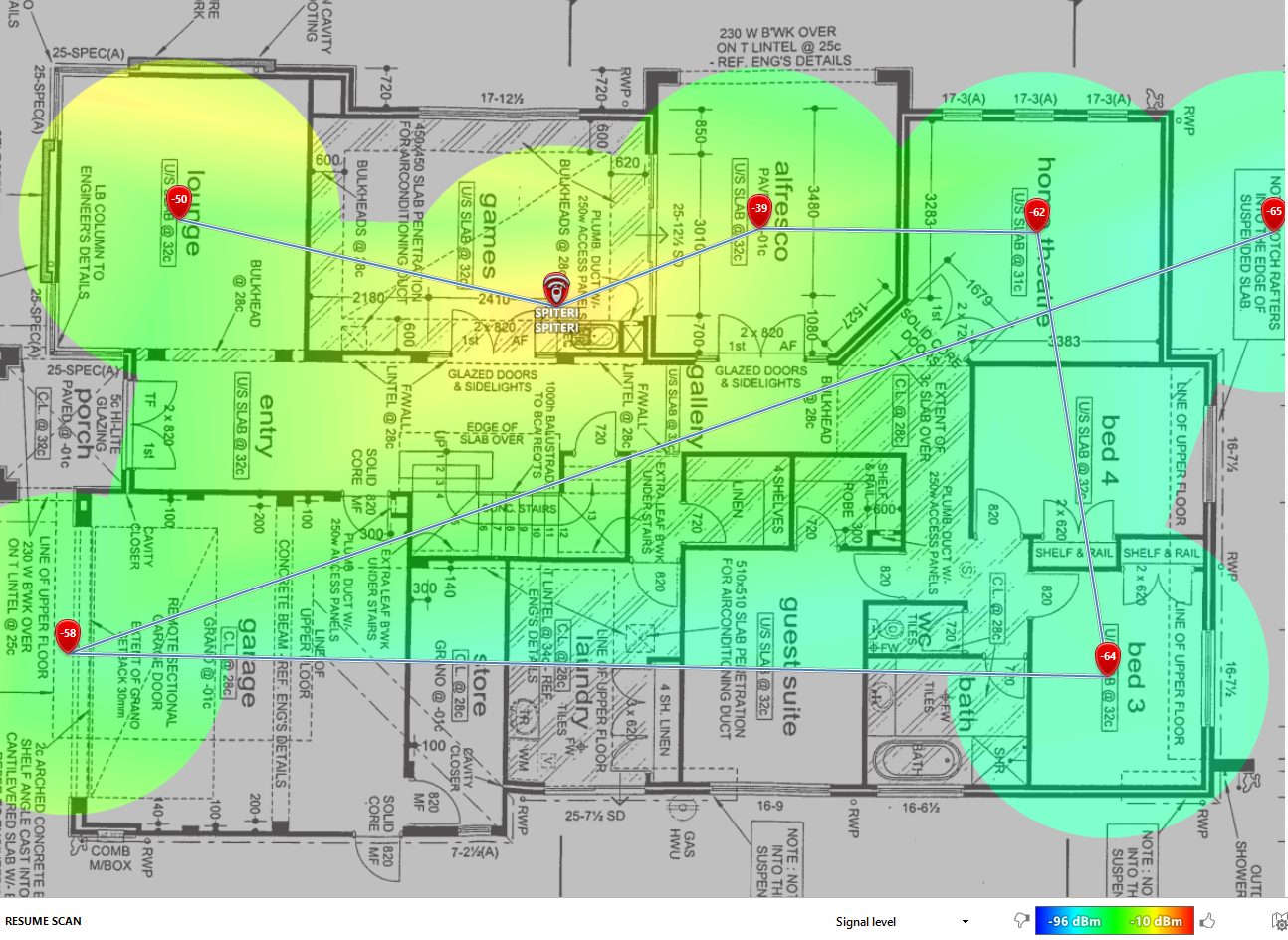
A few months ago I wrote about why I decided to go with the Eero extenders for WiFi at home and went over some of the technical specs of the Eero mesh router...

It might be a surprise to some, but I have a tendency to be a bit of a Luddite when it comes to adopting new technologies around the home and office. Such wa...
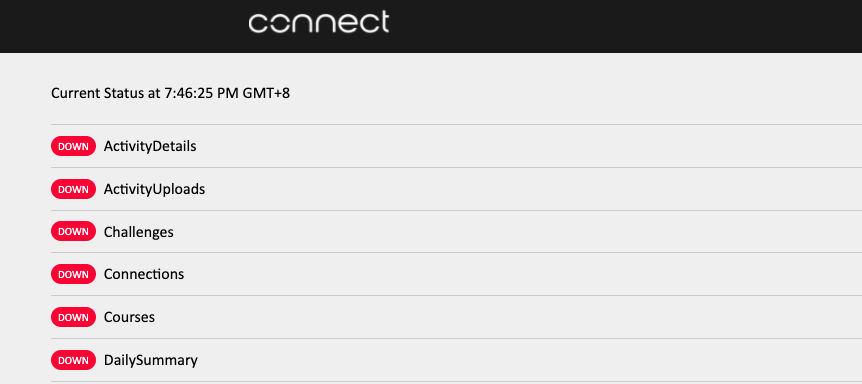
Artificial intelligence, machine learning and the internet of things have been hot topics for any digital transformation discussion in recent years. It’s no ...

Before anything else... if you haven't patched your Cloud Director installations as per the below table... do it now! Product Version Running On CVE Identifi...

It shouldn't come as a surprise that I'm writing about an event that is being held online... especially in this very moment in time. 2020 is the year of the ...

We are currently experiencing a period of Technical Acceleration . The current situation has forced businesses and people to modify their behaviors and pivot...
The world is a very different place today... in fact it's a very different place to what it was just two weeks ago. During this forced working from home situ...

Veeam Backup & Replication v10 has been Generally Available since mid Feburary and last week I posted a What’s in it for Service Providers overview blog post...
The world has lost its proverbial you know what! We are living through a historic event, triggered by the fear of the unknown. That unknown is the COVID-19 c...
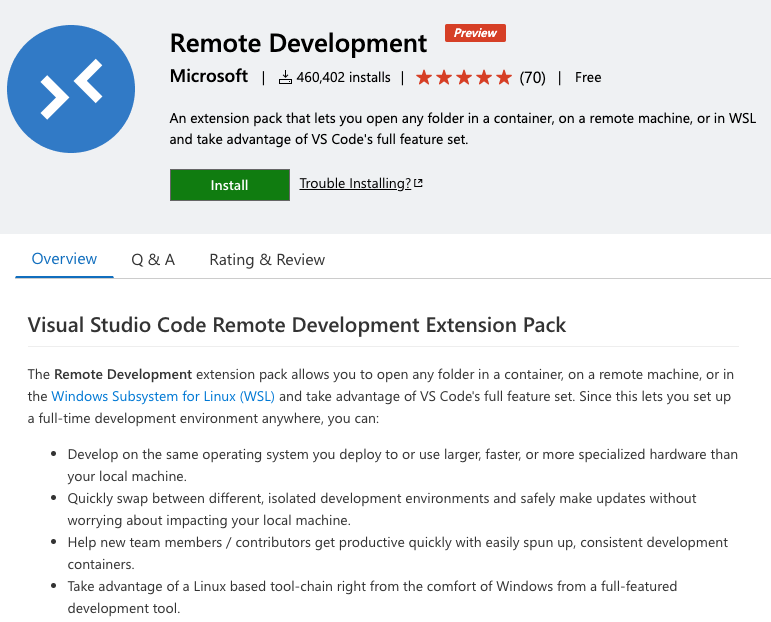
Visual Studio Code has become my default tool for almost everything I do these days when tinkering with automation and Infrastructure as Code. It's also my d...

Hard to believe we are already almost half way through January and the year is 2020! I remember back to when I was a kid, or even a teenager and how long a y...
This year was my third full year working for Veeam and my role being global, requires me to travel to locations and events where my team presents content and...

Over the last few years the amount of CBT related issues has decreased significantly from VMware. I remember back in my previous roles of having to deal with...
This week, KubeCon and Cloud Native Con is happening in San Diego. In the lead up to the event, there was talk about 12,000 registrations which puts it up th...
I'm currently sitting in my hotel room in sunny sunny San Jose. Today and tomorrow will be spent finishing off preparations for Tech Field Day 20 . This will...
In the continuing work I've been doing with Terraform, i've come across a number of gotchyas when working with VM Templates and deploying them on mass. The n...

This week it gave me great pleasure to see my former employer, Zettagrid announced a significant expansion in their operations, with the addition of three ne...

Welcome to the 11th edition of Veeam Vault and the first one for 2019! It's been more than a year since the last edition, however in light of some important ...
During the first plan execution of a new VM based on a Windows Server Core VM Template, my Terraform plan timed out on Guest Customizations. The same plan ha...

VMworld is rapidly approaching, and for those that have not secured their place at the event in San Francisco, and for whatever reason have been hindered in ...

The jet lag has almost passed... I've nearly caught up with the backlog of messages on my various social platforms... expenses are almost done... and i'm abo...

