
Opinion: VMware and NVIDIA Step Up on Private AI for Enterprises
It's not a surprise that Generative AI featured heavily as a topic at VMware Explore US last week in Vegas. 2023 is the year that most large tech companies j...
Category
392 posts
It's not a surprise that Generative AI featured heavily as a topic at VMware Explore US last week in Vegas. 2023 is the year that most large tech companies j...

I must say... it was good to be back at the Mascone Center and San Francisco for VMware Explore 2022. Some people might question my excitement at getting bac...

Ok, here we are... it's been three years since VMworld 2019 and we are back next week in San Francisco at the Mascone Centre. But we are not attending VMworl...

It's been a while since i've done a vSphere specific Quick Fix post, but the great thing about tinkering and labbing is that you run into situations and corn...

I remember back a few years ago when VMware first launched their Flings how useful some of them where (and still are). Seemed like no matter what area of the...
Over the past week or so, i've been diving back into working on VMware Cloud on AWS ... for the most, the experience hasn't changed that much since I started...

One of the things I wanted to do this year was get back into technologies, applications, platforms or solutions that I have drifted away from over recent yea...

VMworld 2021 is today! This year, once again we will all be experiencing the conference remotely and a little more delayed than is usual for VMworld (US). Wi...

VMworld 2021 is different again this year a month later than usual, we are now only five days away from kicking off Virtually. The content catalog for the Vi...
Though Kubernetes has made significant headways into being accepted as the way forward in terms of how modern applications are developed, deployed and manage...

When Veeam Backup & Replication v11 went Generally Available on the 24th of February I posted the What’s in it for Service Providers blog. In that post I bri...

When Veeam Backup & Replication v11 went Generally Available on the 24th of February I posted the What’s in it for Service Providers blog. In that post I bri...

This week VMware is holding an online event to make and announcement around its vision for Application and Cloud Transformation . What does that exactly mean...

I haven't done one of these VMware Update release posts in a while... Having attended the #vExpert pre-brief a couple weeks back I thought there was enough r...

v11 was officially Launched and GA'ed last week meaning customers could get their hands on the next flagship release of Veeam Backup & Replication. Since the...

A Challenging Year for Community For a lot of us in the IT Industry, 2020 made it difficult to advocate technology like we had done in previous years. No dou...

2020 Update : It seems as though this issue also pops up if doing a major version upgrade of the VCSA through the migration option. I was getting this error ...

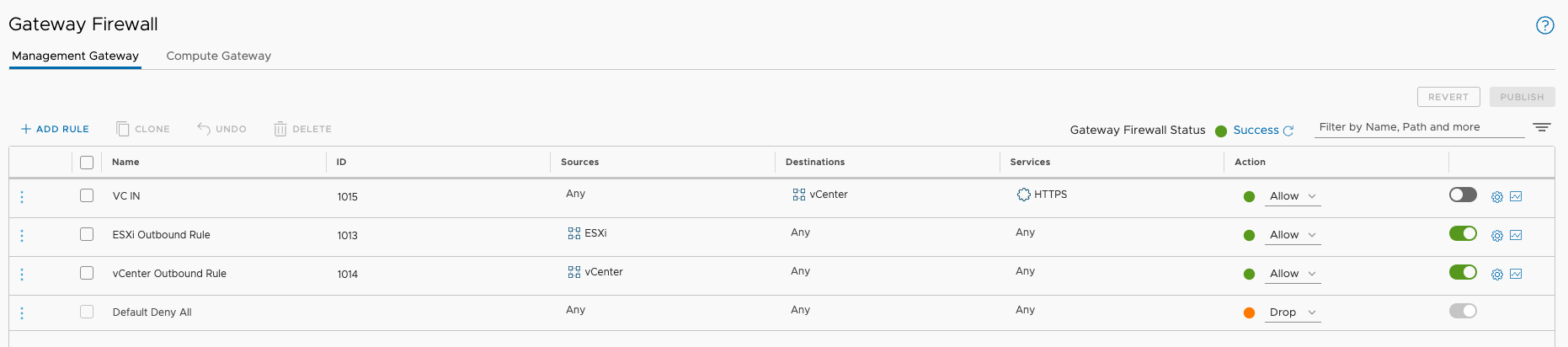
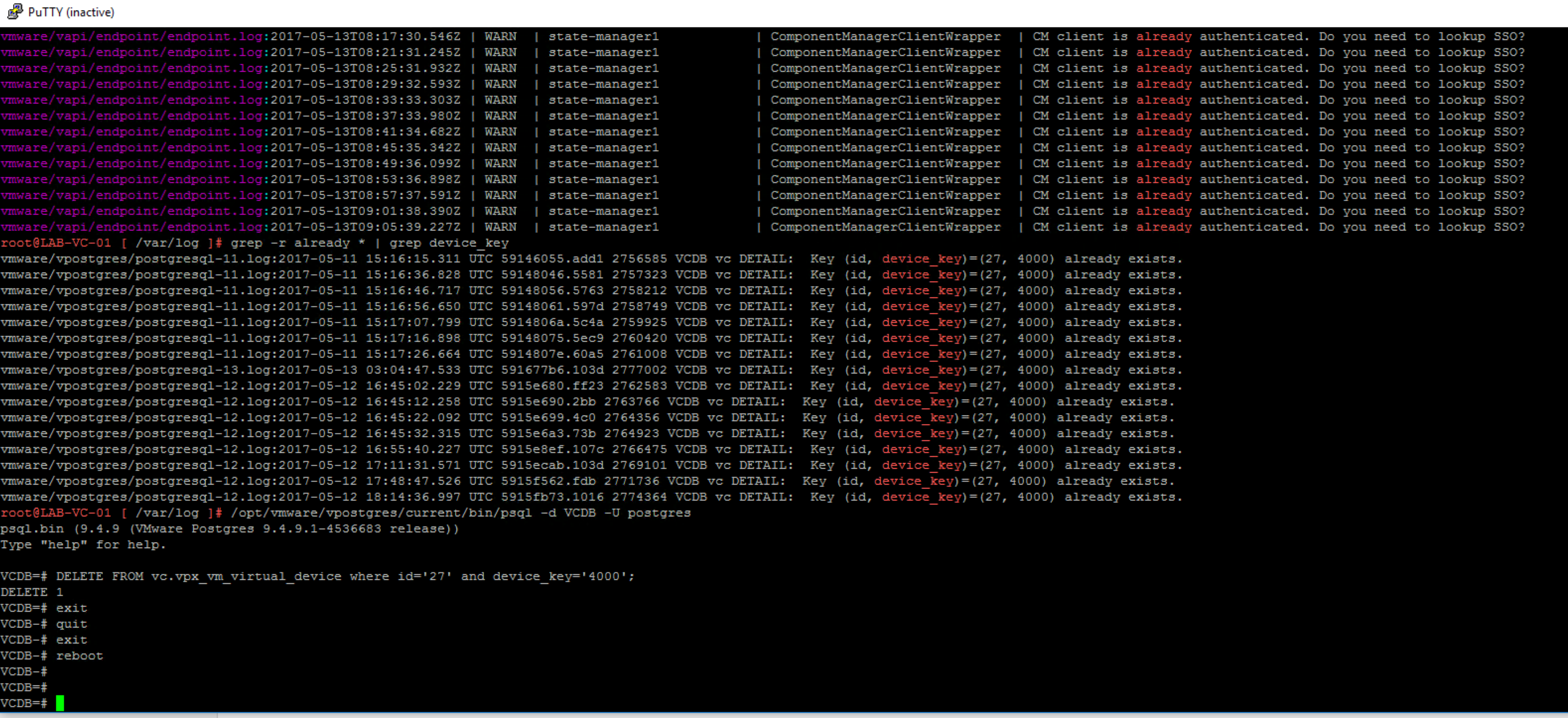
Over the past few weeks I've posted a couple of articles that should help people new to vSphere with Tanzu . There are some common hurdles that can pop up. I...
2020 Edit: Seems like this error has been updated in vSphere 7.x to be a little more friendly and less terminal. The old error I referenced below was somethi...

Over the past week I've posted a couple of articles that should help people new to vSphere with Tanzu . There are some common hurdles that can pop up. I've n...
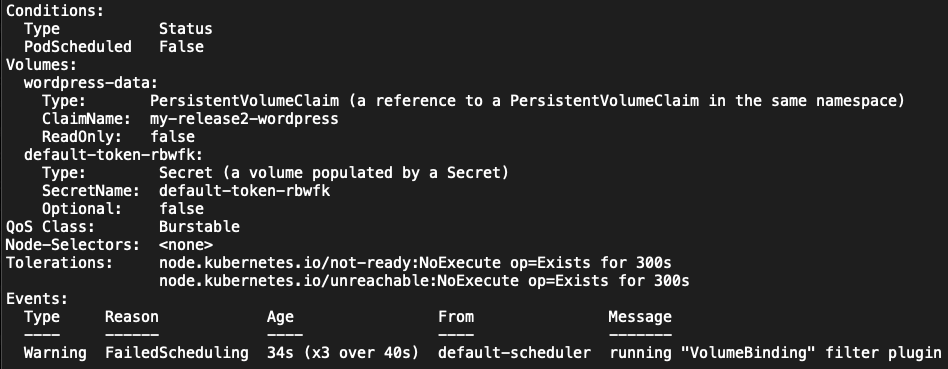
I've been grappling with vSphere with Tanzu for the past week or so and while I haven't completely nailed how things operate end to end in this new world, i'...

I've been grappling with vSphere with Tanzu for the past week or so and while I haven't completely nailed how things operate end to end in this new world, i'...
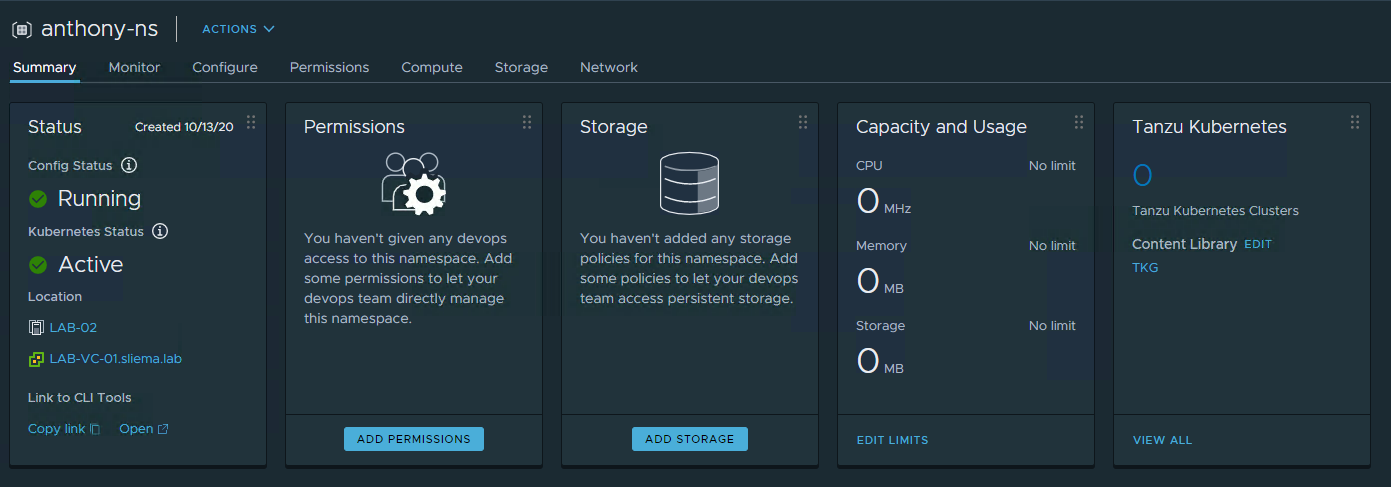
VMware released Update 1 of vSphere 7 last month and one of the big things to come out of that release was the ability to deploy Tanzu Basic which is vSphere...
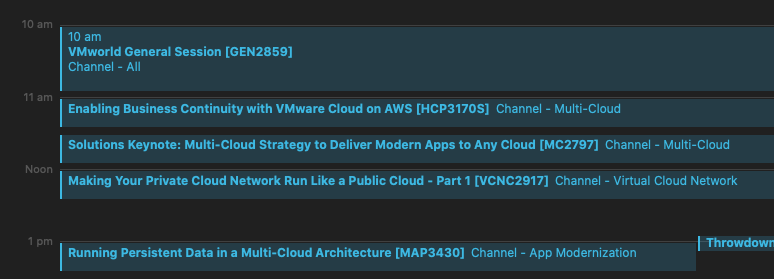
VMworld 2020 is happening today! And as I have banged on about over the past week, this is a very very different VMworld. No one will be lining up for overfl...

VMworld has been leveraged by a lot of people to help advance their careers with a lot of advancement seeded by personal interactions at the conference. Soci...

VMworld 2020 is different this year... but in this COVID year, we are only five days away from kicking off Virtually. The content catalog for the Virtual eve...

It is crazy to think that we could celebrate (those of us brave enough to admit it) the birthday of the piece of software. Throughout modern history, softwar...

Over the weekend, we released the v10a ( Build 10.0.1.4854 ) release of our flagship product, Veeam Backup & Replication. This is the first major update to v...

I'm a fan of a good streak... but 2020 has forcefully ended a couple of existing streaks that I had in play. One of those was my annual trip over to Melbourn...

VMware still represents a strong focus for the foundation of our core platform supportability. VMware workloads are still easily the most protected workloads...
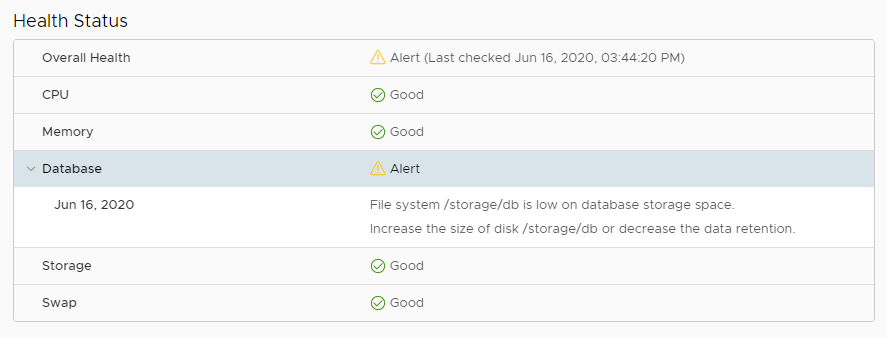
I had a situation earlier this week where the VMware SDK/API service was being reported as offline. I was triggered by some failed backup jobs which made me ...

This is a very quick post to let people know that from the first of June, till the 20th of June, applications are open for the half yearly intake into the VM...

