VSAN Permanent Disk Failure Detection – Health Status vs Hardware Status
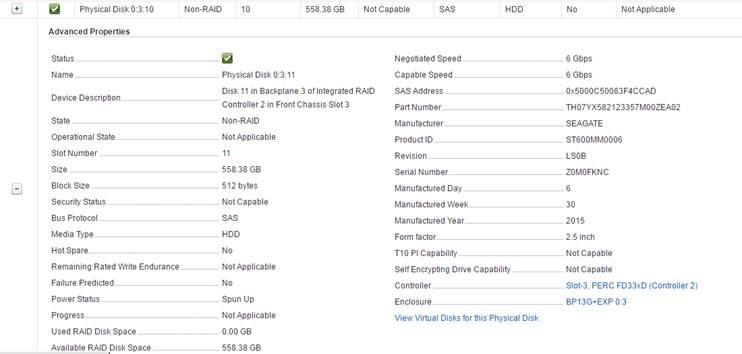
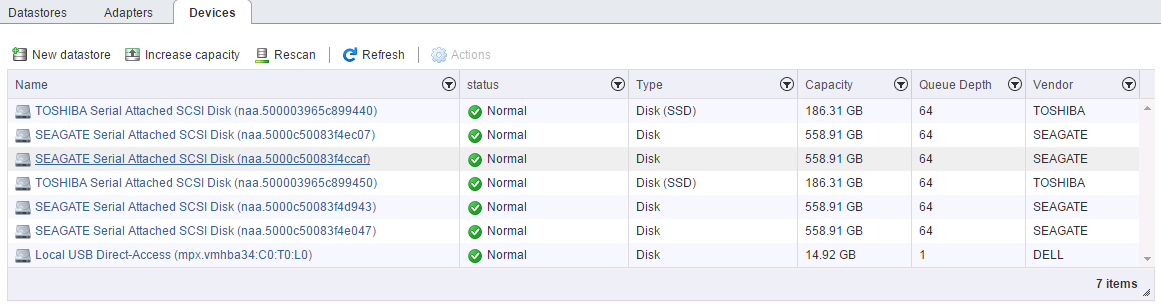
A month or so ago I had one of our VSAN Management Clusters Health Status flag that there was a failed disk in one of the hosts disk groups. VSAN worked quickly and very efficiently to start an evacuation of the data on the impacted host by triggering a resync operation. Once the data was resynced I checked to see the status of the disk that had flagged with the error…Interestingly enough the disk wasn’t being flagged under the ESXi hardware status or in the DELL iDRAC as shown below:
Searching through the vmkernel.log for the affected disk I came across:
2016-05-17T11:50:03.390Z cpu0:33401)NMP: nmp_ThrottleLogForDevice:3178: Cmd 0x28 (0x43a58090dec0, 0) to dev "naa.5000c50083f4ccaf" on path "vmhba2:C0:T11:L0" Failed: H:0x0 D:0x2 P:0x0 Valid sense data: 0x4 0x32 0x0. Act:NONE
The SCSi sense code H:0x0 D:0x2 P:0x0 Valid sense data: 0x4 0x32 0x0 decoded is:
ASC/ASCQ: 32h / 00h
ASC Details: NO DEFECT SPARE LOCATION AVAILABLE
Status: 02h - CHECK CONDITION
Description: When the target returns a Check Condition in response to a command it is indicating that it has entered a contingent allegiance condition.
This means that an error occurred when it attempted to execute a SCSI command. The initiator usually then issues a SCSI Request Sense command in order to obtain a Key Code Qualifier (KCQ) from the target.The status is being returned from the device and indicates a hardware failure despite the iDRAC not reporting any issues. On top of that the ESXi Host Client status of the disk looked normal.
 Initially the sense error was being reporting as being be due to a parity error but not a hardware error on the disk meaning that the disk wasn’t going to be replaced. DELL support couldn’t see anything wrong with the disk from the point of view of the FX2s Chassis, Storage Controller or from the ESXi hardware status. DELL got me to install and run the ESXi PERC command line onto the hosts (which I found to be a handy utility in it’s own right) which also reporting no physical issues.
PERCCLI: http://www.dell.com/support/home/us/en/19/Drivers/DriversDetails?driverId=XY978
As a temporary measure I removed the disk from the disk group and brought the host back out of maintenance mode to allow me to retain cluster resiliency. Later on I updated the Storage Controller Driver and Firmware to the current supported version and after that I added the disk back into the VSAN Disk Group and then cloned a VM onto that host ensuring that data was placed on the hosts disk groups. About 5 minutes after copy the host has flagged and this time the disk has been marked with a permanent disk failure.
Initially the sense error was being reporting as being be due to a parity error but not a hardware error on the disk meaning that the disk wasn’t going to be replaced. DELL support couldn’t see anything wrong with the disk from the point of view of the FX2s Chassis, Storage Controller or from the ESXi hardware status. DELL got me to install and run the ESXi PERC command line onto the hosts (which I found to be a handy utility in it’s own right) which also reporting no physical issues.
PERCCLI: http://www.dell.com/support/home/us/en/19/Drivers/DriversDetails?driverId=XY978
As a temporary measure I removed the disk from the disk group and brought the host back out of maintenance mode to allow me to retain cluster resiliency. Later on I updated the Storage Controller Driver and Firmware to the current supported version and after that I added the disk back into the VSAN Disk Group and then cloned a VM onto that host ensuring that data was placed on the hosts disk groups. About 5 minutes after copy the host has flagged and this time the disk has been marked with a permanent disk failure.
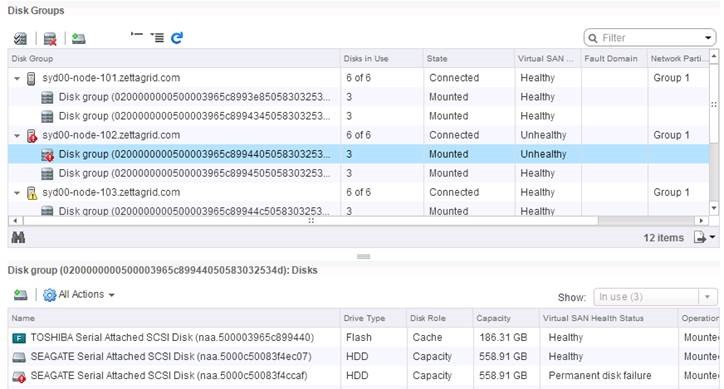
2016-05-26T04:14:23.979Z -102 vmkernel: cpu19:840913)WARNING: LSOM: LSOMEventNotify:6127: Virtual SAN device 52fe56e9-7d1e-96f0-45d7-d13167c92992 is under permanent error.This was different behavior to what I first experienced before the firmware and driver update, however the iDRAC and ESXI Hardware status was still showing the disk as being good. This time however the evidence above was enough to get DELL to replace the disk and once replaced I tested a clone operation onto that host again and there where no more issues. So make sure that you are keeping tabs of the VSAN Health Status as it seems to be a little better or sensitive at flagging troublesome disks than what ESXi is and even the hardware controllers. Better to be overcautious when dealing with data! References: https://kb.vmware.com/selfservice/microsites/search.do?language=en_US&cmd=displayKC&externalId=2109874 http://www.dell.com/support/home/us/en/19/Drivers/DriversDetails?driverId=XY978
2 Commentsarchived