This is more or less a follow up post to the one I wrote back in 2015 about the state of containers in the IT World as I saw it at the time. I started off th...
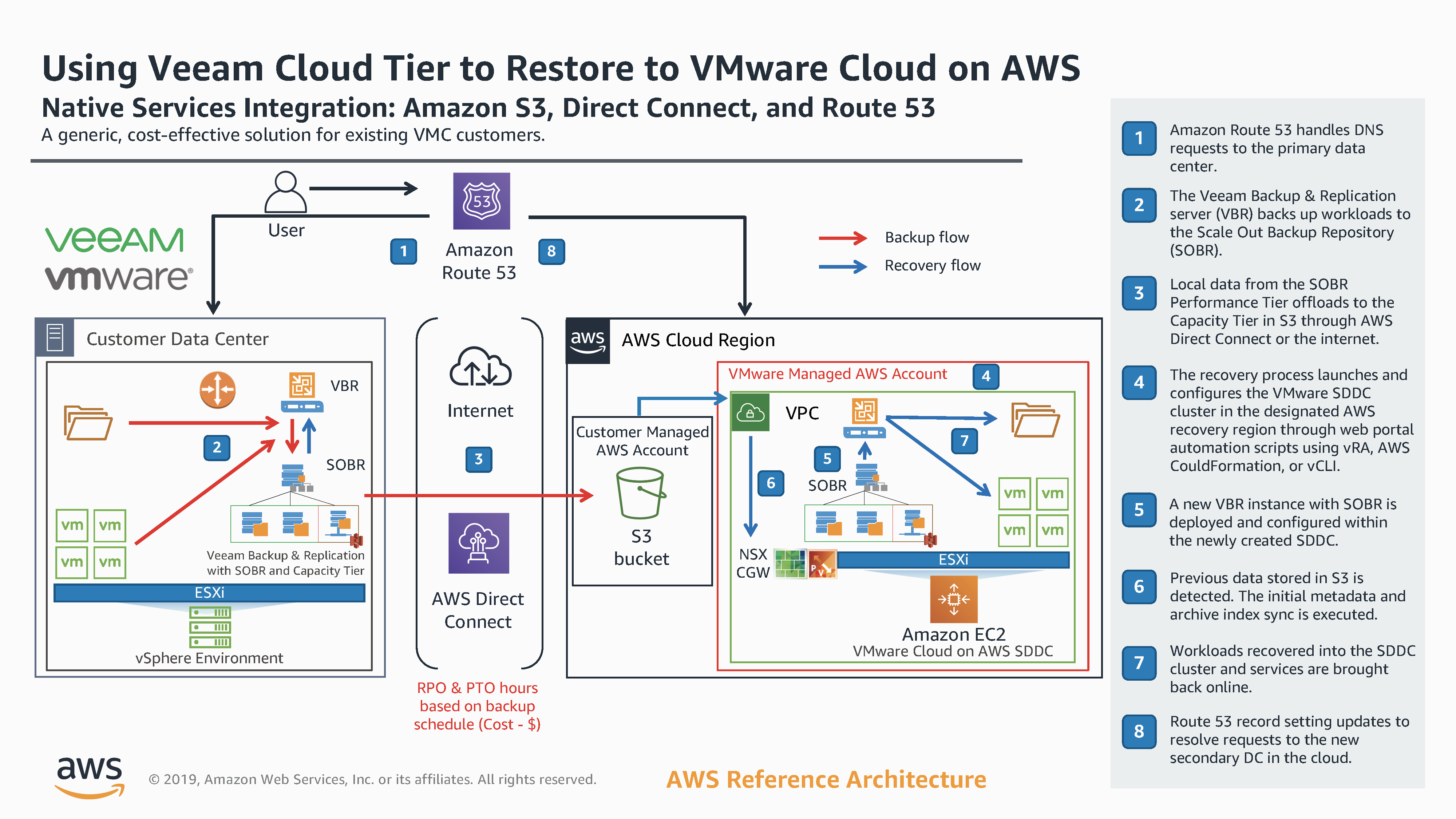
Since Veeam Cloud Tier was released as part of Backup & Replication 9.5 Update 4 , i've written a lot about how it works and what it offers in terms of offlo...
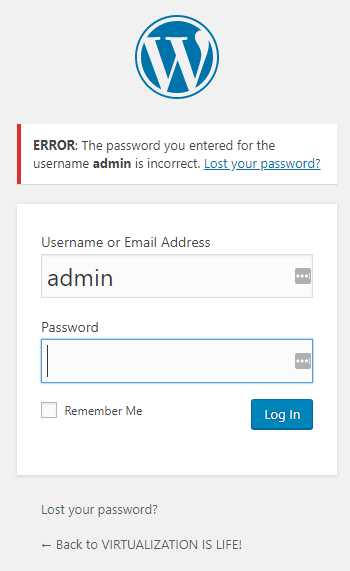
I've just had a mild scare in that I was unable to log into this WordPress site even after trying a number of different ways to gain access by resetting the ...
As recent events have shown, outages and disasters are a fact of life in this modern world. Given the number of different platforms that data sits on today, ...

I don't usually use this blog to write about things other than technology but seeing as though a big part of my professional life is spent in the air flying,...

Hard to believe that another VeeamON has come and gone… for us in the Product Strategy Team the lead up and the week is immensely busy... but this is what we...

When I was a boy, I started following the Essendon Australian Rules Football club ...I was drawn to their colours and I was also drawn to the fact they had j...

While I was a little late to the game in understanding the power of Infrastructure as Code, I've spent a lot of the last twelve months working with Terraform...
Last week I had the pleasure of presenting at Cloud Field Day 5 (a Tech Field Day event). Joined by Michael Cade and David Hill, we took the delegates throug...
I'm currently on the first leg over from Perth to San Fransisco where I'll head down to Silicon Valley to present at Cloud Field Day 5 . This will be my firs...
Last week the Top vBlog for 2018 where announced based on votes cast late last year on content delivered in 2017. Similar to last year Eric Siebert continued...

A few years ago I claimed that the Melbourne VMUG Usercon was the “Best Virtualisation Event Outside of VMworld!” …that was a big statement if ever there was...
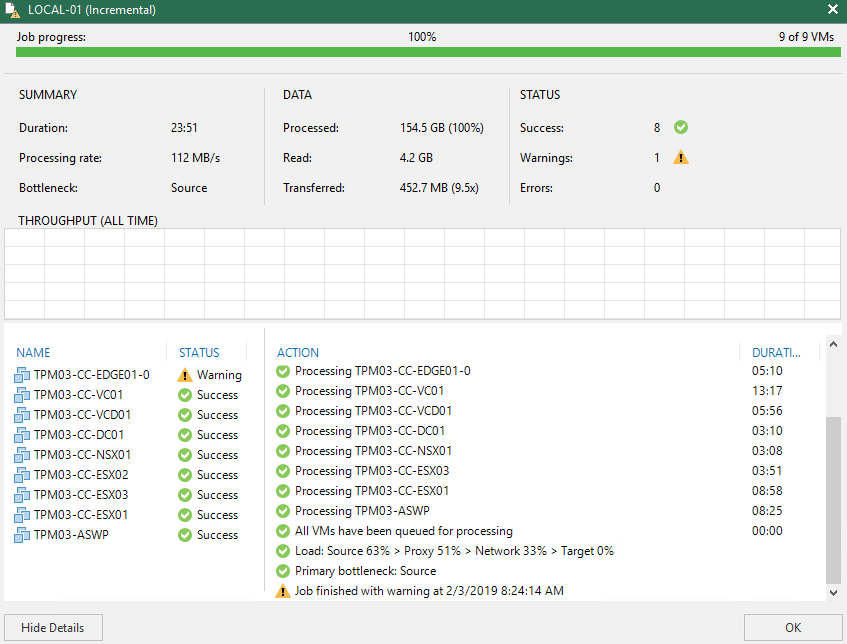
Recently I was sent a link to a video that showed an end user comparing Veeam to a competitors offering covering backup performance, restore capabilities and...

We are entering interesting times in the cloud space! We should no longer be talking about the cloud as a destination and we shouldn’t be talking about how c...
Overnight, applications for the 2019 VMware vExperts where opened up and as per usual it's created a flurry of activity on social media channels and well as ...

2018 is done and dusted and looking back on the blog over the last twelve months I've not been happy with my output compared to previous years...i've found i...
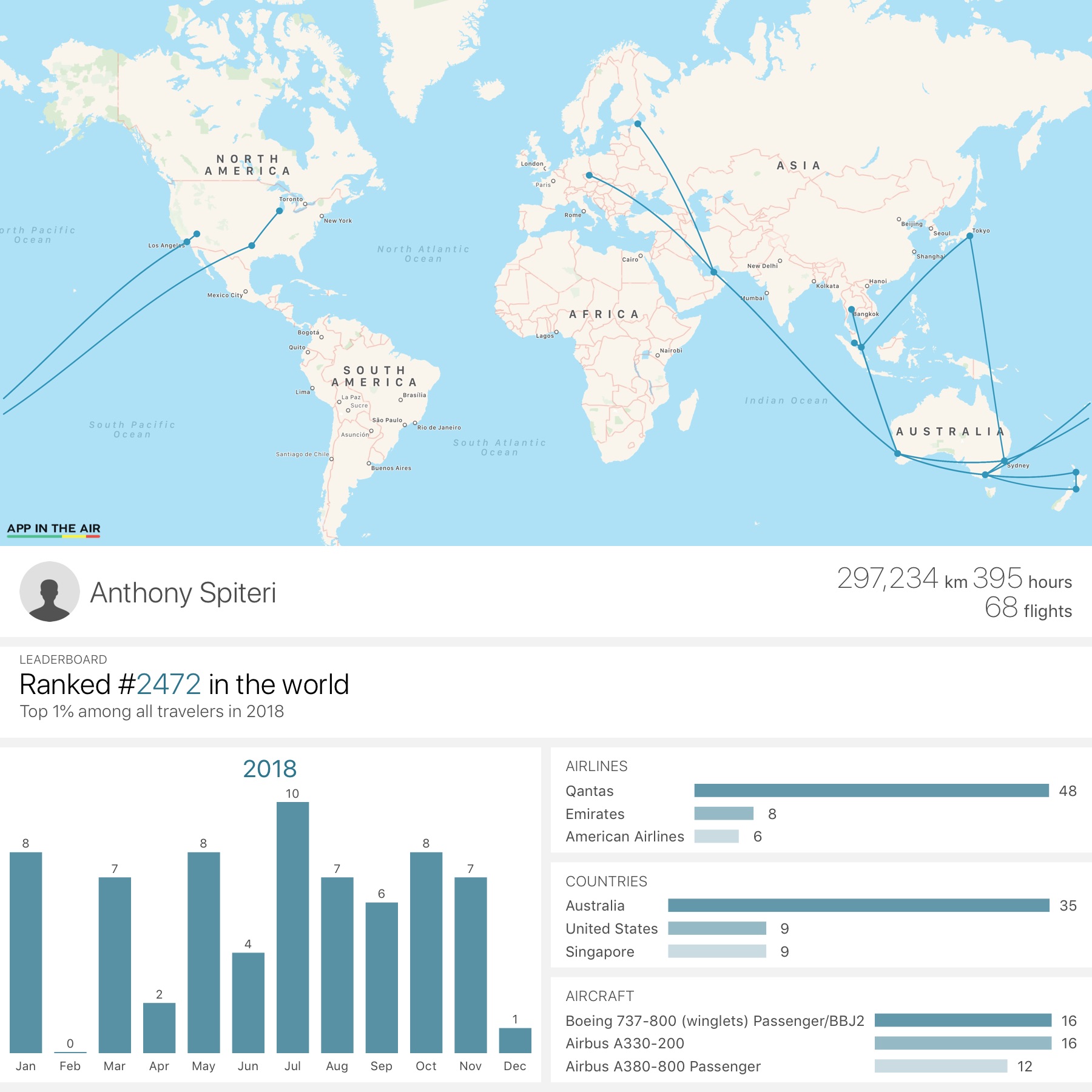
This year was my second full year working for Veeam and my role being global, requires me to travel to locations and events where my team presents content an...