It shouldn't come as a surprise that I'm writing about an event that is being held online... especially in this very moment in time. 2020 is the year of the ...
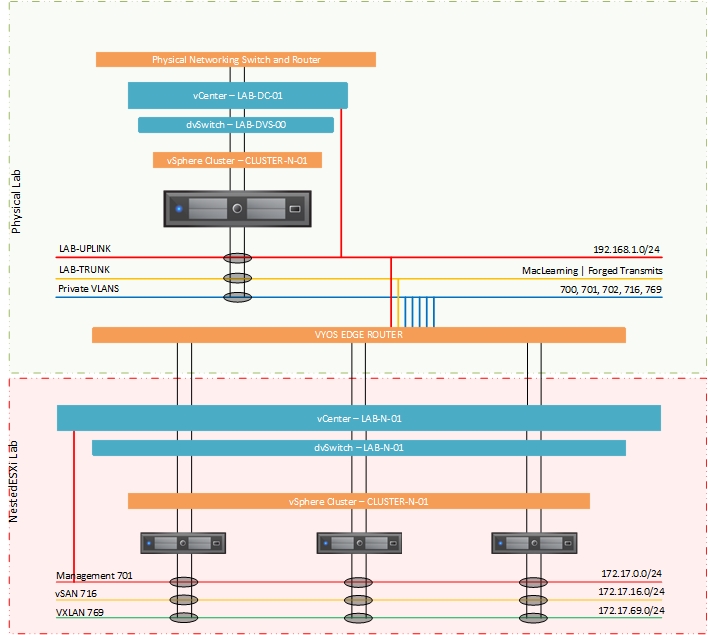
Back for part two of this look at how I went about configuring a single host for NestedESXi deployments. In the previous post I looks at the physical configu...
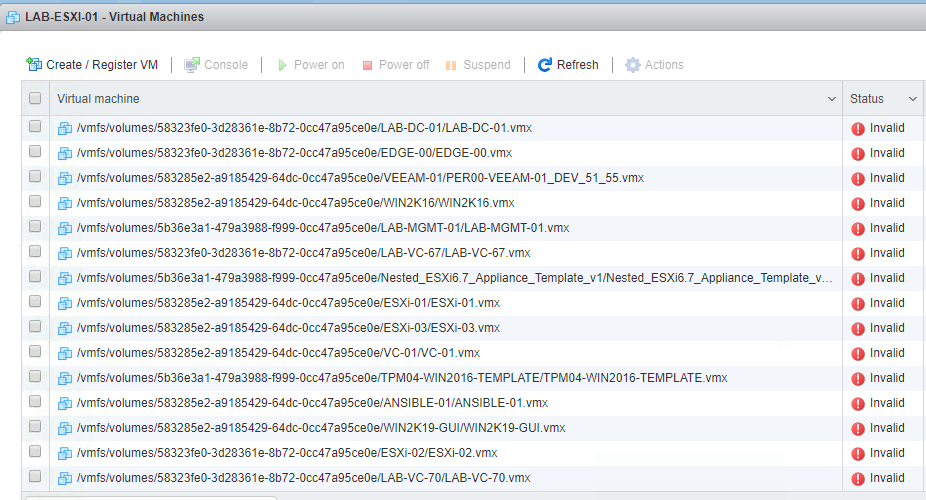
As usual, I like to jump right into software upgrades to test out new functionality (on none production systems of-course). With the GA of vSphere7 overnight...
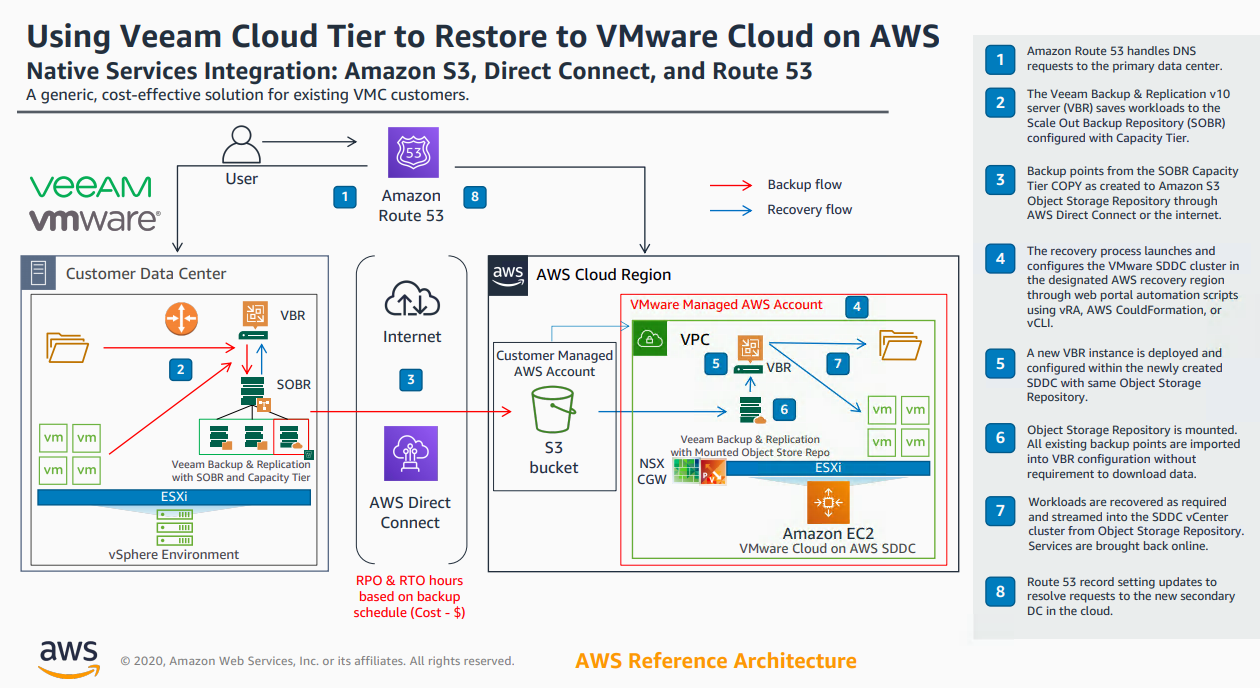
With the release of v10 of Backup & Replication came significant enhancements to the Cloud Tier. As I wrote about here , we introduced Copy Policy , Immutabi...
I've should have written this article a long long time ago! In fact, i've been promising certain people that I would write this up for a number of years. The...

It didn't seem that long ago that at VMworld 2019 in San Francisco where VMware announced Project Pacific. At the time I wrote about how I thought that it wa...
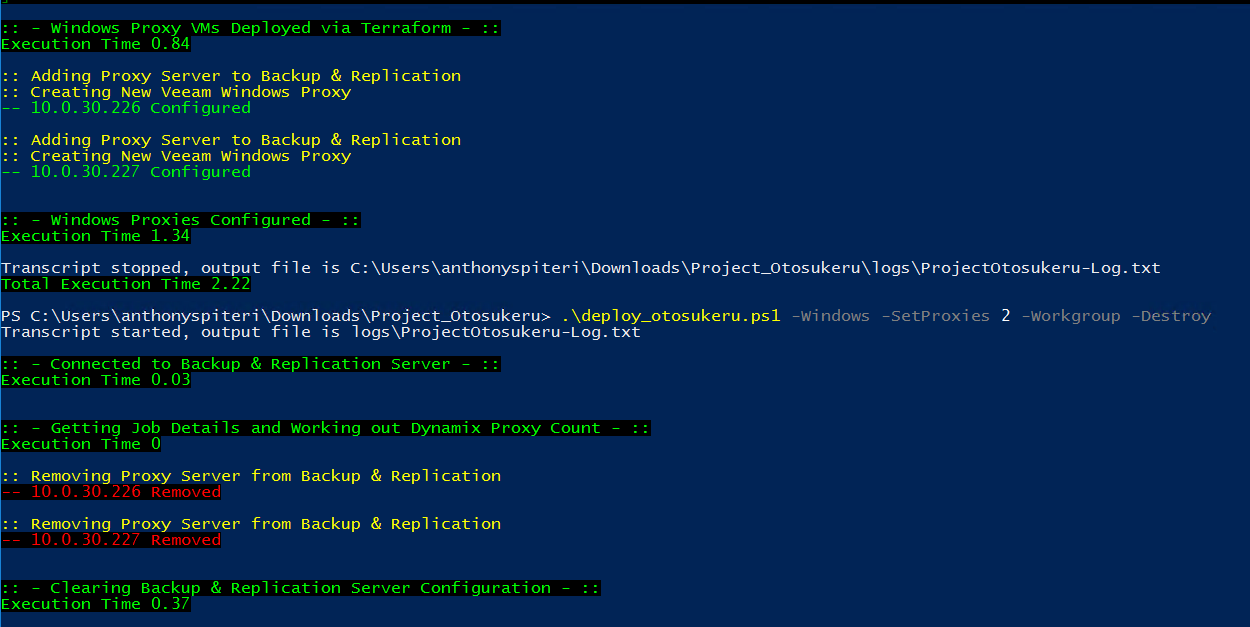
My recent obsession with automation and Infrastructure as Code in general has resulted in a lot of efficiencies in my day to day work life. Where I used to d...
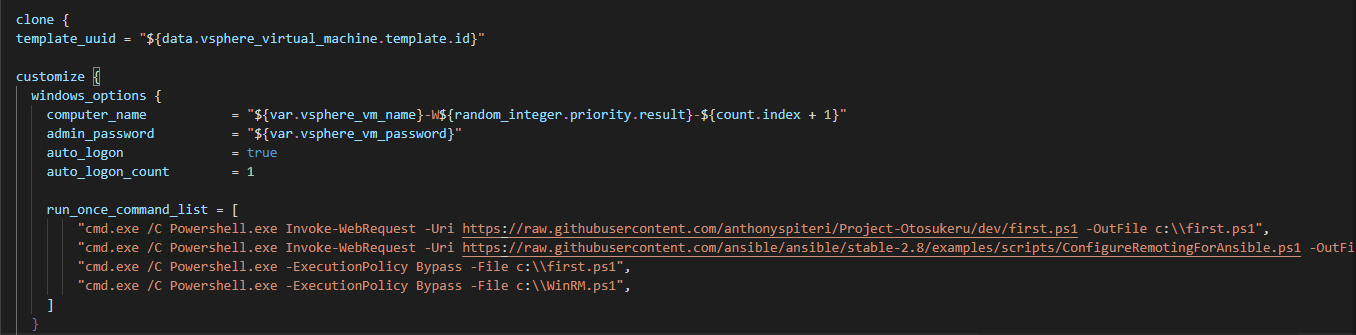
Bootstrapping Windows during automated deployments is one of the more frustrating aspects of working with templates that are being deployed by Infrastructure...

Today, VMware announced the vExpert class of 2020 and as per usual this generated lots of social media buzz as well as the now customary backlashes that have...
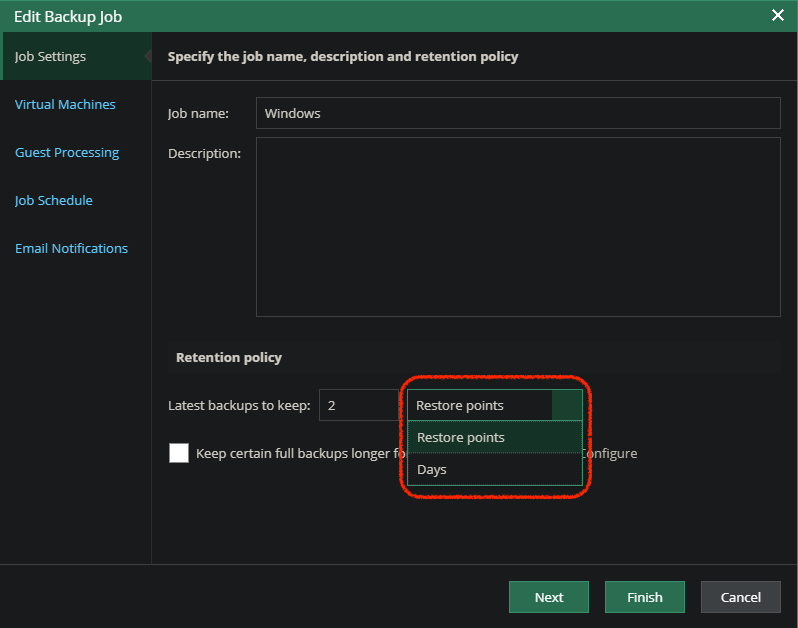
Version 10 of Veeam Backup & Replication right around the corner as we rapidly approach GA. The RTM has been out for our service provider partners for a coup...

Over the last few years the amount of CBT related issues has decreased significantly from VMware. I remember back in my previous roles of having to deal with...
Over the last few years the amount of CBT related issues has decreased significantly from VMware. I remember back in my previous roles of having to deal with...
![vCloud Director is no more... Long Live vCD! [VMware Cloud Director Service for VMC]](https://i1.wp.com/anthonyspiteri.net/wp-content/uploads/2016/10/VMWonAWSvCD2.png?fit=1038%2C416&ssl=1)
There was a very significant announcement at VMworld Barcelona overnight, with the unveiling of a new service targeted at Managed Service Providers. VMware C...

In the continuing spirit of Terraforming all things, when I started to look into Ansible I wanted a way to have the base Control Node installed in a repeatab...
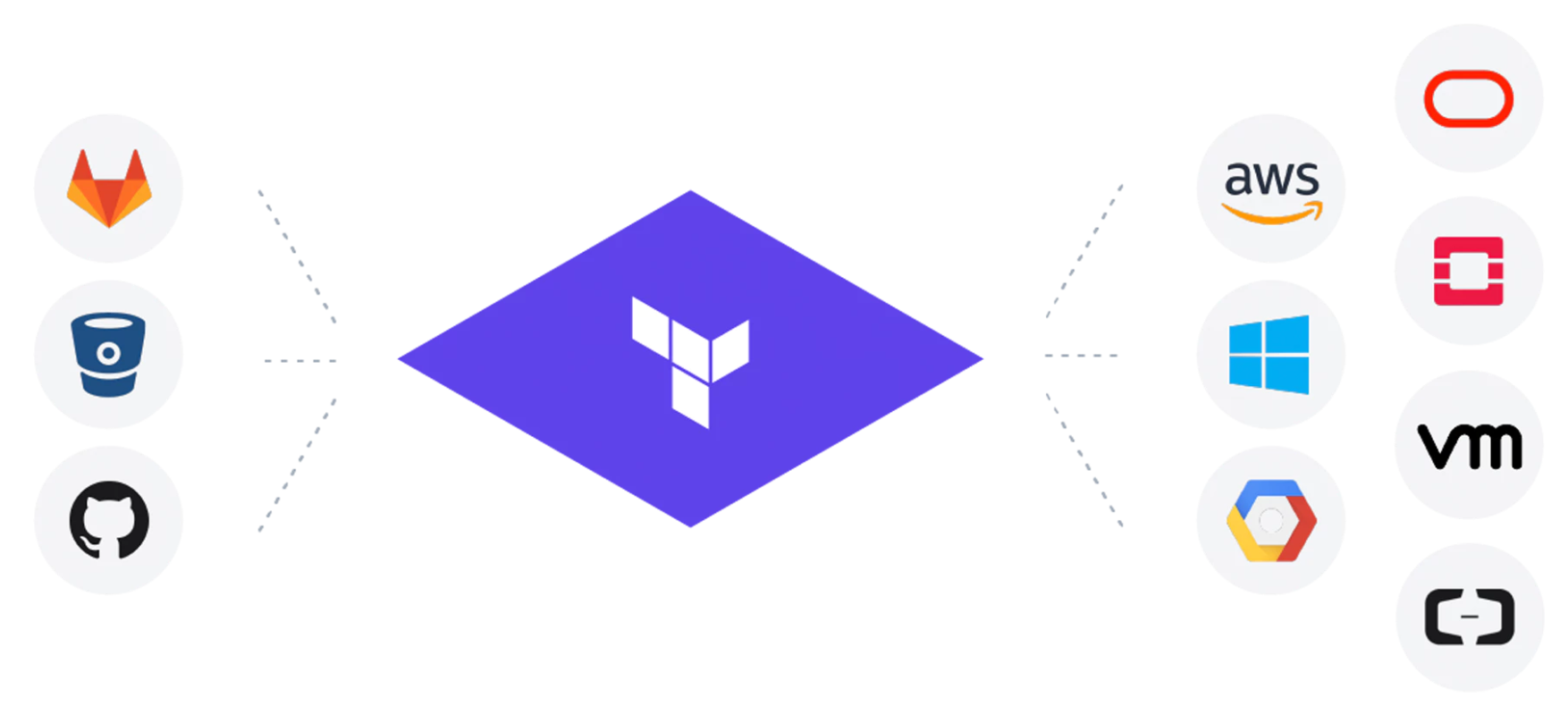
I've been working on a project over the last couple of weeks that has enabled me to sharpen my Terraform skills. There is nothing better than learning by doi...
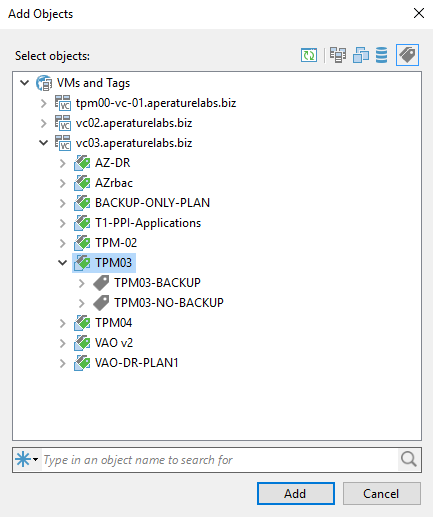
vSphere Tags are used to add attributes to VMs so that they can be used to help categorise VMs for further filtering or discovery. vSphere Tags have a number...
Terraform from HashiCorp has been a revelation for me since I started using it in anger last year to deploy VeeamPN into AWS . From there it has allowed me t...
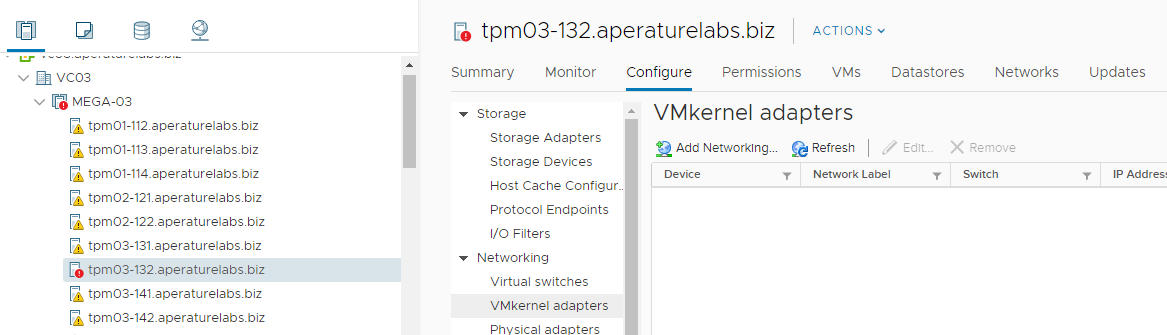
I had a really strange situation pop up in one of my lab environments over the weekend. vSAN Health was reporting that one of the hosts had lost networking c...