While I had resisted the temptation to put out a blog on this years Top vBlog voting I thought with the voting coming to an end it was worth giving it a shou...

I wrote this sitting in the Qantas Lounge in Melbourne waiting for the last leg back to Perth after spending the week in Las Vegas at AWS re:Invent 2018 . I ...
A few weeks ago I upgraded my NestedESXi homelab to vSphere 6.7 Update 1 . Even though Veeam does not have offical supportability for this release until our ...

As Red October came to a close…at a time when US Tech stocks were taking their biggest battering in a long time the news came out over the weekend that IBM h...
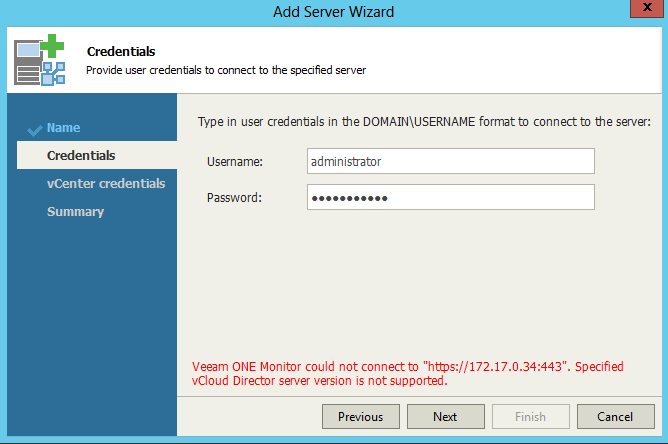
Back in May when VMware released vCloud Director 9.1 they also depreciated support for a number of older API versions: End of Support for Older vCloud API Ve...
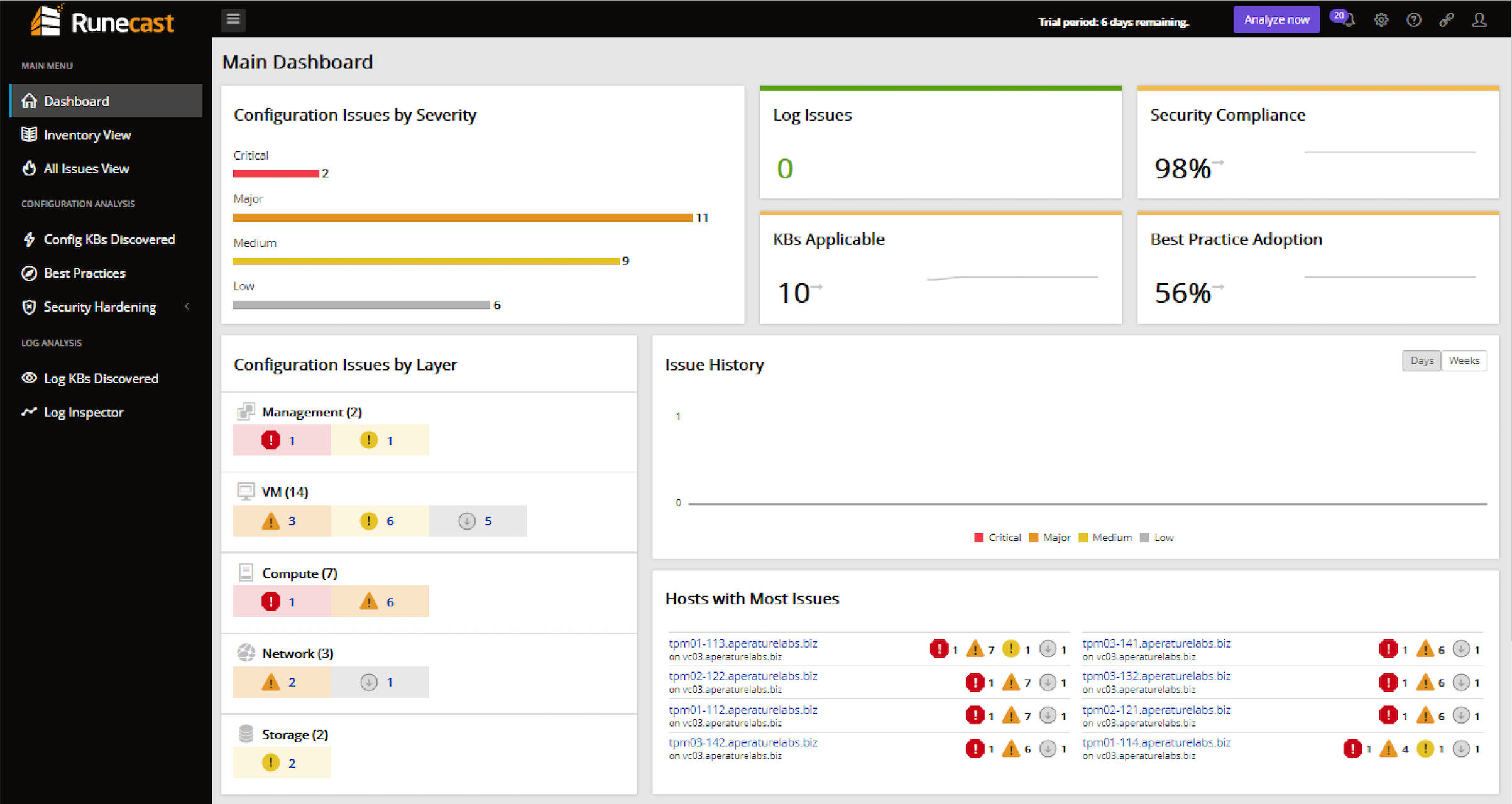
Earlier this week, Runecast released into General Availability version 2.0 of their vSphere analyser platform. I've been a keen follower of the progress of R...
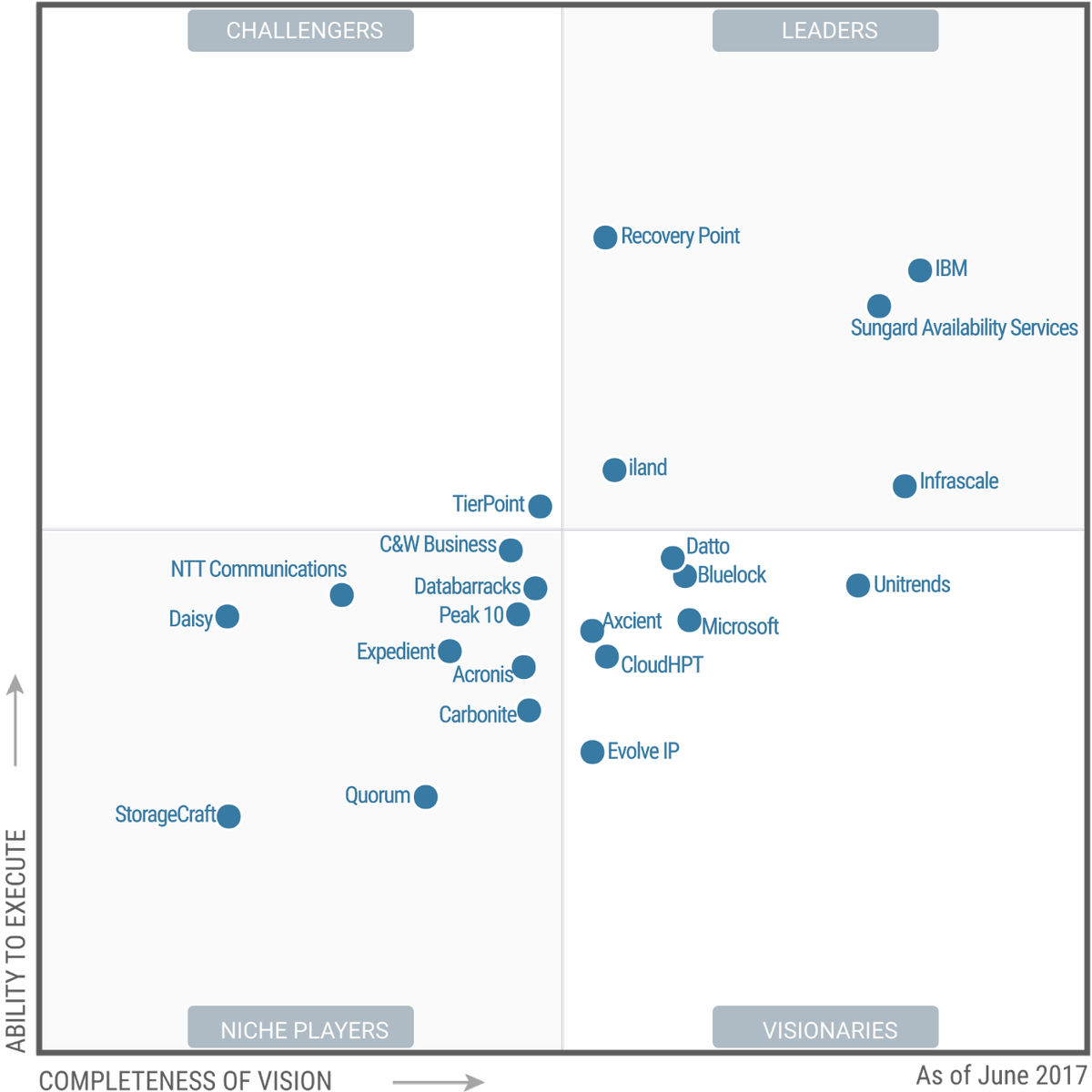
Over the past week Garter released the 2018 edition of the Magic Quadrant for DR as a Service . The first thing that I noticed was how sparse the quadrant wa...