Apart from the K word, there was one other enduring message that I think a lot of people took home from VMworld 2019 . That is, that Dev and Ops should be co...

Kubernetes Kubernetes, Kubernetes... say Kubernetes one more time... I dare you! If it wasn't clear what the key take away from VMworld 2019 was last week in...

VMworld 2019 is happening tomorrow (It is already Saturday here) and as I am just about to embark on the 20+ hour journey from PER to SFO I thought it was be...

VMworld 2019 is now only a couple of days away, and I can't wait to return to San Francisco for what will be my seventh VMworld and third one with Veeam. It ...
Everything to do with VMworld this year feels like it's arrived at lightning speed. I actually thought the event was two weeks away as the start of the week....

That is probably the longest title i've ever had on this blog, however I wanted to highlight everything that is contained in this solution. Everything above ...
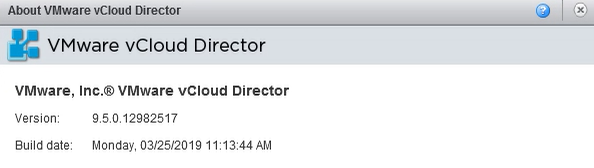
Late last week, on the same day as vCloud Director 9.7 was released to GA, an update was also released for vCloud Director 9.5.x which has been marked are cr...
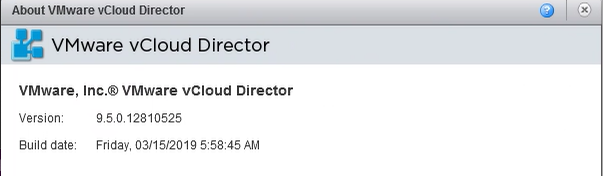
While we wait for the upcoming release of vCloud Director 9.7 next month (after the covers where torn off the next release in a blog post last week by the vC...
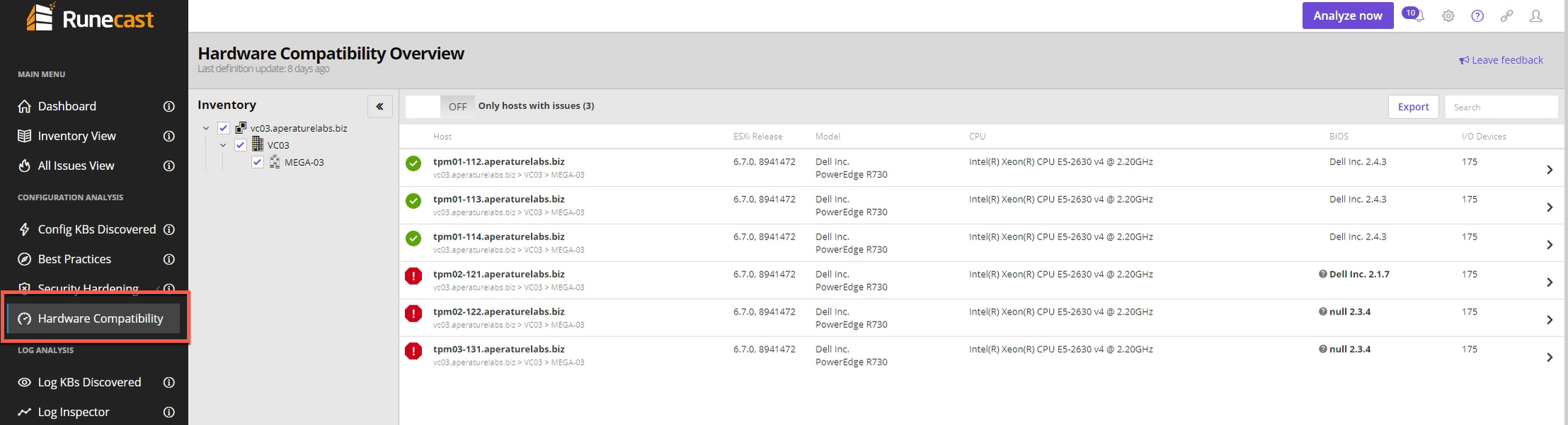
Two years ago at the 2017 Sydney and Melbourne UserCons, I spent time with a couple of the founders of Runecast, Stanimir Markov and Ched Smokovic and got to...

A few years ago I claimed that the Melbourne VMUG Usercon was the “Best Virtualisation Event Outside of VMworld!” …that was a big statement if ever there was...
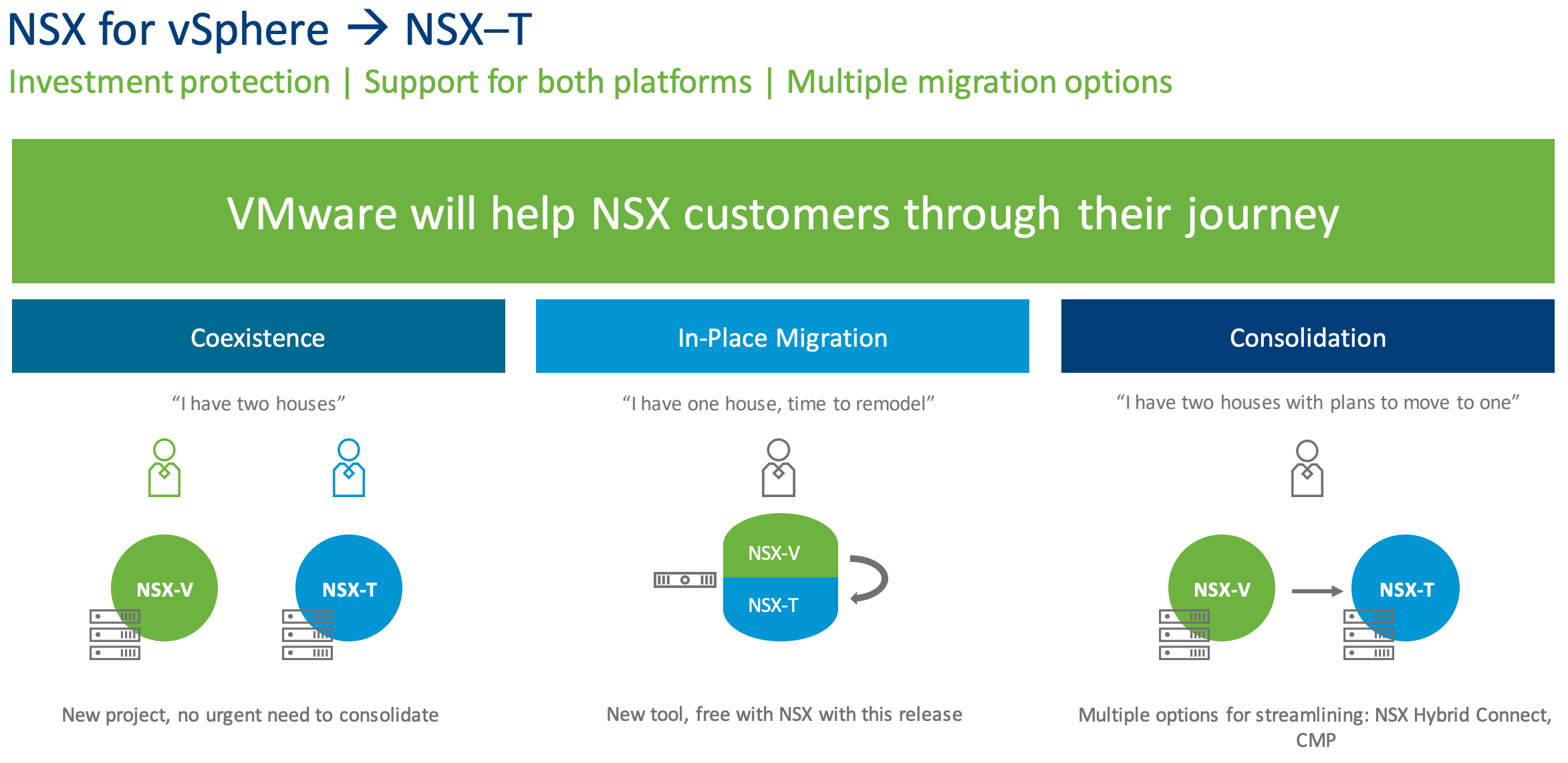
A little over two years ago in Feburary of 2017 VMware released NSX-T 2.0 and with it came a variety of updates that looked to continue to push NSX-T beyond ...

When looking at how to configure networking for interactions between a VMware Cloud on AWS SDDC and an Amazon VPC there is a little bit to grasp in terms of ...
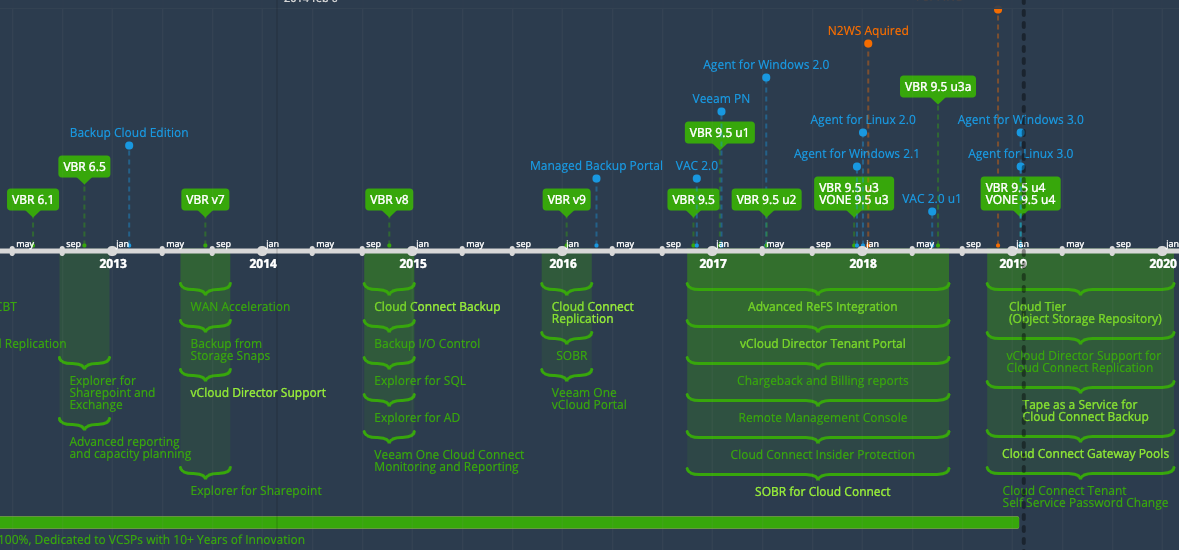
I remember the day I first came across Veeam. It was mid 2010 and I was working for Anittel at the time. We had a large virtualisation platform that hosted a...
Overnight, applications for the 2019 VMware vExperts where opened up and as per usual it's created a flurry of activity on social media channels and well as ...
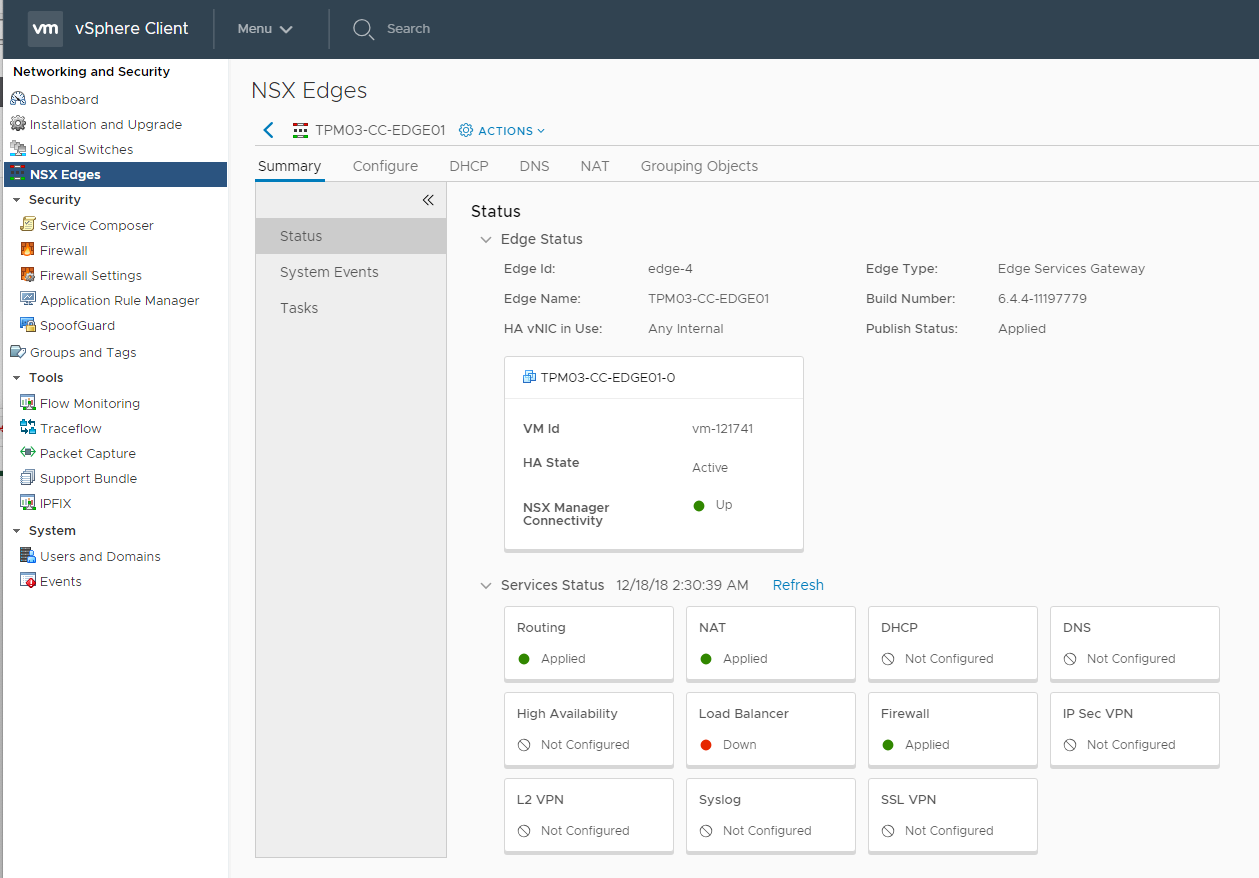
Last week VMware released NSX-v 6.4.4 ( Build 11197766 ) that contains a some new features and addresses a number of resolved issues from previous releases. ...
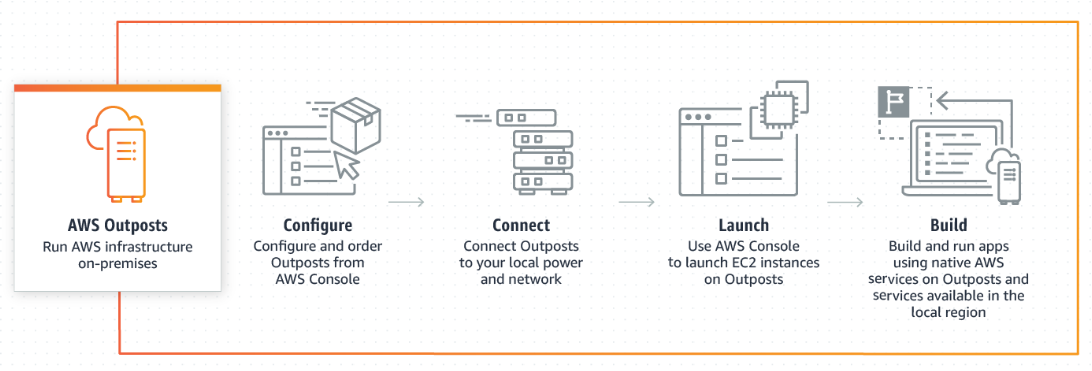
Now that AWS re:Invent 2018 has well and truly passed...the biggest industry shift to come out of the event from my point of view was the fact that AWS are g...

Last week VMware released vSphere 6.7 Update 1 . While the buzz around this release was less than the previous release it still contains a ton of enhancement...
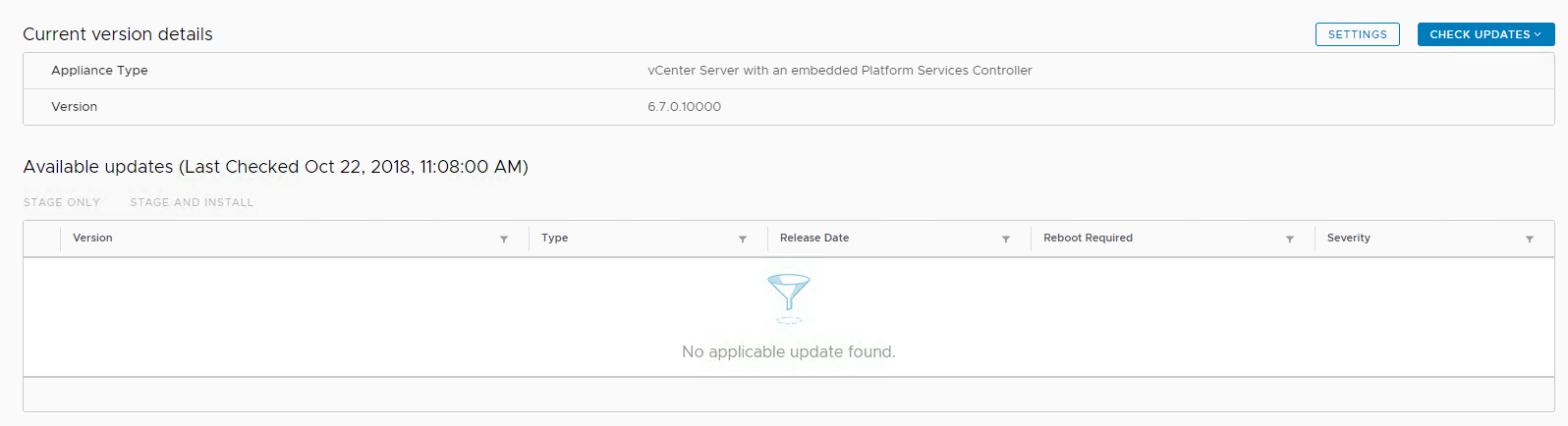
I had an issue with my VCSA today trying to upgrade to vCenter 6.7 Update 1 whereby the Management Interface Upgrade option was not detecting the update to u...
Last week I was looking to add the deployment of a local CentOS virtual machine to the Deploy Veeam SDDC Toolkit project so that it included the option to de...
Last week VMware released vCloud Director 9.5 ( build 10266189 ) which builds on the 9.1 release that came out earlier this year . This continues to deliver ...

As part of the Veeam Automation and Orchestration for vSphere project myself and Michael Cade worked on for VMworld 2018 , we combined a number of seperate p...
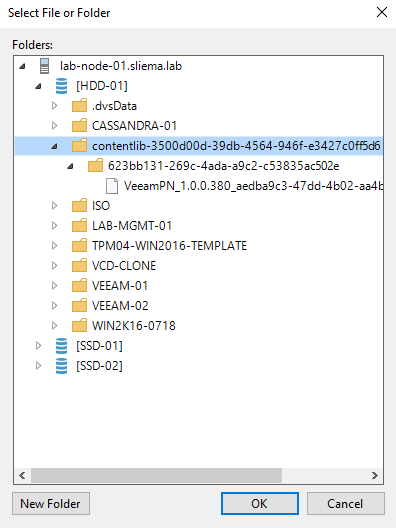
A question came up in the Veeam Forums this week about how you would backup the contents of a Content Library. As a refresher, content libraries are containe...
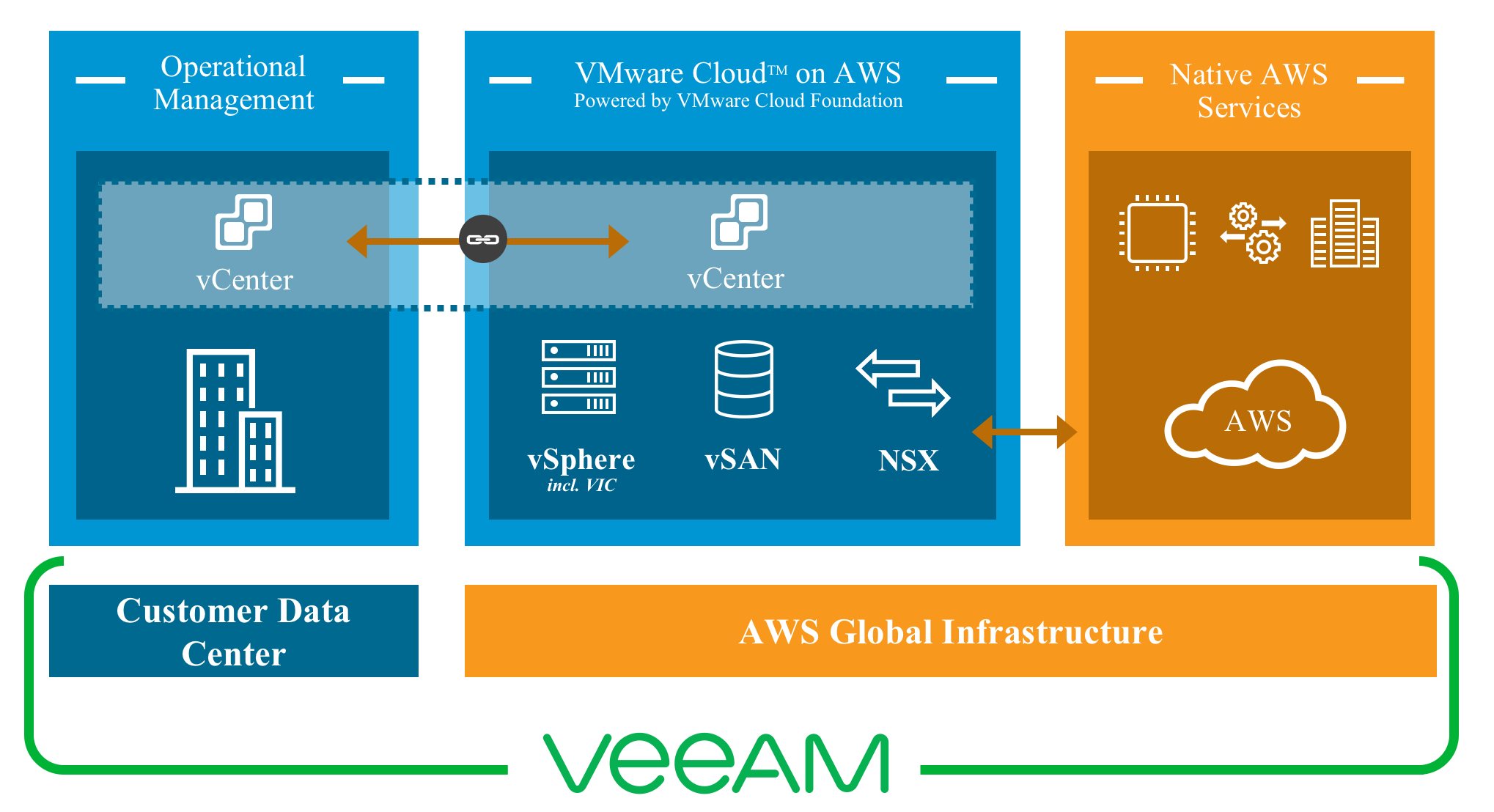
At VMworld 2018, myself and Michael Cade gave a session on automating and orchestrating Veeam on VMware Cloud on AWS . The premise of the session was to show...

VMworld 2018 has come and gone and after a couple of days recovery from the week that was, i’ve had time to reflect on what was a great week and an another g...

VMworld 2018 has come and gone and after a couple of days recovery from the week that was, i've had time to reflect on what was a great week and an another g...
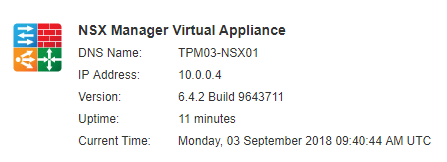
The week before VMworld, VMware released version 6.4.2 ( Build 9643711 ) of NSX-v. There is a lot of enhancements that Service Providers can take advantage o...
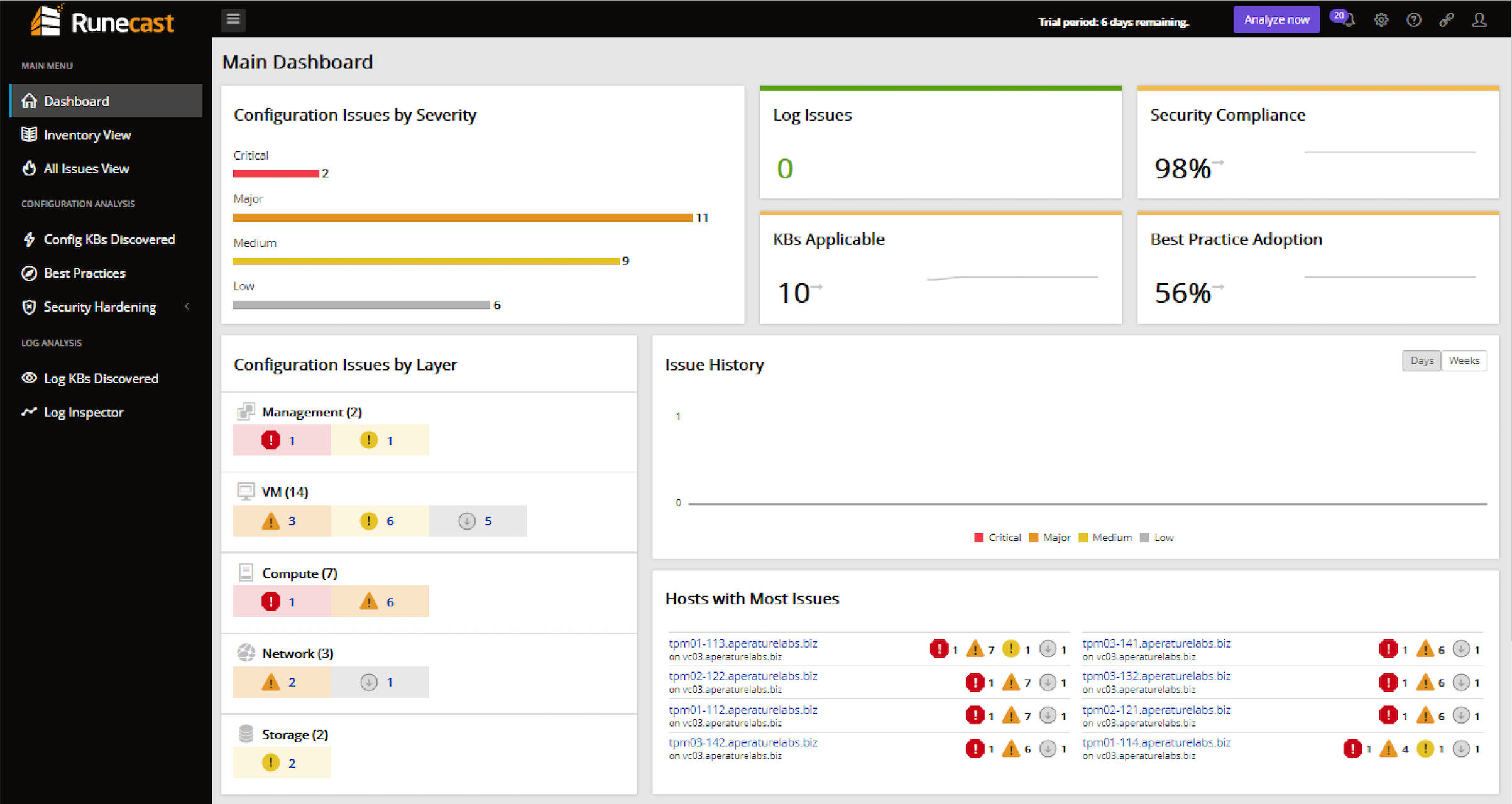
Earlier this week, Runecast released into General Availability version 2.0 of their vSphere analyser platform. I've been a keen follower of the progress of R...