It's never an issue with DNS! Even when DNS looks right...it's still DNS! I came across an issue today trying to upgrade a 6.5 VCSA to 6.7. The new VCSA appl...
I'm currently going through the process of acquiring a new Let's Encrypt free SSL Certificate against a new domain I registered. For a great overview of what...

True innovation is solving a real problem ...and though for the most, it's startups and tech giants that are seen to be the innovators, their customers and p...
After a longer than expected deliberation period the vExpert class of 2018 was announced late last Friday (US Time). I’ve been a vExpert since 2012 with 2018...
Welcome to the 10th edition of Veeam Vault and the first one for 2018. It's pretty crazy to think that we have already completed two months of the year. Afte...
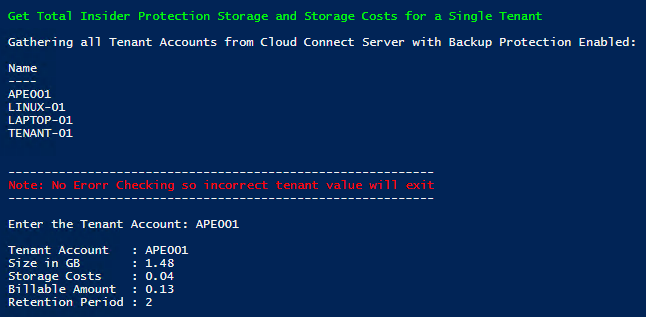
Last month I published a blog that looked deeper into the Insider Protection feature that was added as a feature to Veeam Cloud Connect as part of Update 3 f...
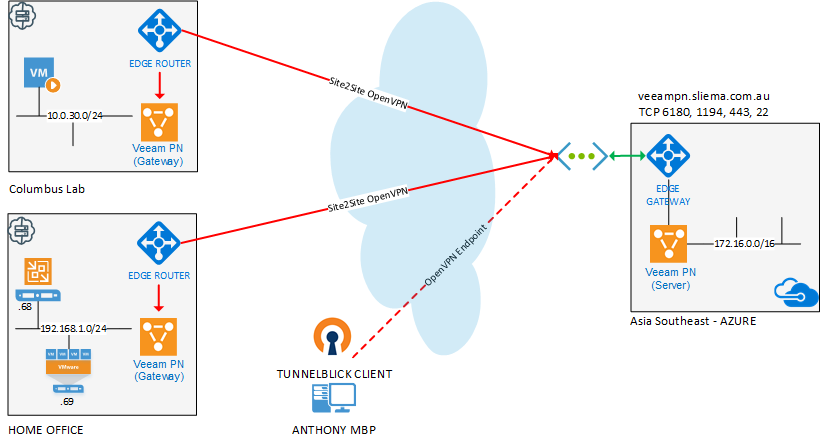
This week we announced the offical GA of Veeam Recovery to Microsoft Azure featuring Veeam Powered Network (Veeam PN). This new product also features Directo...
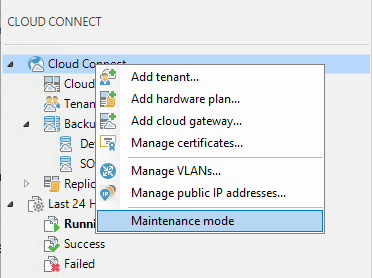
Lately i've been digging deeper into the Veeam Availability Console and have been wrapping my head around it's extended feature set. With that I thought it w...

Looking back over the past couple of years I haven't written a forward looking blog post about the year ahead since 2015 and as I sit here working through my...

2017 is done and dusted and looking back on the blog over the last twelve months I've not been able to keep the pace up compared to the previous two years in...
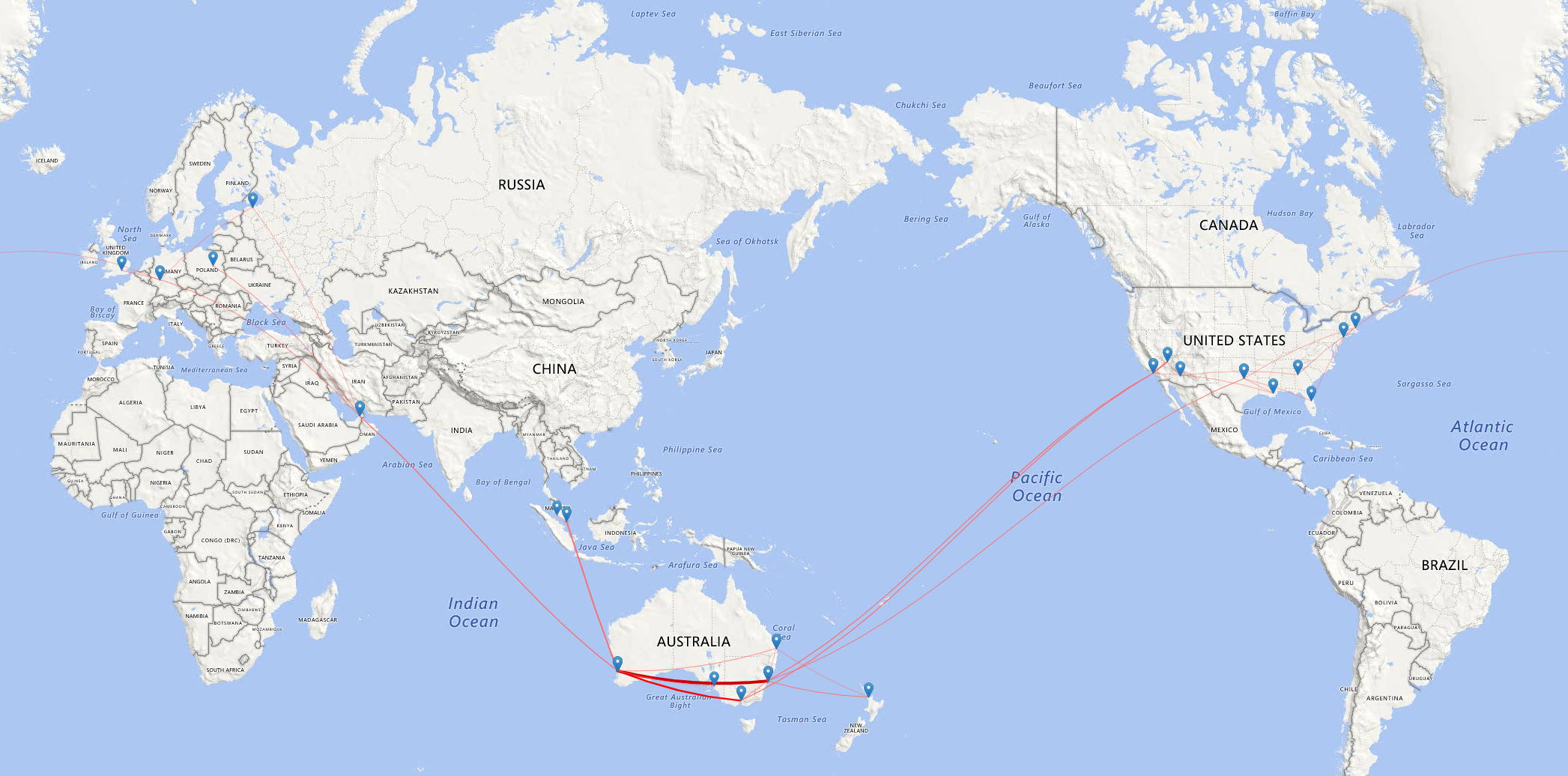
This year was my first full year working for Veeam and my role being global, requires me to travel to locations and events where my team presents content and...

This week marks one year since I started at Veeam and it feels like that twelve months has flown by. Before I started here at Veeam I had only worked for loc...

This time next week VMworld 2017 will be kicking off with the Sunday evening Welcome Reception among other sponsor and community events and for me, it will m...
A few months ago I was lucky enough to spend time with a couple of the founders of Runecast, Stanimir Markov and Ched Smokovic and got to know a little more ...