VMworld 2018 is less than a week away, and I can't wait to fly into Las Vegas for my sixth VMworld and second with Veeam. It's been an interesting year or so...
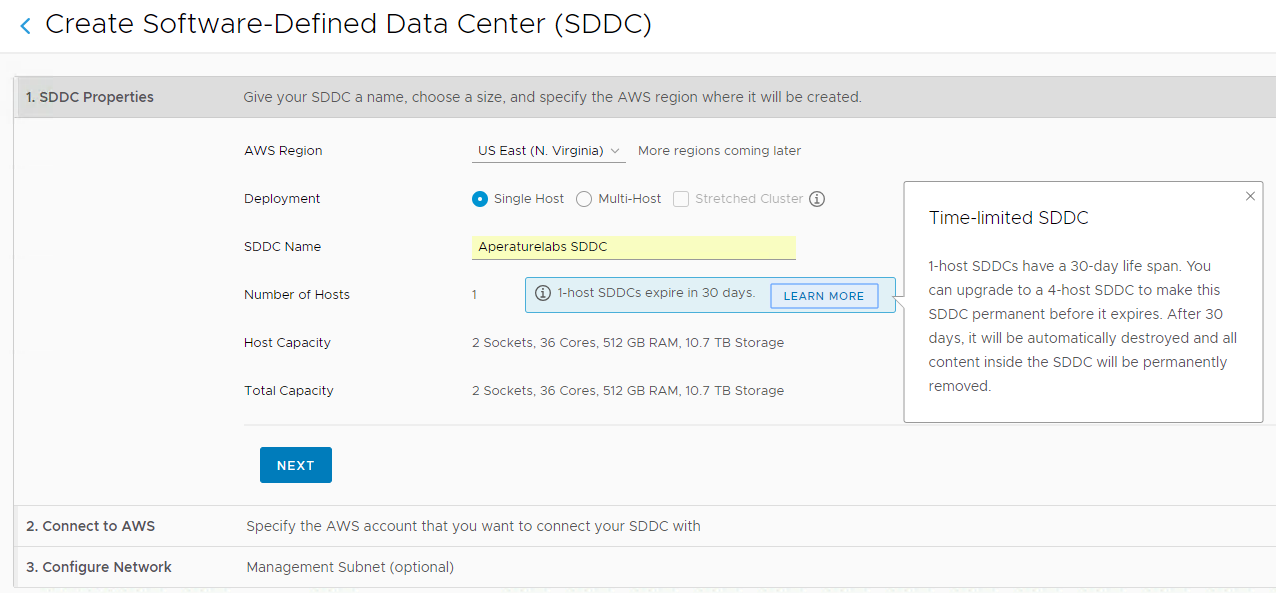
Yesterday I wrote about how to deploy a Single Host SDDC through the VMware Cloud on AWS web console. I mentioned some pre-requisites that where required in ...
While preparing for my VMworld session with Michael Cade on automating and orchestrating the deployment of Veeam into VMware Cloud on AWS, we have been testi...

It's never an issue with DNS! Even when DNS looks right...it's still DNS! I came across an issue today trying to upgrade a 6.5 VCSA to 6.7. The new VCSA appl...
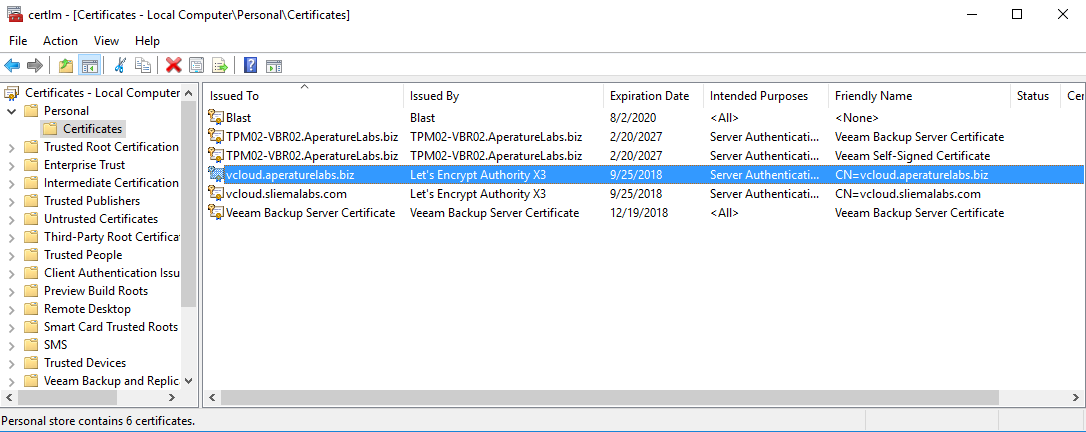
For the longest time the configuring of vCloud Director's SSL certificate keystore has been the thing that makes vCD admins shudder. There are lots of posts ...
There was a point release of vCloud Director 9.1 ( 9.1.0.1 Build 8825802 ) released last week, bringing with it an updated Java Runtime plus new API function...
VMworld 2018 is fast approaching and in the last 24 hours, notifications where sent out to those lucky enough to have their session submissions accepted. Hav...
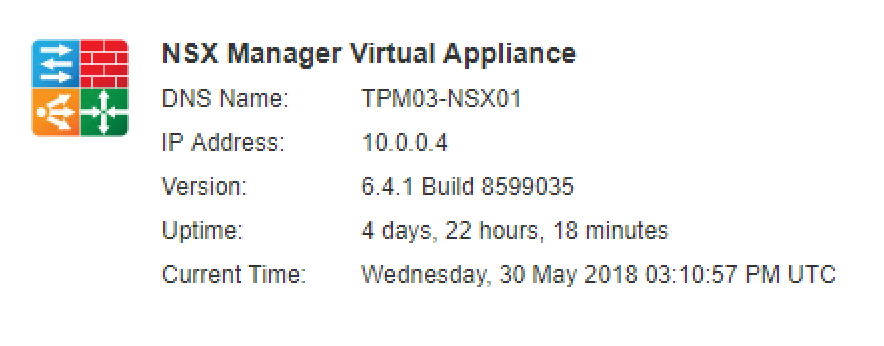
Last week VMware released NSX-v 6.4.1 ( Build 8599035 ) that contains a some new features and addresses a number of resolved issues from previous releases. I...
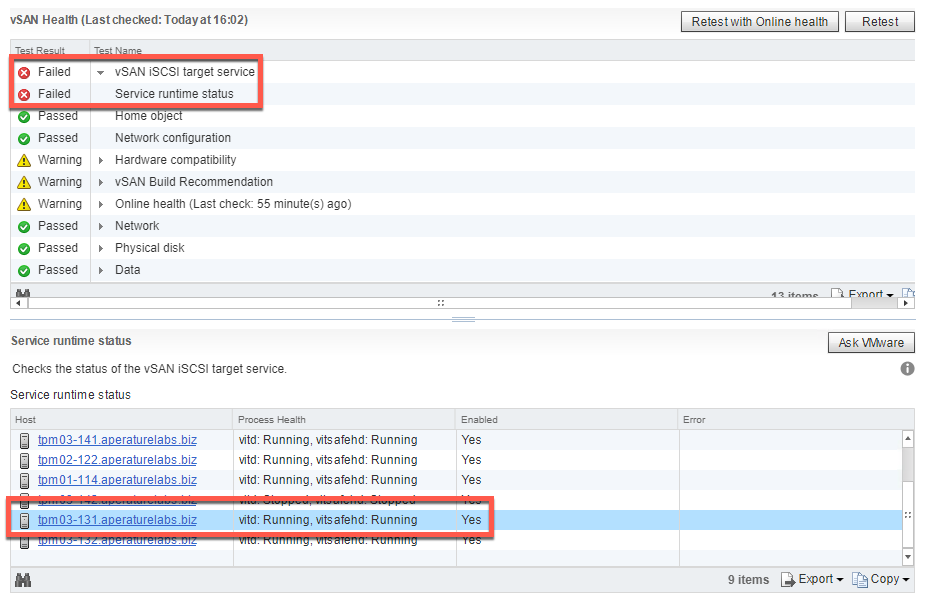
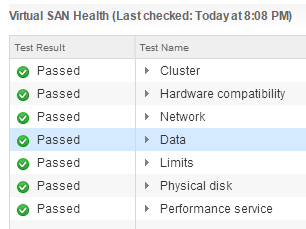
A few weeks ago I wrote about using iSCSI as a backup repository target . While still running this POC in my environment I came across an error in the vSAN H...

A few weeks ago after much anticipation VMware released vSphere 6.7 . Like 6.5 before it, this is a lot more than a point release and represents a major upgr...
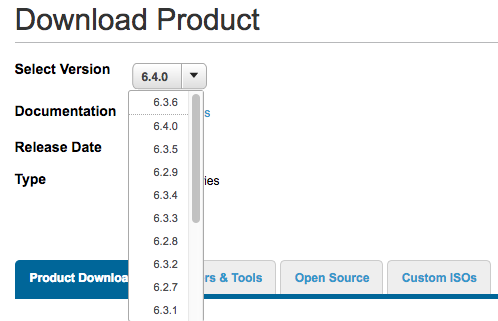
VMware has announced the general availability of vSAN 6.7 . As vSAN continues to grow, VMware are very buoyant about how it's performing in the market. With ...
Last week VMware released NSX-v 6.3.6 ( Build 8085122 ) that doesn't contain any new features but addresses a number of bug fixes from previous releases. Thi...
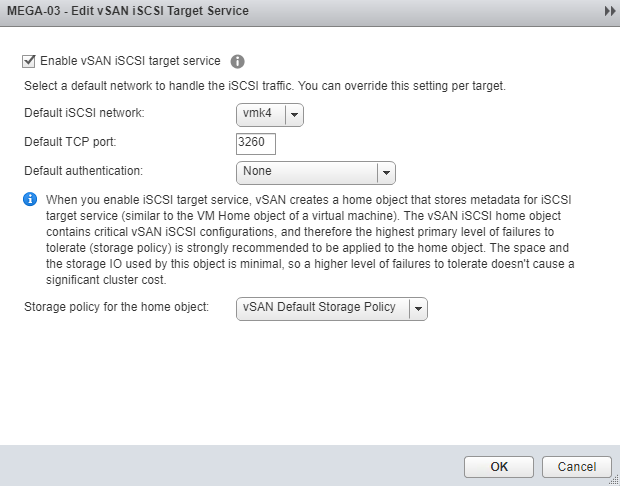
Probably one of the least talked about features of vSAN is it's ability to serve out iSCSI volumes. The feature was released with vSAN 6.5 and was primarily ...
After a longer than expected deliberation period the vExpert class of 2018 was announced late last Friday (US Time). I’ve been a vExpert since 2012 with 2018...
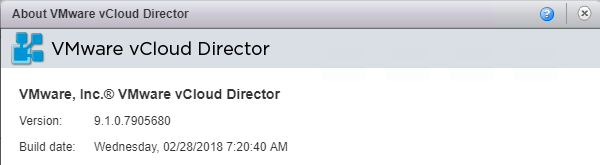
Overnight VMware released vCloud Director 9.1 ( build 7905680 ) which builds on the 9.0 release that came out last September. This continues to deliver on VM...

VMware has held it's first ever VMware Cloud Briefing today. This is an online, global event with an agenda featuring a keynote from Pat Gelsinger, new annou...

For a few years now i've been compiling features and throughput numbers for NSX Edge Services Gateways. This started off comparing features and performance m...
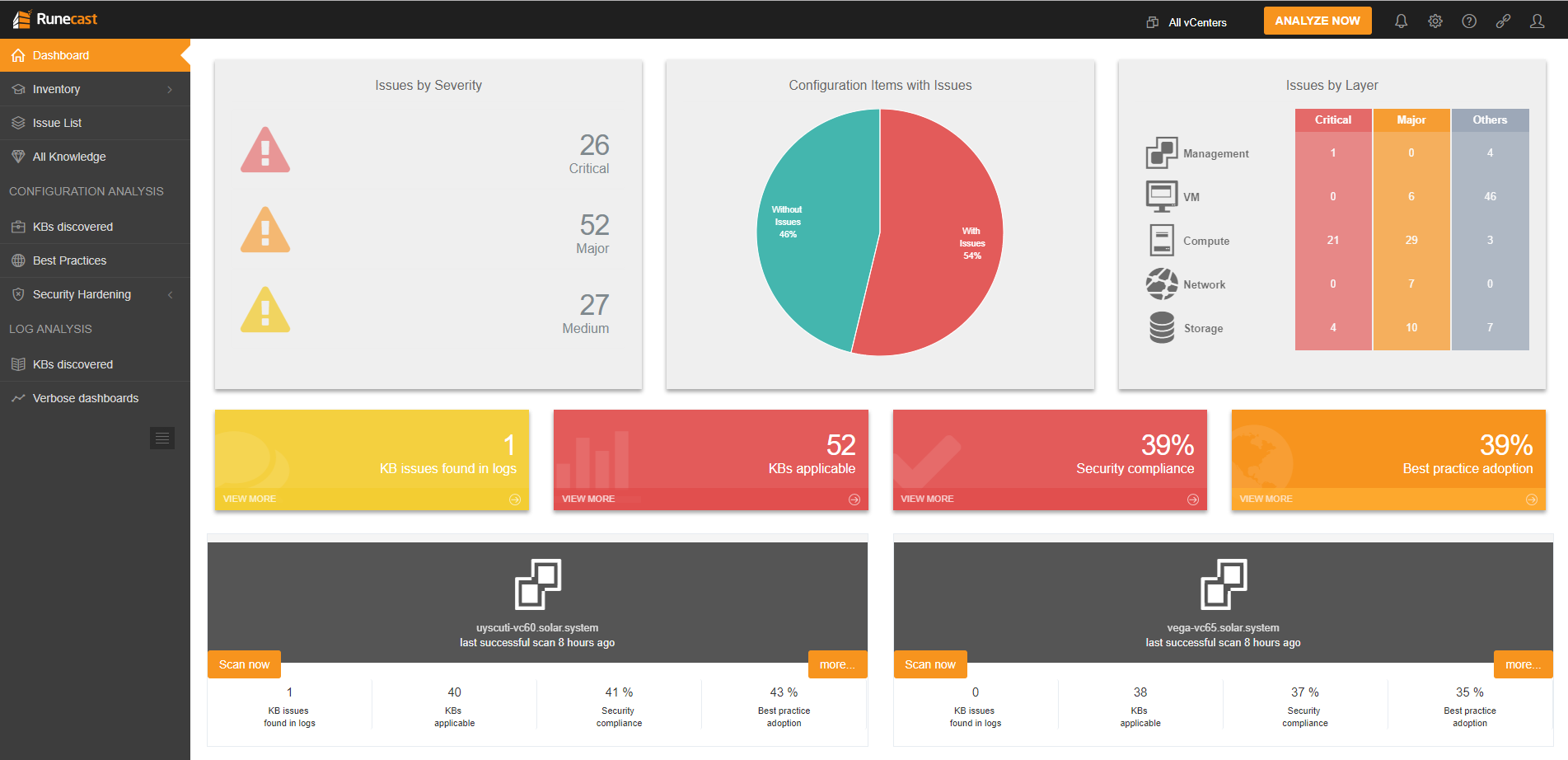
Runecast has released version 1.7 of their Analyzer today and it has added support for VMware vSAN. By using a number of resources within VMware’s knowledge ...
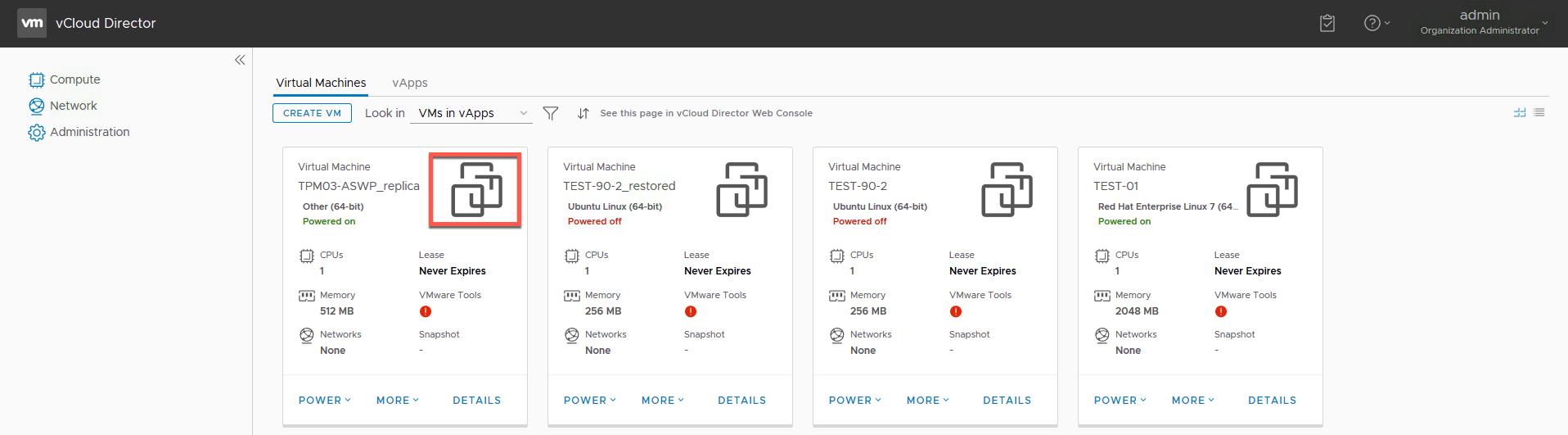
As most of you should know buy now, vCloud Director 9.0 features a new HTML5 Tenant UI Portal which is not only very pretty, but also functional. As of the 9...
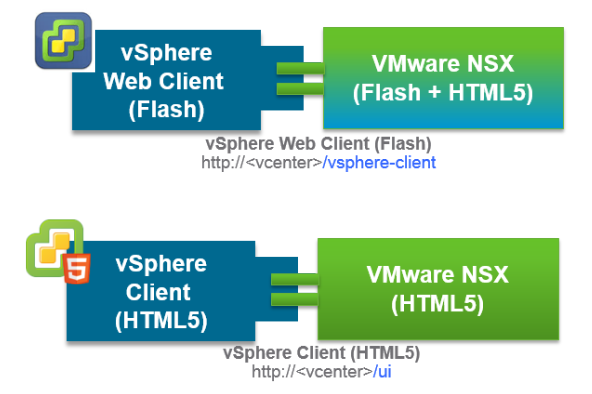
NSX-v 6.4 was released a couple of weeks ago and as I talked about in my launch post , there are a lot of new features and enhancements that make this releas...
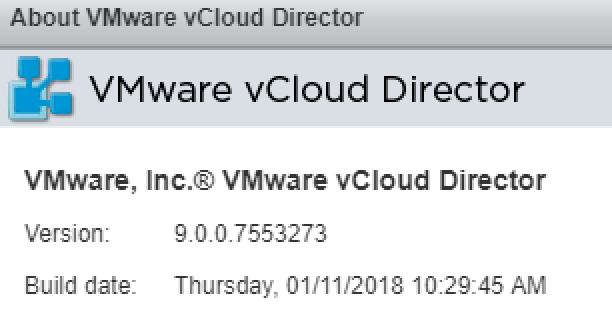
Last week VMware put out a new point release for vCloud Director 9.0 ( Build 7553273 ) for Service Providers. While there is nothing new in this release ther...
This week VMware released NSX-v 6.4.0 ( Build 7564187 ) and with it comes a new UI Plug-in for vSphere Client (HTML5) which includes some new dashboards incl...
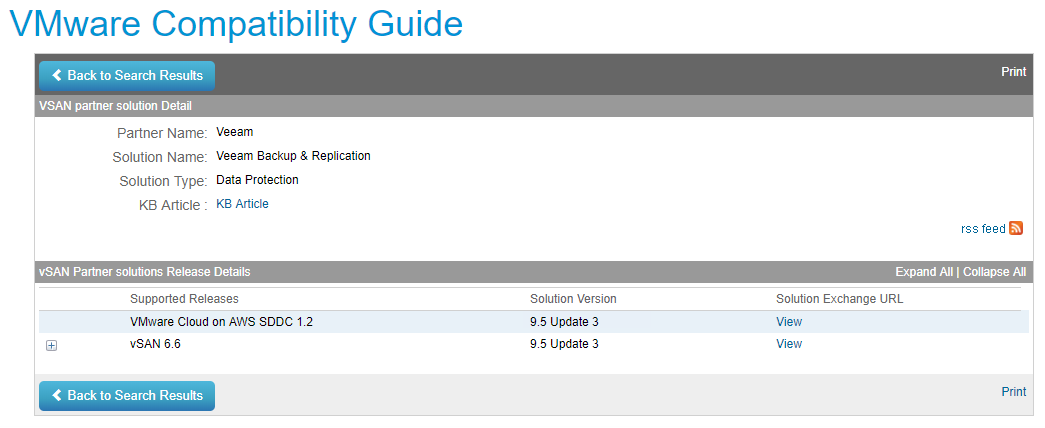
At VMworld 2017 Veeam was announced as one of only two foundation Data Protection partners for VMware Cloud on AWS. This functionality was dependant on the r...
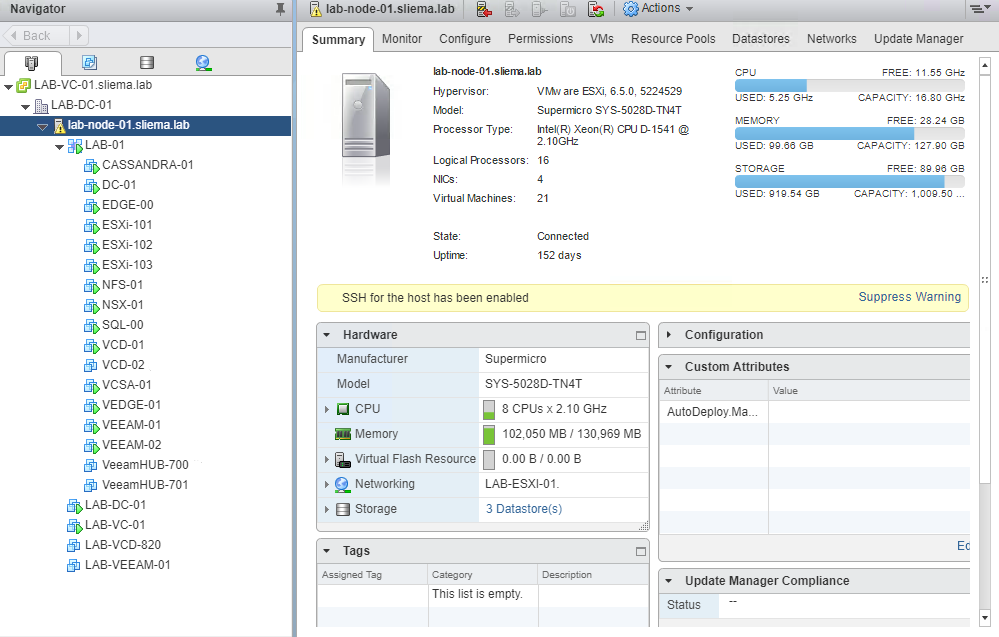
It's been just over a year since I unboxed my Supermicro 5028D-TNT4 and setup my new homelab. A year is a long time in computing so I though I would write up...
In Feburary of this year VMware released NSX-T 2.0 and with it came a variety of updates that looked to continue to push of NSX-T beyond that of NSX-v while ...

Today is the first day offical day of AWS re:Invent 2017 and things are kicking off with the global partner summit. Today also is my first day of AWS re:Inve...
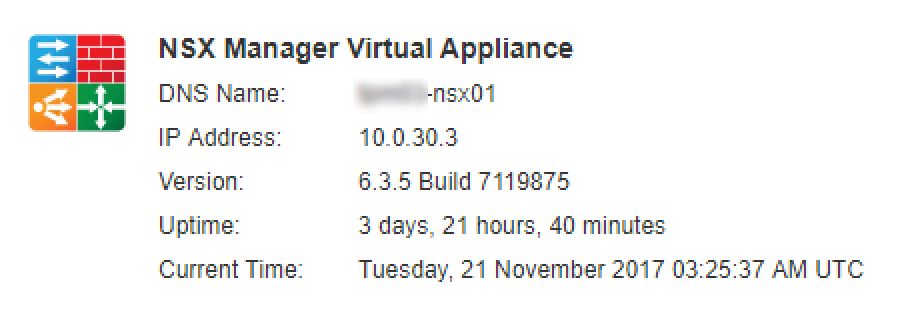
Last week VMware released NSX-v 6.3.5 ( Build 7119875 ) that contains a few new features and addresses a number of bug fixes from previous releases. Going th...
Last week Corey Romero announced the inaugural members of the vExpert Cloud sub-program . This is the third vExpert sub-program following the vSAN and NSX pr...

Last week VMware snuck out two point releases for vCloud Director 8.10 and 8.20. For those still running those versions you now have 8.10.1.1 ( Build 6878548...
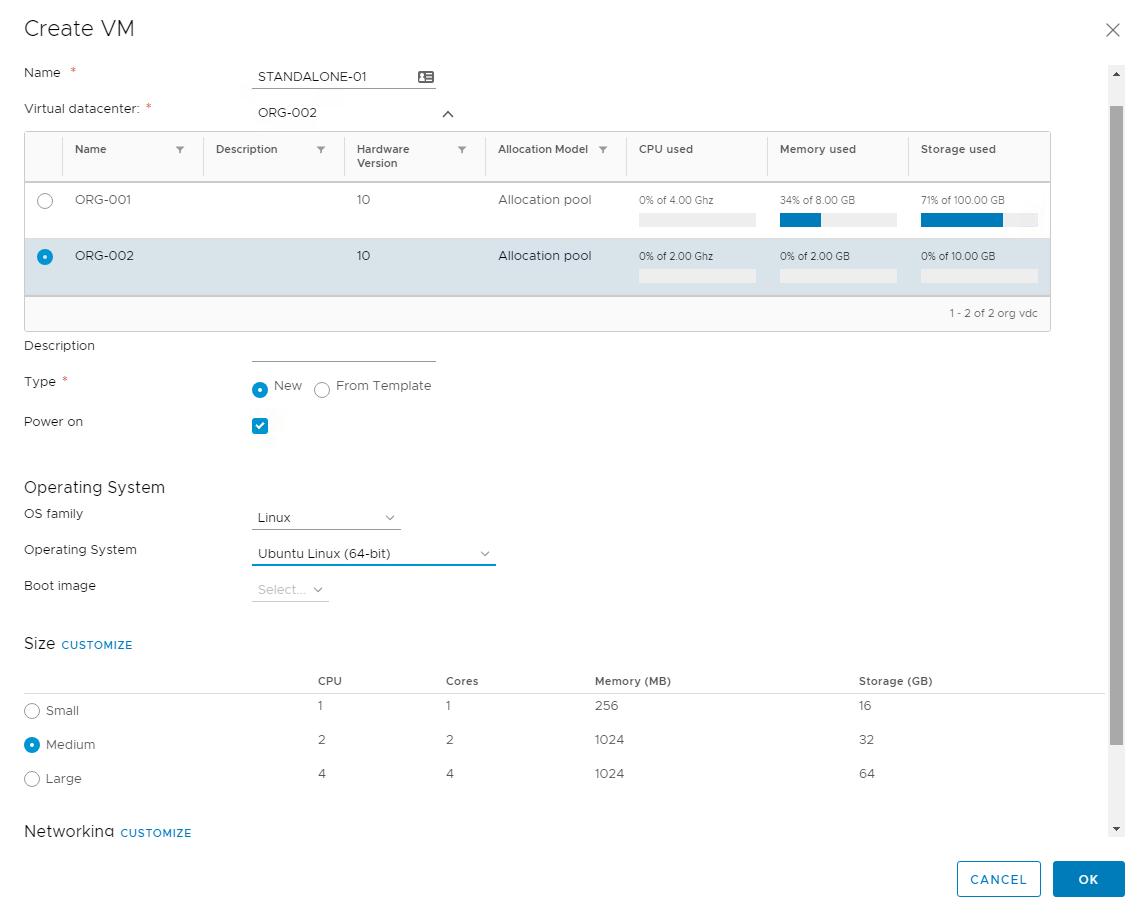
vCloud Director 9.0 was released late last month and brought with it a number of big new features and enhancements. If you are interested in a overview of wh...
Last week VMware released NSX-v 6.3.4 ( Build 6845891 ) that contains no specific new features but addresses a couple of bug fixes from previous releases. Go...
Last week I released a post on configuring Cassandra for vCloud Director 9.0 metrics . As a refresher, one of the cool features released in vCloud Director S...

One of the cool features released in vCloud Director SP 5.6.x was the ability to expose VM metrics that service providers could expose to their clients via a...
vCloud Director 9.0, released last week has a bunch of new enhancements and a lot of those are focused around it's integration with NSX. Tom Fojta has a what...
Today is a good day! VMware have released to GA vCloud Director 9.0 ( build 6681978 ) and with it come the most significant feature and enhancements of any p...

Over the past couple of months I noticed a trend in my top blog daily reporting...the Quick fix post on fixing a 503 Service Unavailable error was constantly...

Both VMworld US and Europe have come and gone in quick time this year and while I only attended VMworld US my team and other Veeam staff featured at Europe a...
Prior to VMworld there where rumours floating around that the vCloud Air Network was going to undergo a name change and sure enough at VMworld 2017 in the US...
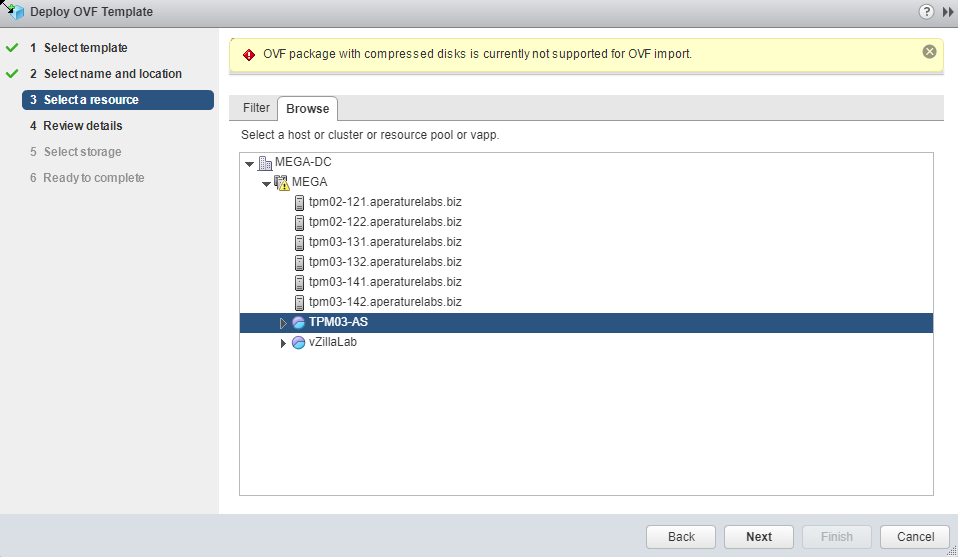
A couple of weeks ago I ran into an issue stopping me from importing an OVA and today I came across another issue relating to the Web Client not able to impo...
Last week at VMworld 2017 in the US, VMware announced the initial availability of VMware Cloud on AWS . It was the focal point for VMware at the event and pr...
It’s been exactly a year since VMware announced their partnership with AWS and it’s no surprise that at this year’s VMworld the solution is front and center ...