It feels like this year moving along at ludicrous speed so it's no surprise that the Top vBlog for 2017 has been run and won. This year Eric Siebert changed ...
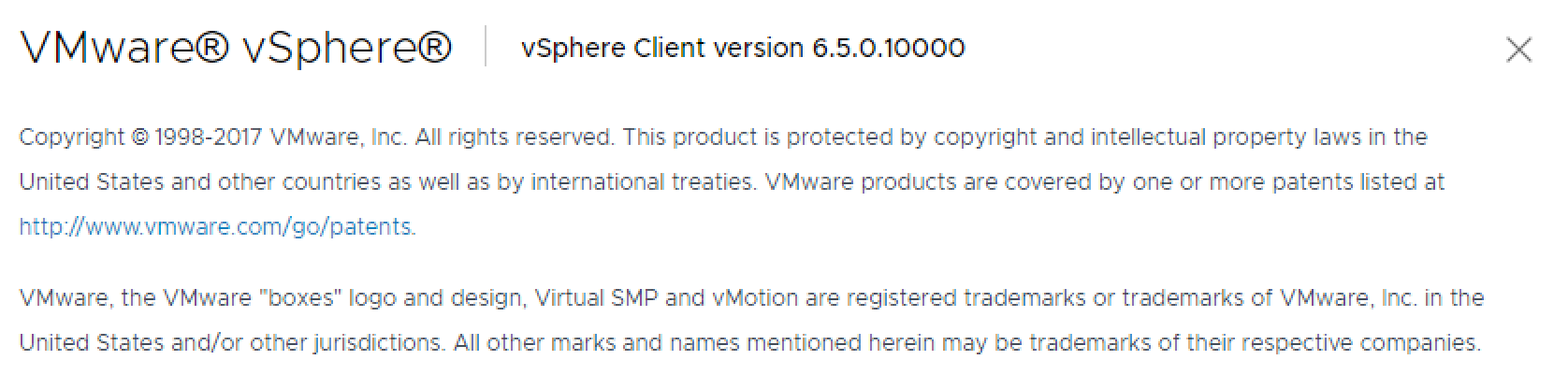
Late last week VMware released vSphere 6.5 Update 1 which included updated builds of both vCenter and ESXi and as per usual I will go through some of the key...
I originally came across the issue of slow storage performance with the native vmw_ahci driver that comes bundled with ESXi 6.5 just as I was first playing w...
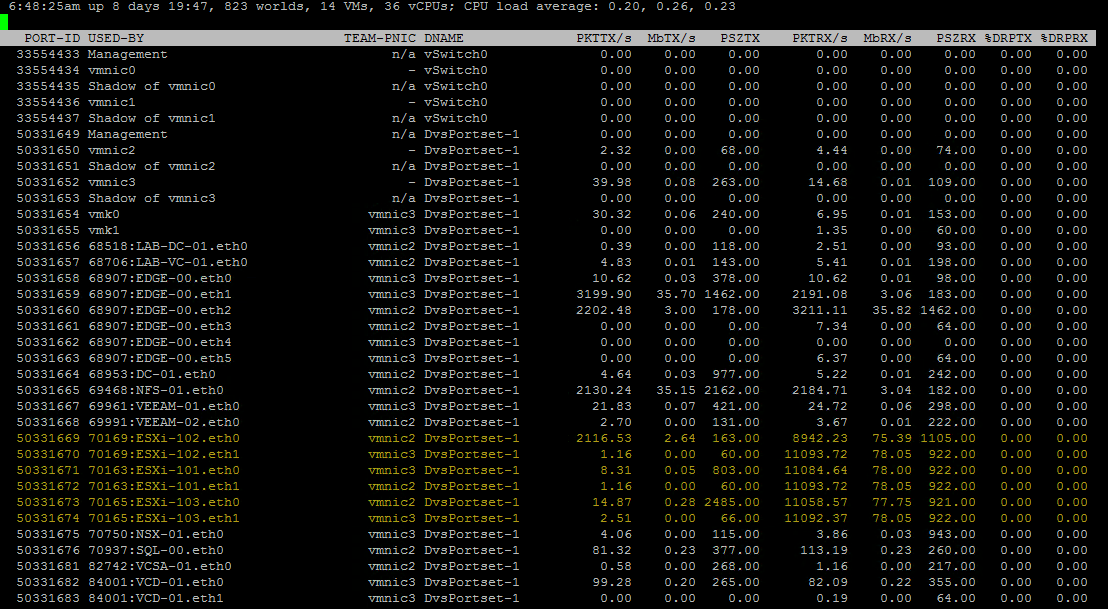
I've been running my NestedESXi homelab for about eight months now but in all that time I had not installed or enabled the ESXi MAC Learning dvFilter . As a ...
It's been just over two months since my last Veeam Vault went out and can you believe that was just before VeeamON 2017 in New Orleans. Again, for a recap of...
While I had resisted the temptation to put out a blog on this years Top vBlog voting I thought with the voting coming to an end it was worth giving it a shou...

Just after I joined Zettagrid in June of 2013 I decided to load up vSphere 5.1 Clustering Deepdive by Duncan Epping and Frank Denneman on my iPad to read on ...

In July of 2011, Distribute.IT, a domain registration and web hosting services provider in Australia was was hit with a targeted, malicious attack that resul...

Having worked in and around the service provider space for most of my career when I heard about the Linux variant of WannaCry, SambaCry last week, I thought ...
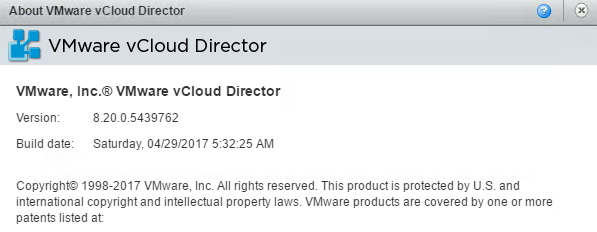
Last week VMware released an update for vCloud Director SP ( Build 5439762 ) and while the small version increment suggest a small release, it actually conta...

VeeamON 2017 has come and gone and even though I left New Orleans on Friday afternoon, I just arrived back home…54 hours of travel, transit and delays has me...
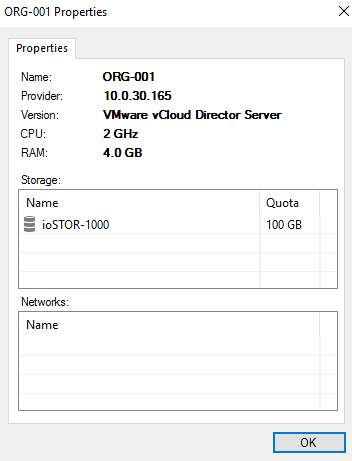
Today at VeeamON 2017 we announced two very important enhancements to our DRaaS capabilities around Cloud Connect Replication and Tape Backup for our Veeam C...

Time flies quickly when you're having fun! VeeamON 2017 kicks off in New Orleans kicks off in just a few days and to say that it's been a hectic period for t...

I awoke this morning to the news that an announcement was made at DELL|EMC World that VMUG had been rolled into a the recently formed Dell Technologies User ...

I've just spent the last fifteen minutes looking back through all my posts on vCloud Air over the last four or five years and given yesterday's announcement ...

Last week I attended the Sydney and Melbourne VMUG UserCons and apart from sitting in on some great sessions I came away from both events with a renewed sens...

I’ve been on the road over the past couple of weeks presenting to Veeam’s VCSP partners and prospective partners here in Australia and New Zealand on Veeam’s...
Overnight Cory Romero announced the intake of the 2017 VMware vExperts . As a now six time returning vExpert it would be easy for me to sit back enjoy a perc...

In the last couple of weeks there had been murmurings within the VMUG Leadership Group that Nutanix was about to be banned from sponsoring events worldwide. ...
2016 is pretty much done and dusted and it's been an good year for Virtualization is Life! There was a more modest 70% increase in site visits this year comp...
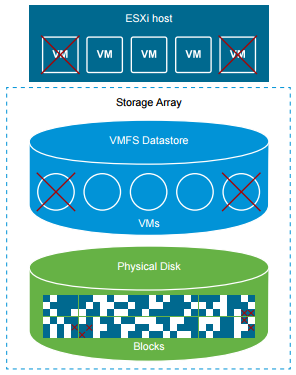
One of the cool newly enabled features of vSphere 6.5 is the come back of VMFS storage space reclamation. This feature was enabled in a manual way for VMFS5 ...

Last week I was in Sydney for the 2016 edition of vForumAU ...I've been coming to vForumAU since 2011 and this years event was probably up there with the bes...

About four years ago I was invited to join a program called the VMware vChampions...this program is run and operated by the VMware ANZ Channel and Marketing ...
With vForumAU 2016 less than a week away it's time to talk about what the vBrownBag crew will be up to next week in Sydney. If you don't know what the vBrown...

vForumAU is just over a week away and for those that are in Sydney for the event and are around a day earlier should cancel any existing plans and attend VMD...

Three and a half years ago I was given a brilliant opportunity to join what was at the time Australia's leading vCloud Powered Service Provider...Zettagrid. ...

Last week VMware and Amazon Web Services officially announced their new joint venture whereby VMware technology will be available to run as a service on AWS ...

Virtualization is Life! has hit post #300 and I thought I'd take this opportunity to list through some numbers and top posts since I launched this blog as Ho...
Part 1 - Building a Blogging Platform Having looked at hosting platform and operating system suggestions in Part 1, to conclude this two part series I'll tal...
Earlier this week my good friend Matt Crape sent out a Tweet lamenting the fact that he was having issues uploading media to WordPress...shortly after that t...
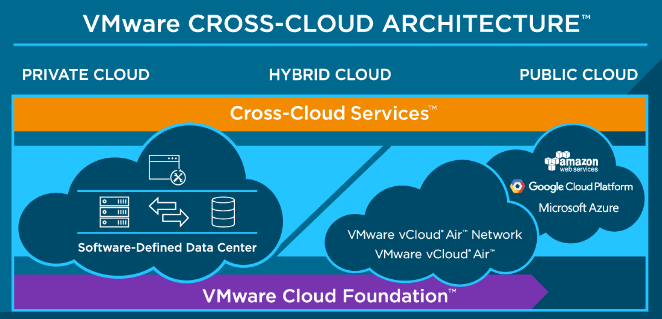
I’ve been sitting on this topic since the VMworld 2016 US Keynote where VMware announced the Cross Cloud Architecture. I posted some raw thoughts the day aft...

I've been wanting to write about this topic for a while but haven't been able to articulate myself in terms of the message I wanted get across until now. Thi...

Microsoft's World Wide Partner Conference is currently on again in Toronto and even though my career has diverged from working on the Microsoft stack (no pun...
The Top vBlog for 2016 Results where announced a couple of nights ago and Australia had an ok representation this year, though the number of active bloggers ...

[ UPDATE ] - VMware have released an official KB for the CBT issue. Sadly if you recognize the title of this post it's because this isn't the first time I've...

Music for most of us is a passionate and emotional experience...When we listen to great albums and great bands we have the ability to be taken back to key mo...

WiFi on planes is here...well its been around for the best part of a decade as I can remember paying $50 for a 30 minute stint back in 2006 on a flight from ...

Last year at VMworld 2015 in San Francisco a couple of us headed out on the Sunday morning for a walk up start of 9 holes of Golf at the Golden Gate Golf Clu...
While I have resisted temptation to post a blog on this years Top vBlog voting I thought with a couple of days to go it was worth giving it a shout just in c...

Well this has crept up on us quickly this year! It's time to vote for the VMworld Sessions that will be part of the US and Europe VMworld's held later in the...

There has been some discussion in the vExpert Slack channel over the last couple of days discussing how the vExpert Program which is an advocacy program that...

EDIT 2pm AWST : Seems as though the link and announcement has been pulled so take with a grain of salt until it's confirmed or otherwise. EDIT 3:15pm ASWT : ...

Over the past week there have been a number of posts around the new vSphere Beta which is the first step in testing the next major release from VMware follow...
Last week I sat and passed the VCIX-NV ( VCXN610 ) exam and I thought I would follow-up last weeks Review Post with some interesting...well I think interesti...

What a effort that was! Today I sat and passed the VCIX-NV ( VCXN610 ) exam and I can say that this exam has taken a fair bit out of me over the last month o...

Last week Frank Denneman blogged about the release of the third installment of the vSphere Design Pocketbook. This is a great initiative from PernixData and ...
Yesterday I attended the Melbourne VMUG UserCon for 2016 and had a great day catching up with community friends, presenting with PernixData and attending oth...
VMware is at an interesting place at this point in time...there is still no doubting that ESXi and vCenter are the market leaders in terms of Hypervisor Plat...
Last Friday Cory Romero announced the first intake of the 2016 VMware vExperts . As a five time returning vExpert it would be easy for me to sit back enjoy a...