I'm sitting in the airport lounge waiting to board the first leg of my 26 hour journey to Las Vegas for VMworld 2017 and I thought it was no better time to w...
Last year saw a resurgence in vCloud related sessions at VMworld and the trend has continued this year at the 2017 event. Looking through the sessions at Par...

This time next week VMworld 2017 will be kicking off with the Sunday evening Welcome Reception among other sponsor and community events and for me, it will m...
Last week VMware released NSX-v 6.3.3 ( Build 6276725 ) and with it comes a new operating system for the NSX Controllers. Once upgraded the new controllers w...

It feels like this year moving along at ludicrous speed so it's no surprise that the Top vBlog for 2017 has been run and won. This year Eric Siebert changed ...

To say that #vGolf is back bigger and better than the inaugural #vGolf held last year at VMworld 2016 is an understatement! This year's event has been very p...
Late last week VMware released vSphere 6.5 Update 1 which included updated builds of both vCenter and ESXi and as per usual I will go through some of the key...
I originally came across the issue of slow storage performance with the native vmw_ahci driver that comes bundled with ESXi 6.5 just as I was first playing w...
I've been running my NestedESXi homelab for about eight months now but in all that time I had not installed or enabled the ESXi MAC Learning dvFilter . As a ...
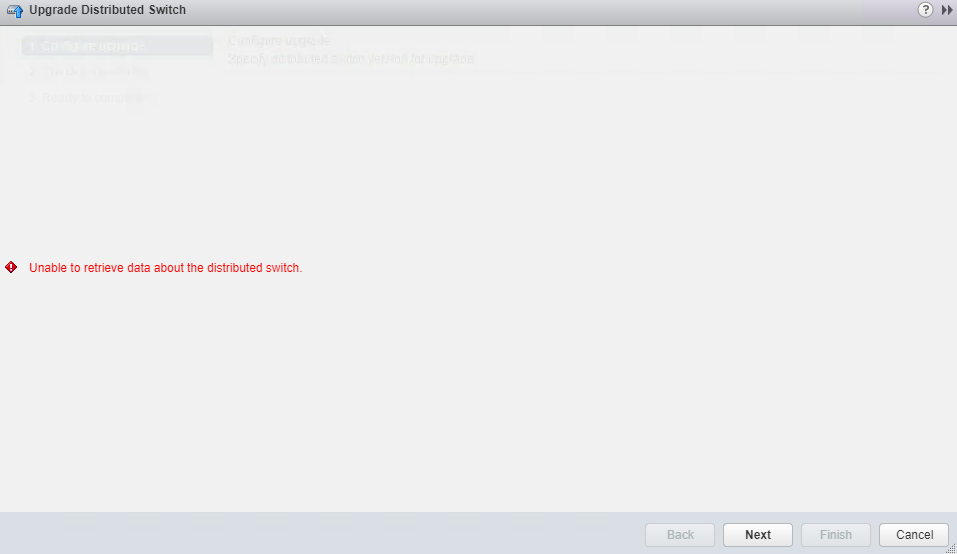
This week I upgraded (and migrated) my SliemaLabs NestedESXi vCenter from a Windows 6.0 server to a 6.5 VCSA ...everything went well, but ran into an issue w...

Over the past few years i've written a couple of articles on upgrading vCenter from 5.5 to 6.0. Firstly an in place upgrade of the 5.5 VCSA to 6.0 and then m...
Everything to do with VMworld this year feels like it's earlier than in previous years. The call for papers opened in Feburary with session voting happening ...

While I had resisted the temptation to put out a blog on this years Top vBlog voting I thought with the voting coming to an end it was worth giving it a shou...

Just after I joined Zettagrid in June of 2013 I decided to load up vSphere 5.1 Clustering Deepdive by Duncan Epping and Frank Denneman on my iPad to read on ...
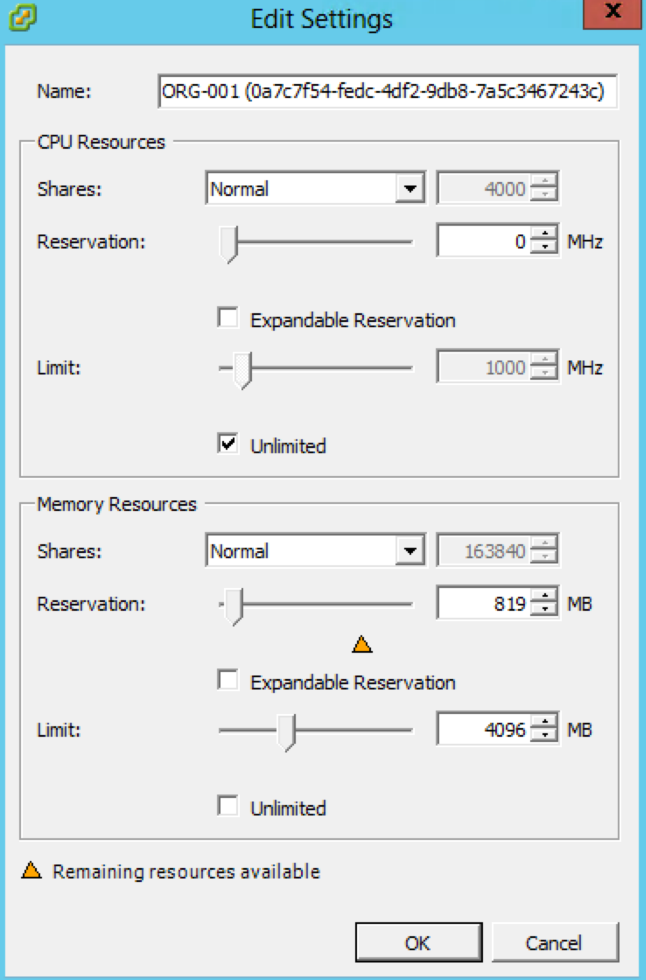
For the longest time all VMware administrators have been told that resource pools are not folders and that they should only be used under circumstances where...

[ Please head to this page for updated information ] #vGolf is back! Bigger and better than the inaugural #vGolf held last year at VMworld 2016! Last year we...

Last week VMware released a new patch ( ESXi 6.0 Build 5572656 ) that addresses a number of serious bugs with Snapshot operations. Usually I wouldn't blog ab...
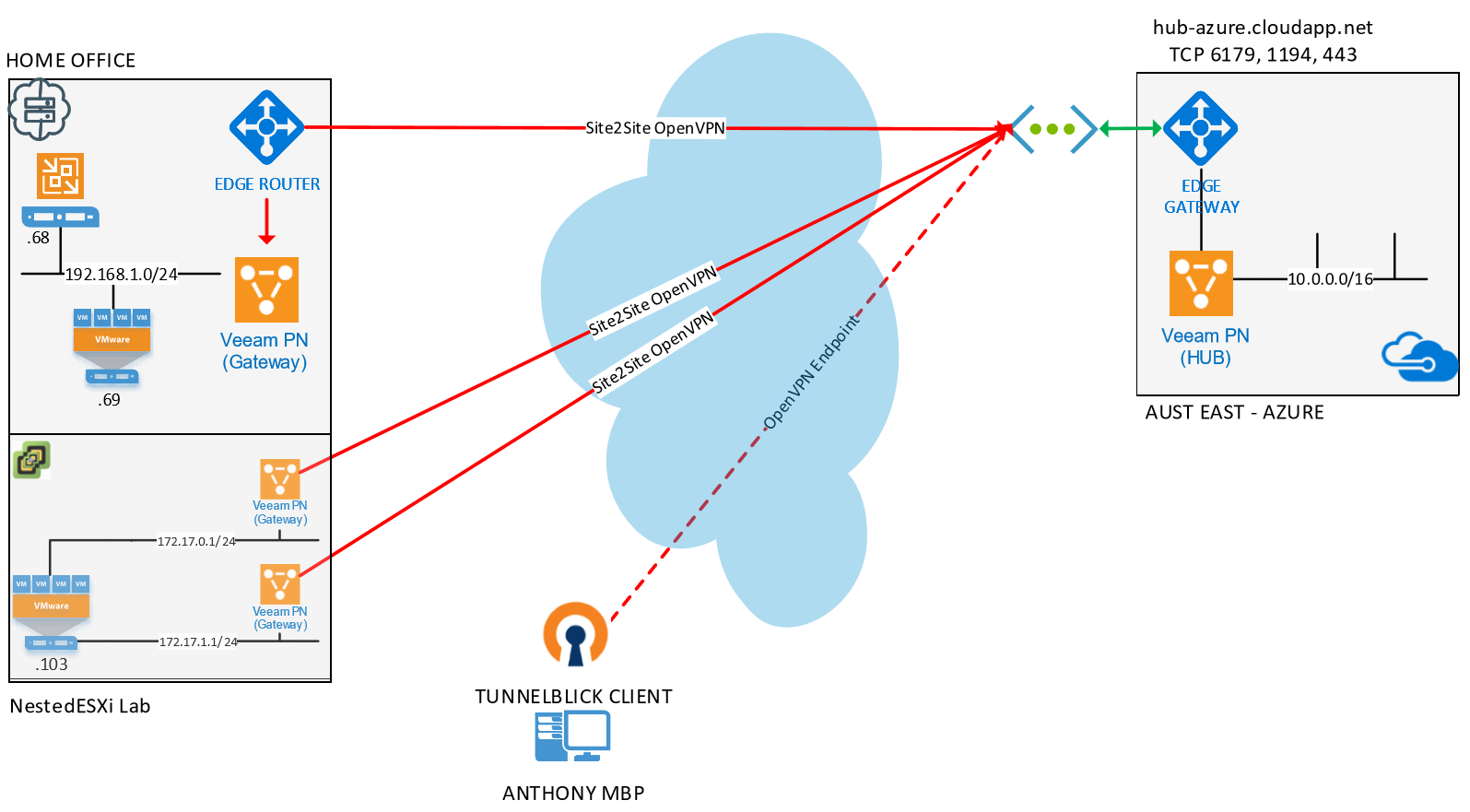
A couple of weeks ago at VeeamON we announced the RC of Veeam PN which is a lightweight SDN appliance that has been released for free . While the main messag...
VMware has had their Lab Flings program going for a number of years now and in 2015 I wrote this post listing out my Top 5 Flings . Since then there have bee...

Last February when VMware released VSAN 6.2 I stated that " Things had gotten Interesting " with regards to the 6.2 release of vSAN finally marking it's arri...
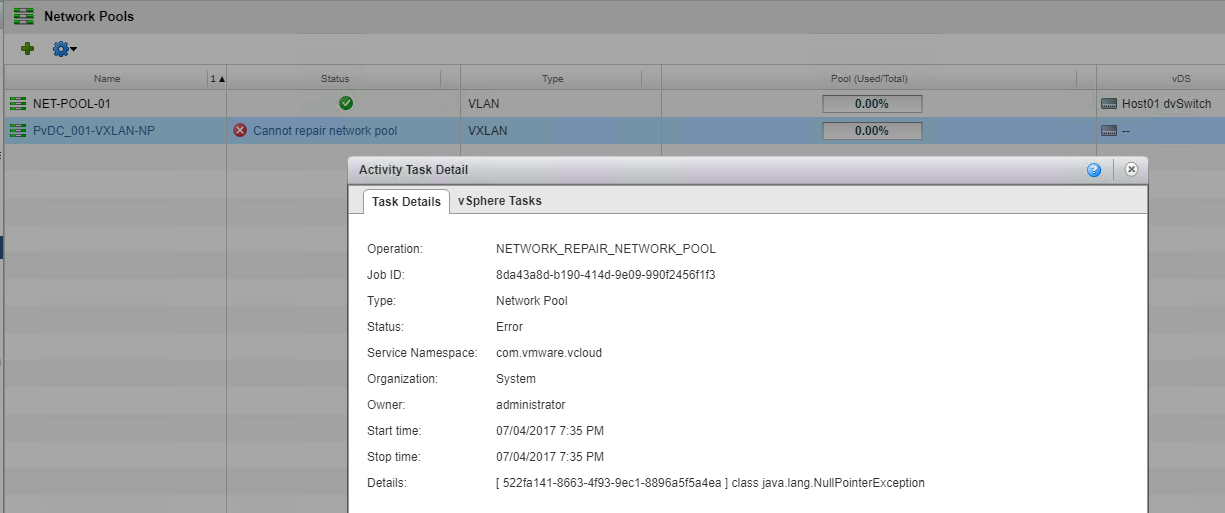
It seems that with the announcement last week that VMware was offloading vCloud Air to OVH people where again asking what is happening with vCloud Director.....

I've just spent the last fifteen minutes looking back through all my posts on vCloud Air over the last four or five years and given yesterday's announcement ...
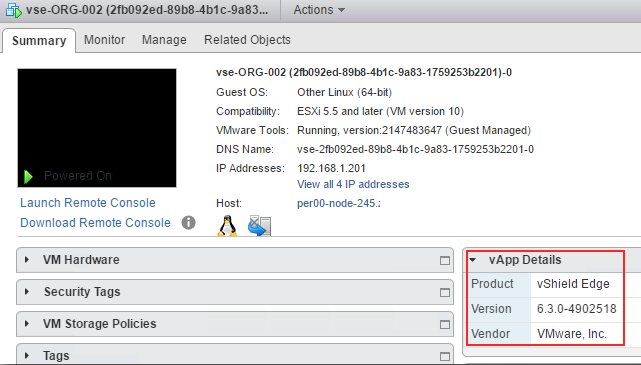
Many, including myself thought that the day would never come where we would be talking about a new UI for vCloud Director...but a a month on from the 8.20 re...

Well this has crept up on us quickly this year! It's time to vote for the VMworld Sessions that will be part of the US and Europe VMworld's held later in the...

Last week I attended the Sydney and Melbourne VMUG UserCons and apart from sitting in on some great sessions I came away from both events with a renewed sens...

[ NOTE ] : I decided to republish this post with a new heading and skip right to the meat of the issue as I've had a lot of people reach out saying that the ...