This week Veeam released to GA version 9 of their Backup & Recovery product. It's a significant release for Veeam for a number of reasons and after having at...
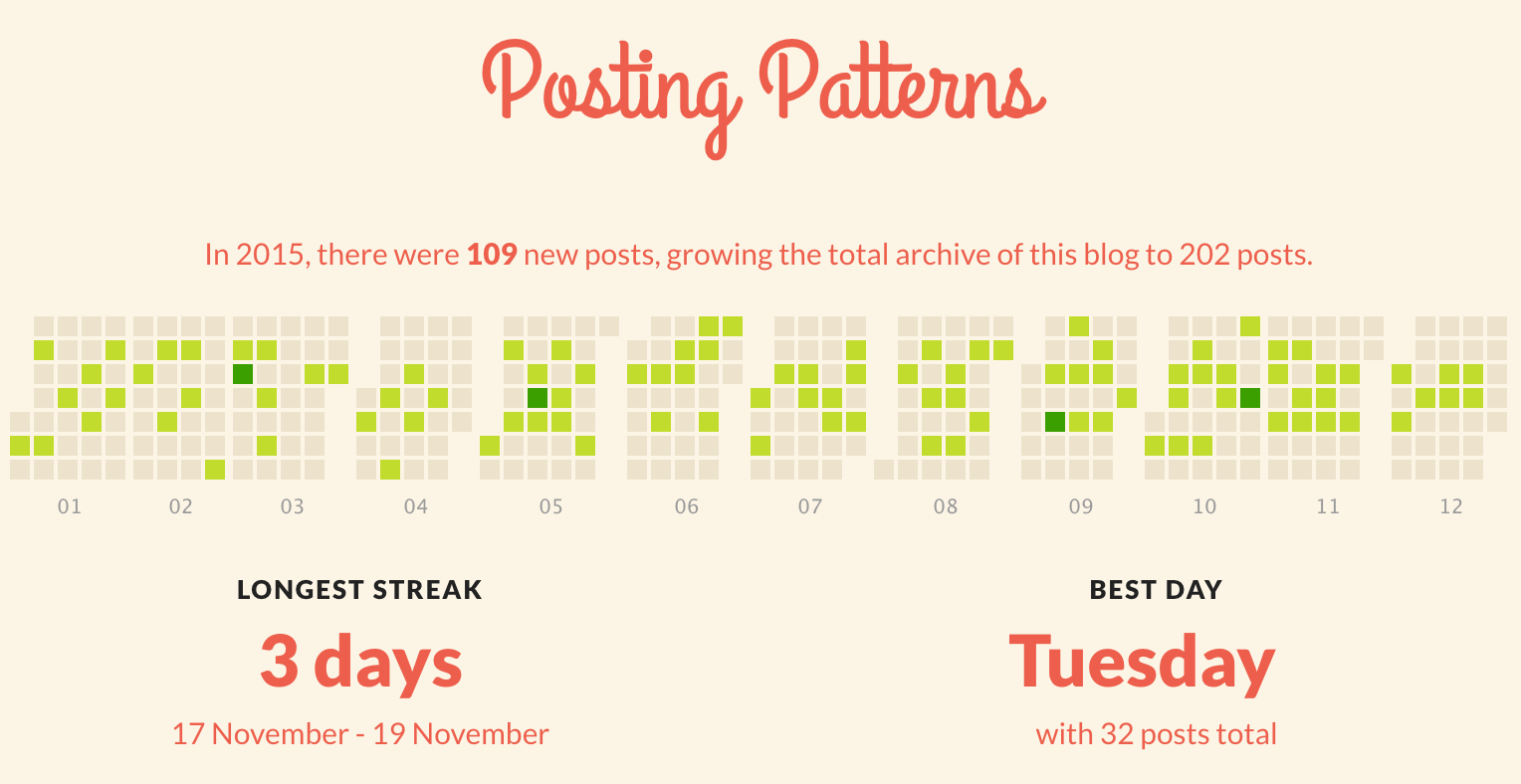
2015 is pretty much done and dusted and it's been an great year in for Virtualization is Life! There was a 300% increase in site visits this year compared to...
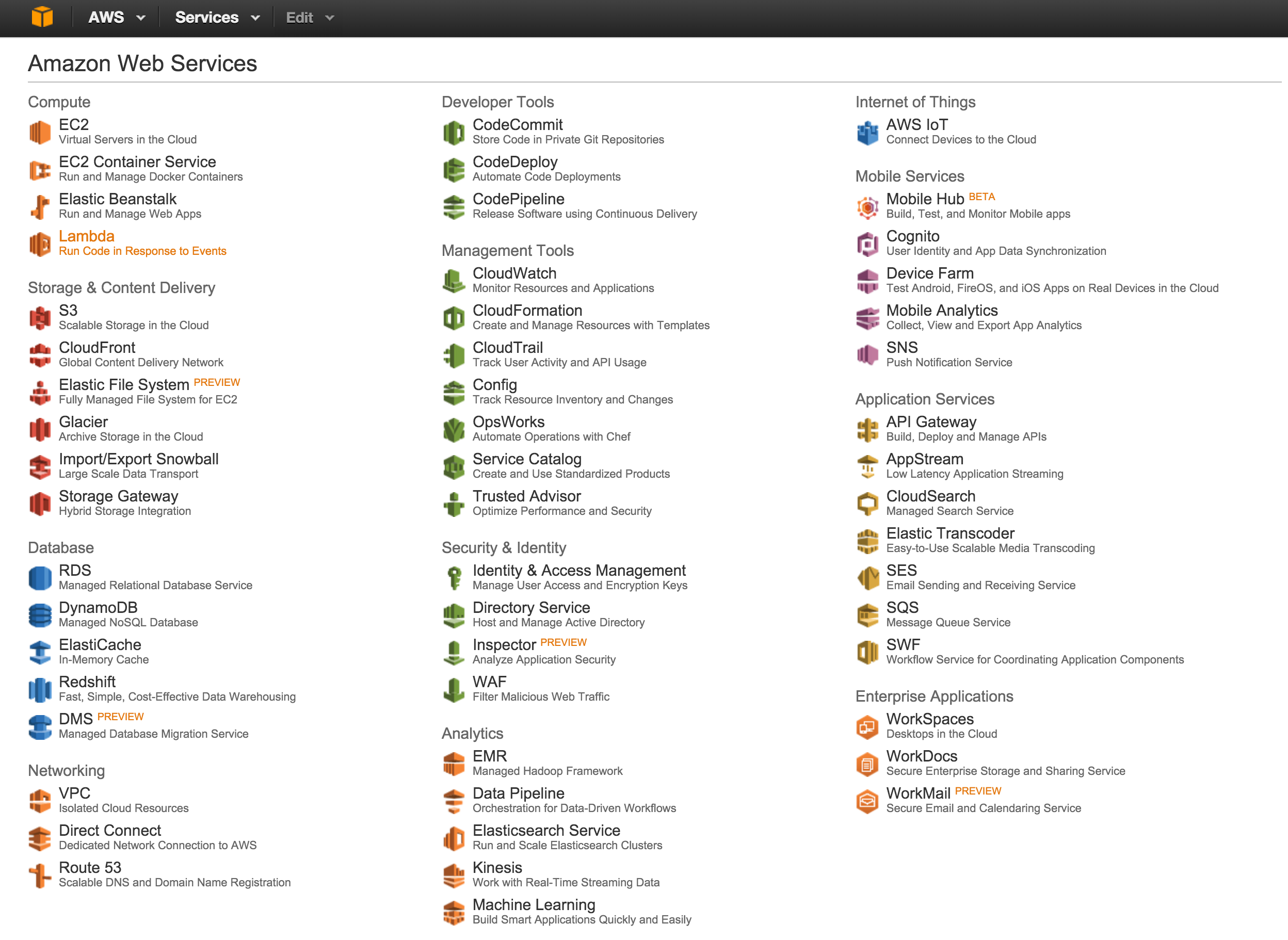
I came across a tweet over the weekend which showed a screen grab of the AWS product catalog (shown below) and a comment pointing out the fact that the sheer...
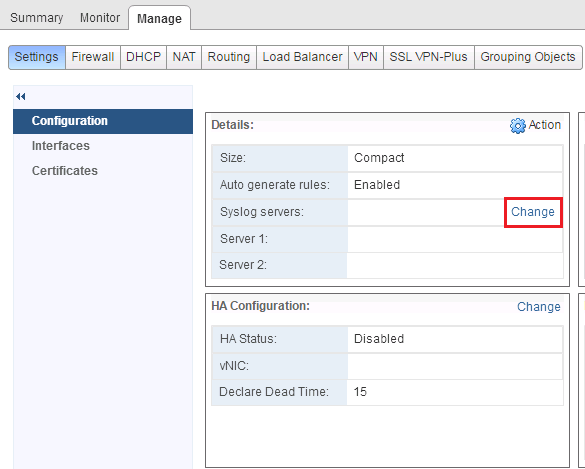
Overview : Being able to view log information is critical in being able to ensure the Edge Gateway is functioning as expected. All services that the Edge pro...
Last week I wrote a piece on the talk around vCloud Air’s demise or more to the point...the often suggested demise of VMware's Public Cloud Platform. The bas...

I’ve been wanting to write some commentary around the vCloud Air and Virtustream merger since rumours of it took place just before VMworld in Auguest and I’v...

A few weeks back at Zettagrid we released our NSX Advanced Networking product that we have been working on for the best part of 12 months. I’m particularly p...
I'm currently going through and documenting the build process for our VSAN Management Clusters and one of the first steps I noted down was to double check th...

Yesterday at the long awaited reboot of the Perth VMUG here in Western Australia I chaired a vExpert/vChampion Panel that included Alex Barron , Luke Brown ,...

Since VMworld in San Francisco, VMware have been on a tear backing up all the VSAN related announcements at the show by starting to push a stronger message a...

Last week at VMworld I was lucky enough to spend some quality time with the PernixData team and got some great insights into their future products including ...

A couple of weeks ago Microsoft raised the prices of Azure , Office 365, CRM Online and other enterprise cloud services across Australia, Canada and Europe. ...

It's been a bad couple of weeks for cloud services both around the world and locally...Over the last three days we have seen AWS have issues which may have b...
In 2008 I vividly remember the impact that leap year/day/seconds can have on systems that are not prepared to handle the changes in time or date. It was the ...
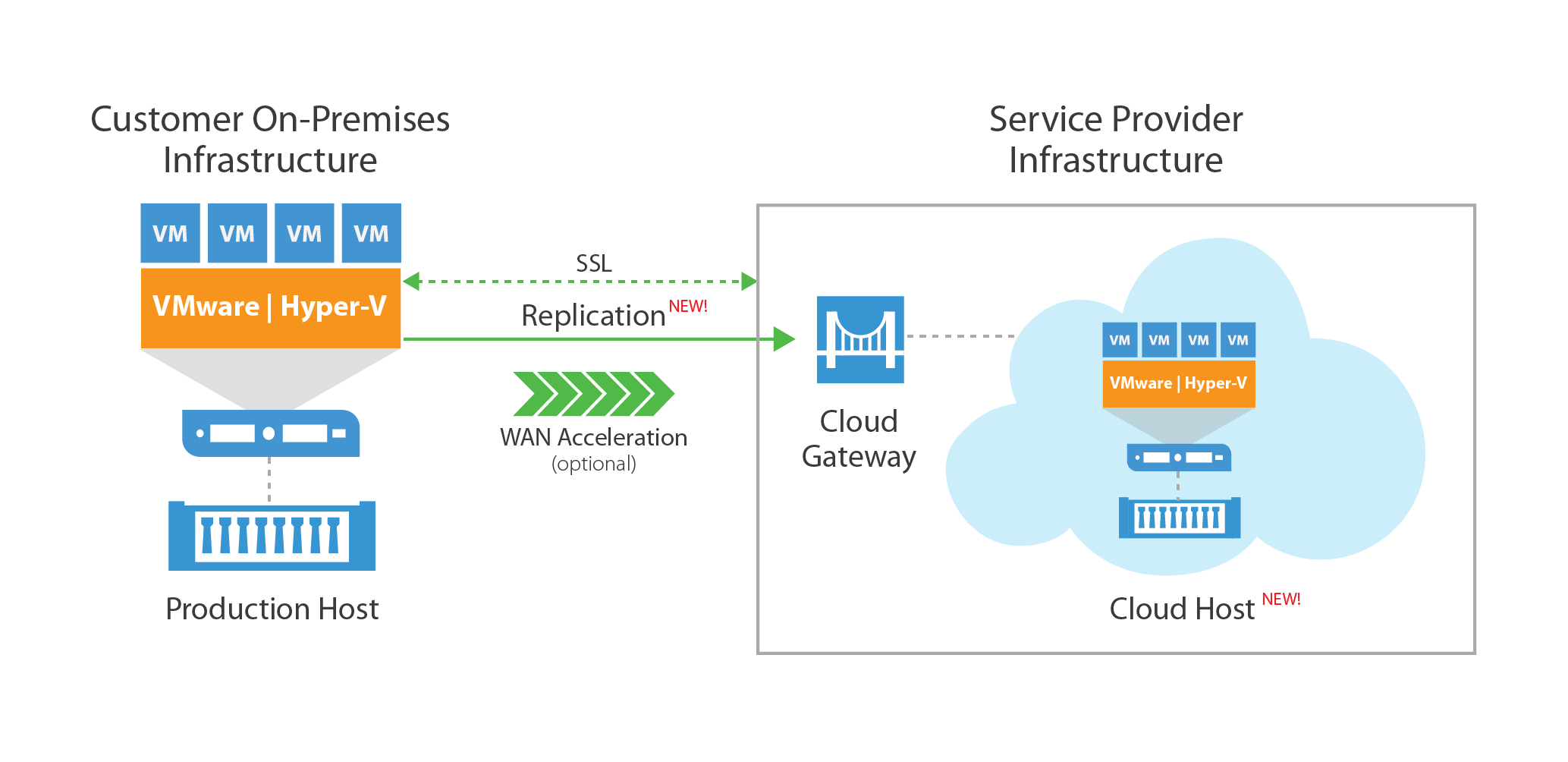
Last week Veeam announced that version 9 of Backup & Replication will feature a new addition to it's Cloud Connect product...Replication for Service Provider...

Depending on what you read, certain areas of the IT Industry are telling us that there is a freight train coming our way…and that train is bringing with it c...

It's that time of year again! VMWorld 2015 will creep up upon us and before you know it we will all be scrambling for tickets and last minute flights and acc...
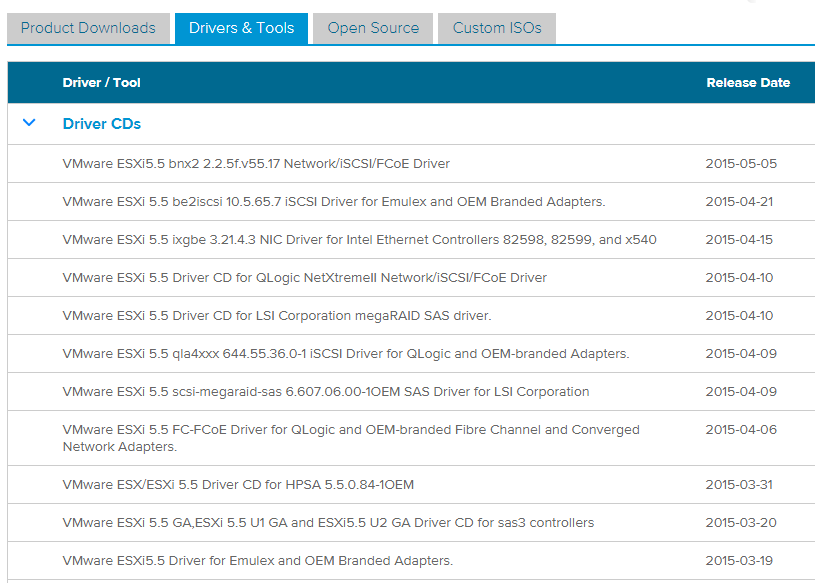
Today I needed to update an Emulex NIC Driver for an new host that I installed using the VMware ESXi 5.5 Update 2 base image. I needed to chase up the latest...
The Top vBlog Voting for 2015 at vSphere-land.com which is headed up and run by Eric Sebert ( @ericsebert ) is now open. http://www.surveygizmo.com/s3/203297...

Last week I attended my second Melbourne VMUG User Conference. The UserCon was again well attended and the Melbourne VMUG Team did a great job putting togeth...
I’m honoured to be recognized as a VMware vExpert for 2015…this is my 4 th year as a vExpert and without doubt the passion that drives this community remains...
In celebration of Australia Day ...and this blogs 100th Post... I have put together an RSS Widget that feeds from the AussievMafia site . RSS Feed Widget The...

The tweet below was posted last night...24 hours later I have found myself in a much better place and certainly free of the thoughts that caused me to vent a...
Over the last 10-15 years there have been many buzz words and phrases conceived by IT professionals which are then hijacked by marketing spinsters that end u...
Time flies when you are having fun! 2014 from a work point of view was challenging at times...but overall I felt a lot was achieved. In my last couple of new...

I tweeted recently that IT Professionals at some level must love pain...All through my working life I've dealt with outages and issues that cause myself and ...
One of the new Objectives in the VCAP-DCA 550 is around the vSphere Replication Appliance. The Blueprint specifics that there will be one Replication Applian...
"We are 4x cheaper with better technology versus VMware." I've been fairly open in my opinion against the latest round of Microsoft FUD coming out of their W...
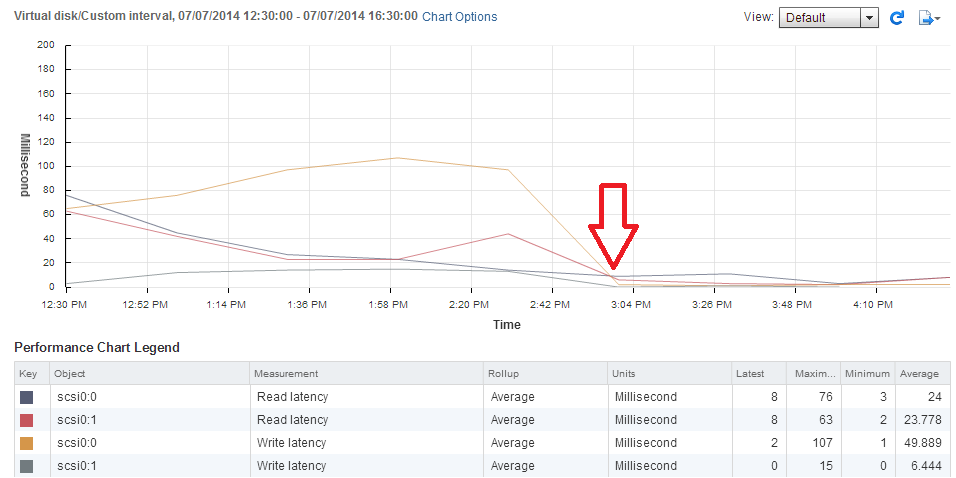
There is another NFS bug hidden in the latest ESXi 5.x releases...while not as severe as the 5.5 Update 1 NFS Bug it's been the cause of increased Virtual Di...
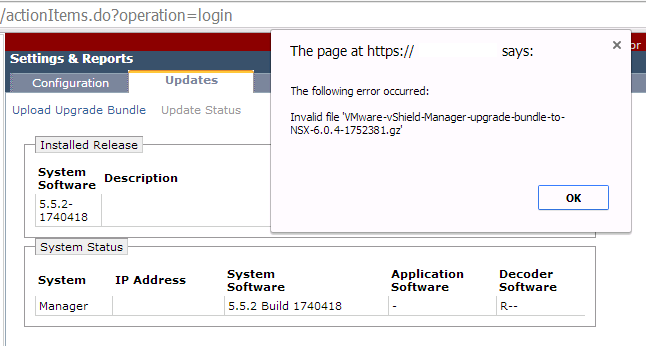
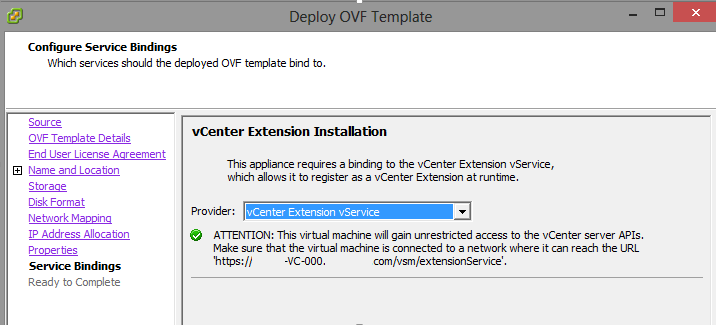
This is a really quick NSX Byte..but one that could save you some head scratching when looking to upgrade your vShield Manager to the NSX Manager. If you get...
![CloudPhysics: Enhanced Storage Analytics Cards [Part 1] - Datastore Contention](/images/2014/04/cp_s_1.png)
The guys at CloudPhysics have been busy behind the scenes of late working on improving an already great Analytic and Monitoring platform and recently I was a...
I'll put it out there... I am addicted to Twitter. I'd be lost without it...for better or worse I rely heavily on the streams of 140 character updates to get...
Seems that all bloggers I follow these days post a review on the year that's been...in a short summation, my 2013 was extremely satisfying . Reading through ...
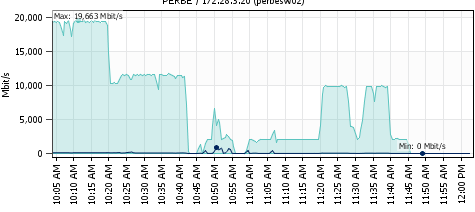
We have been conducting performance and stress testing of a new NFS connected storage platform over the past month or so and through that testing we have see...
vForum returns to the Sydney Convention and Exhibition Center next week and I'll be attending for the 3rd year in a row, but this time around I'll be there w...

Had an interesting occurrence pop up early in the week while we where adding a new Datastore to a vCloud Hosting Zone. We are running vCloud Director 5.1.2 a...
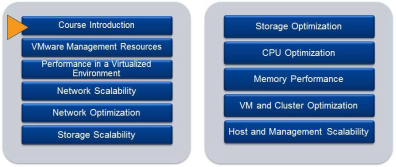
While it's fresh in my head, I thought I might get a short post up reviewing the Optimize and Scale Course I just completed this week. Overall I was impresse...
I spent the last week on holiday in the Wine Region of Western Australia’s South West . I've been holidaying down south since I was a teenager and I've seen ...
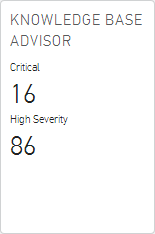
I've been lucky enough to have been early access to a new Card from the guys at CloudPhyics which, at it's core lets VMware admins quickly and precisely get ...
For those that had been keeping up with my Twitter feed over the past couple of months, you may have picked up on the hashtag #direction being used a couple ...
Almost exactly 12 months ago to the day I kicked off this site with this article describing my journey in virtualization leading up to my first vExpert 2012 ...
The boys at CloudPhysics are working hard behind the scenes at adding new features to their current stable of Analytic Cards based on data collected from t...
I was luckey to attend PEX at Australia Technology Park this week and thought I would share some of my take always. The venue was a little different to what ...
During last weeks #APACVirtual Podcast ( Episode 70 – Engineers Anonymous pt1 – Engineer2PreSales ) the panelists (of which, I was one) where discussing...
Recently we have experienced a series of DDoS attacks against client hosted sites that resulted in varying level of service outages to hosted services across...
Last weekend I signed up for an account at MEGA . This is @KimDotCom 's new venture attempting to send a big F-U to the regulatory forces that are accusing...
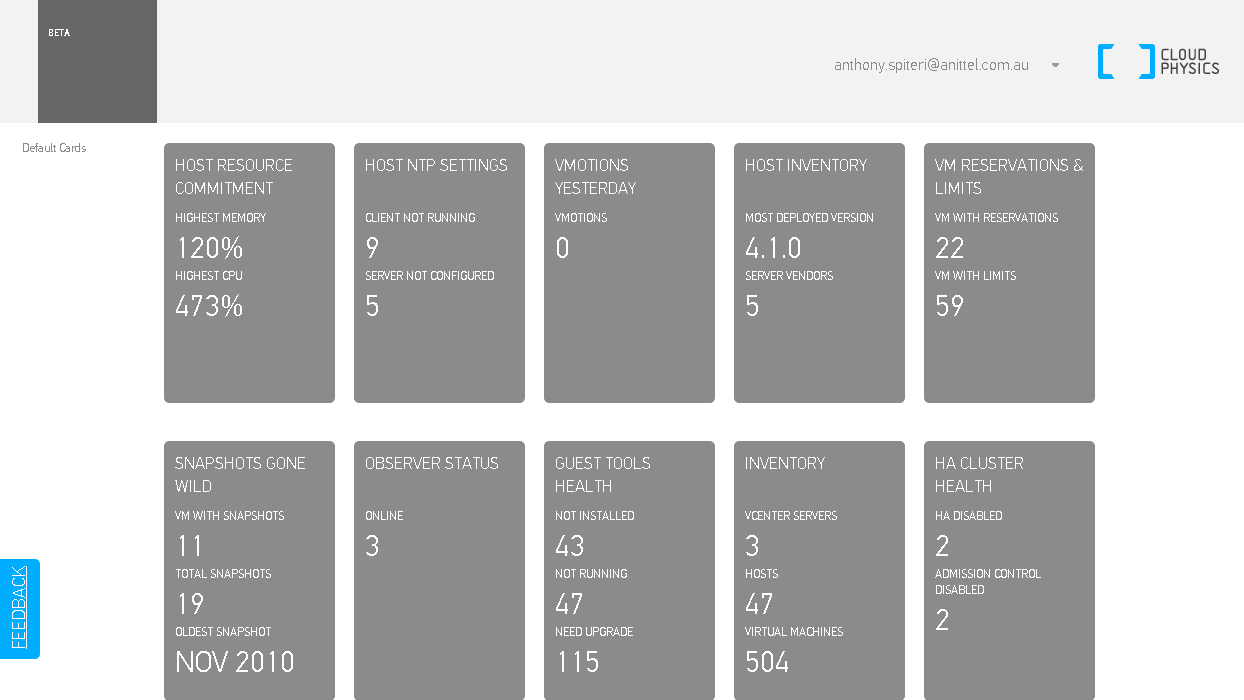
I first came across CloudPhysics just before VMWorld 2012. For a general overview, go here : I am a massive fan of analytics and trend metrics and I use a ...
Just thought I'd open the new year with a quick post about my expectations for 2013 from a technical/personal point of view. I've been a little slack in my B...
A few years ago there was a theory put forward by a certain Apple CEO that we were entering the Post PC Era…while I have never subscribed to that theory (w...
This is just a quick post from somewhere in between SF and LA. Got to say that Virgin America is very impressive. Seats are comfortable and the entertainment...
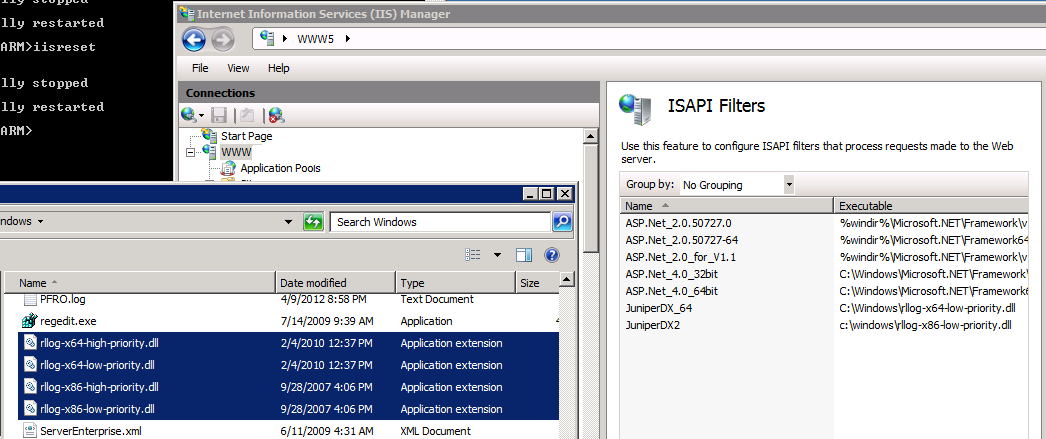
If you are NAT'ing public to private addresses with a load balancer in between your web server and your Gateway/FireWall device you might come across the sit...
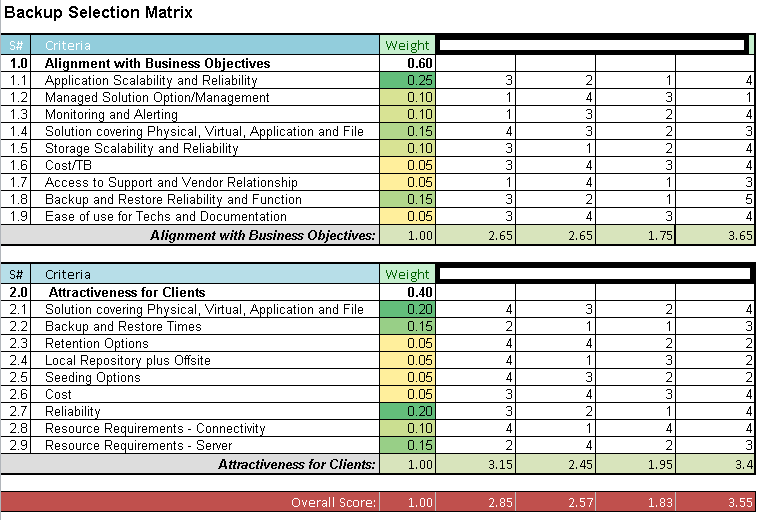
It's been a while since my first post on this topic, but there has certainly been a lot of thought and effort put into this subject since then. At first IÂ e...
VMware announced overnight that their aquired Private Social Media Platform SocialCast is to have full features enabled for 50 users. http://www.vmware.com/c...
Ill put this right out there! I would rather live in a world without Backup and Recovery. I have burnt countless hours and hair follicles working my way thro...
This post signifies my return to the blogging world... I last actively blogged in late 2008 just before I signed up for Twitter. Forward 4 years, and nearl...