Last year I claimed that the Melbourne VMUG Usercon was the “Best Virtualisation Event Outside of VMworld!” …that was a big statement if ever there was one h...
vCloud Director SP 8.20 was released a few weeks ago and I wanted to highlight an issue I ran into while testing of the BETA. I hadn't come across this issue...
Last month I wrote a blog post on upgrading vCenter 5.5 to 6.0 Update 2 and during the course of writing that blog post I conducted a survey on which version...
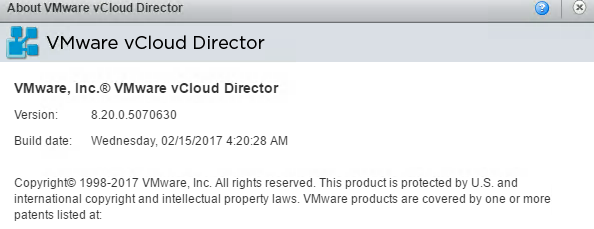
This week, VMware released vCloud Director SP version 8.20 ( build 5070630 ) which marks the 8th Major Release for vCloud Director since 1.0 was released in ...
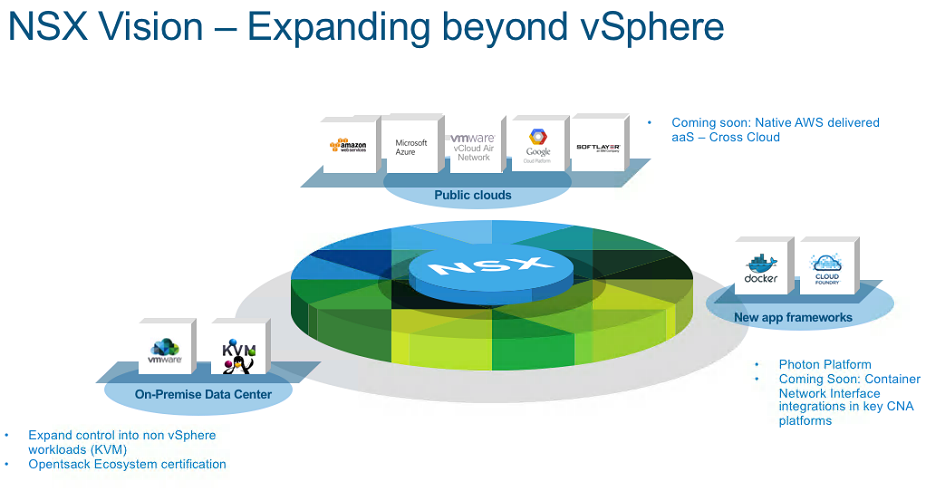
A couple of months ago in my NSX-v 6.3 and NSX-T 1.1 release post I focused around NSX-v features as that has become the mainstream version that most people ...
Overnight Cory Romero announced the intake of the 2017 VMware vExperts . As a now six time returning vExpert it would be easy for me to sit back enjoy a perc...
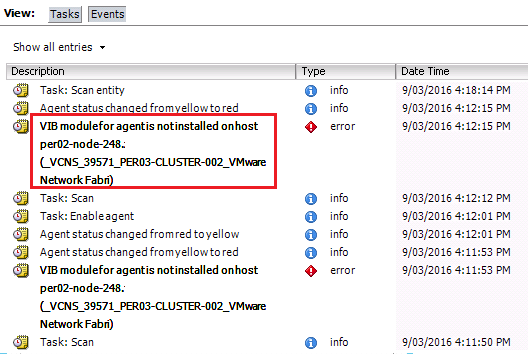
NSX-v 6.3 was released last week with an impressive list of new enhancements and I wasted no time in looking to upgrades my NestedESXi lab instance from 6.2....
VMware's NSX has been in the wild for almost three years and while the initial adoption was slow, of recent times there has been a calculated push to make NS...
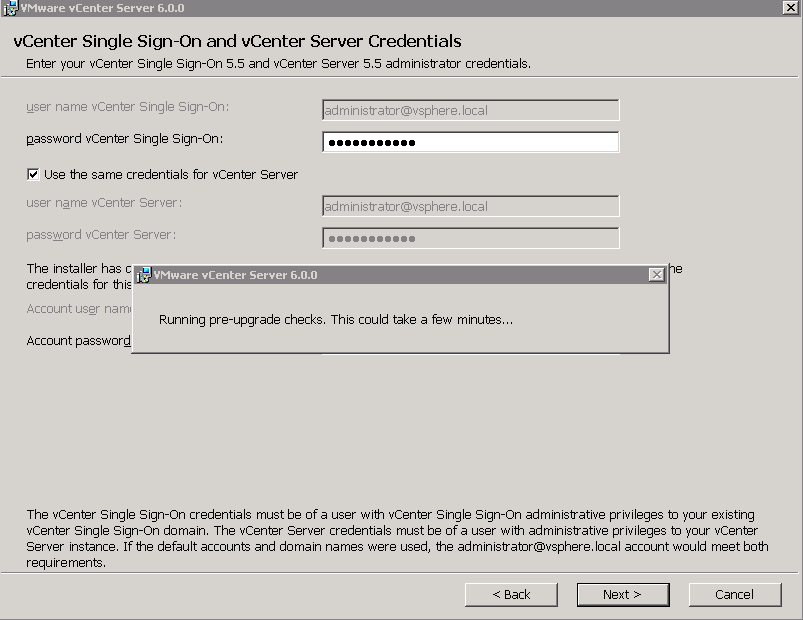
Yes that's not a typo...this post is focusing on upgrading Windows vCenter 5.5 to 6.0 via an in-place upgrade. There is the option to use the vSphere 6.0 Upd...

Welcome to 2017! To kick off the year I thought I'd do a quick post on a little known product (at least in my circles) from Red Hat Inc called ManageIQ . I s...
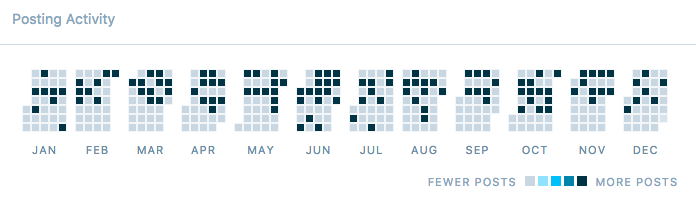
2016 is pretty much done and dusted and it's been an good year for Virtualization is Life! There was a more modest 70% increase in site visits this year comp...
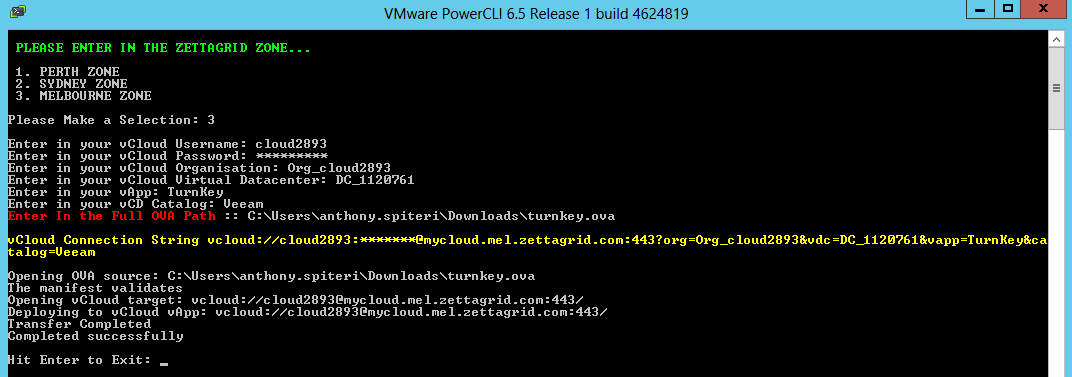
Earlier this year I put together a quick and nasty PowerShell Script that exports a vApp from vCloud Director using the OVFTool ...for those that don't know ...
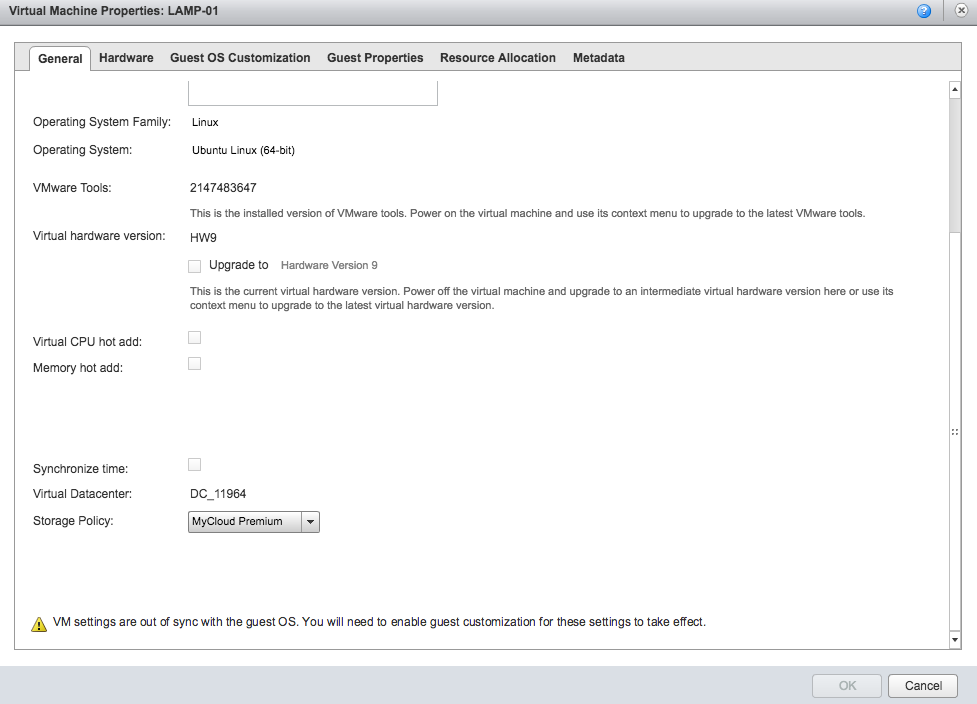
Last week VMware released vCloud Director SP 8.10.1 Build 4655197 and while it was mainly a patch release there was one new feature added which was a couple ...
This week VMware released vCloud Director SP 8.10.1 Build 4655197 . This is the sister build for vCD SP 8.0.2 and like that release, while there a a number o...
While I was at Zettagrid I was lucky enough to have access to a couple of lab environments that where sourced from retired production components and I was ab...
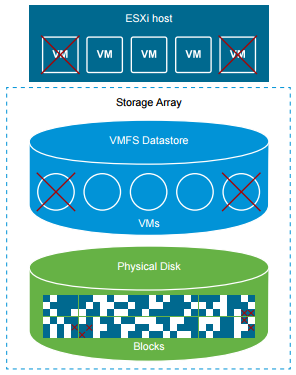
One of the cool newly enabled features of vSphere 6.5 is the come back of VMFS storage space reclamation. This feature was enabled in a manual way for VMFS5 ...

Last week after an extended period of development and beta testing VMware released vSphere 6.5. This is a lot more than a point release and is a major major ...
A couple of weeks ago Veeam released the RTM Build of Backup & Replication 9.5 to it's Cloud and Service Provider partners. This was to ensure that any keen ...
Ok, i'll admit it...i've had serious lab withdrawals since having to give up the awesome Zettagrid Labs. Having a lab to tinker with goes hand in hand with b...

Last week I was in Sydney for the 2016 edition of vForumAU ...I've been coming to vForumAU since 2011 and this years event was probably up there with the bes...

About four years ago I was invited to join a program called the VMware vChampions...this program is run and operated by the VMware ANZ Channel and Marketing ...
With vForumAU 2016 less than a week away it's time to talk about what the vBrownBag crew will be up to next week in Sydney. If you don't know what the vBrown...

vForumAU is just over a week away and for those that are in Sydney for the event and are around a day earlier should cancel any existing plans and attend VMD...
It seems that all with all the announcements of late around VMware's (re)shifting Hybrid Cloud strategy with Cross Cloud Foundation and VMware's partnership ...
[ UPDATE ] In light of this post being quoted on The Register I wanted to clarify a couple of things. First off, as mentioned t here is a fix for this issue ...

Last week VMware and Amazon Web Services officially announced their new joint venture whereby VMware technology will be available to run as a service on AWS ...
Last week VMware and Amazon Web Services officially announced their new joint venture whereby VMware technology will be available to run as a service on AWS ...
Last week VMware released vCloud Director SP 8.0.2 Build 4348775 . While there a a number of minor bug fixes in this release there is one important fix that ...
A question came up today around throughput numbers for an NSX Edge Services Gateway and that jogged my memory back to a previous blog post where I compared f...

VMworld Europe is a little over a week away and while I won't be attending the even in Barcelona in looking through the session catalog for Partner Exchange ...

Last year Arkin burst onto the scene offering a solution that focused on virtual and physical deep network analytics. Arkin was recognised at VMworld 2015 by...
There is a lot of talk going around how IT Pros can more efficiently operate and consume Cloud Based Services…AWS has lead the way in offering a rich set of ...
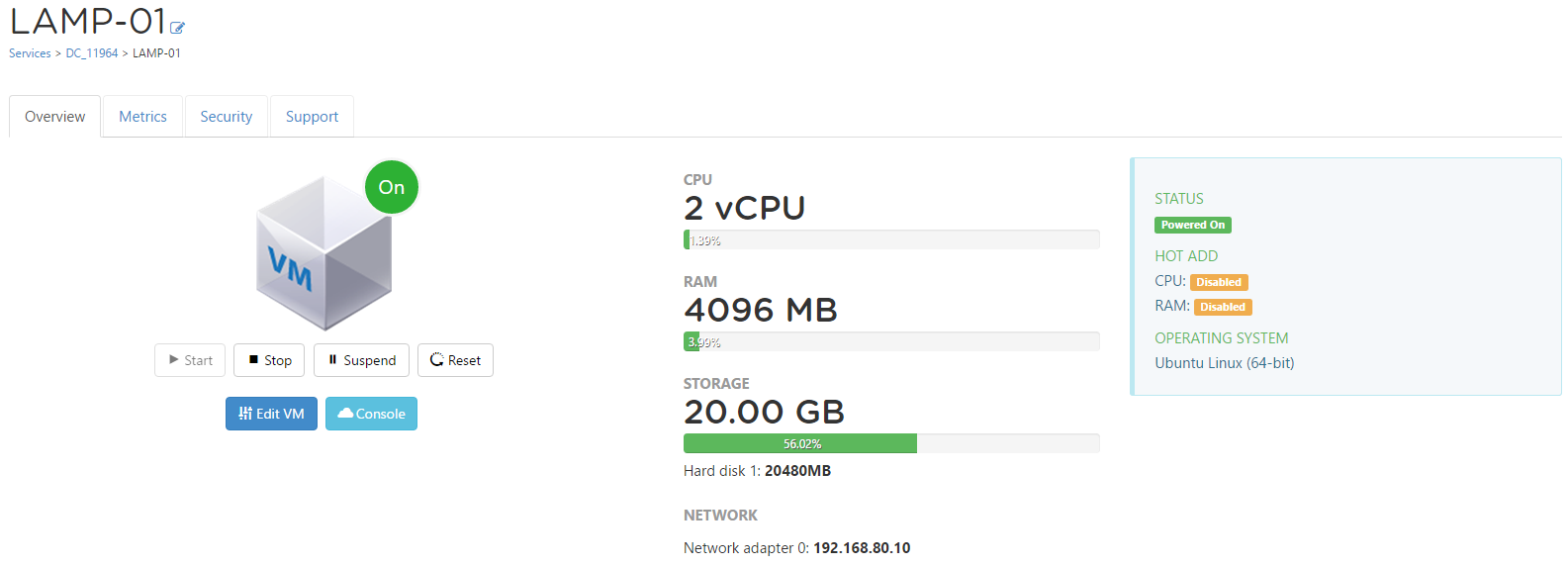
Earlier this week my good friend Matt Crape sent out a Tweet lamenting the fact that he was having issues uploading media to WordPress...shortly after that t...
Over the weekend I was tasked with the recovery of a #NestedESXi lab that had vCloud Director and NSX-v components as part of the lab platform. Rather than b...
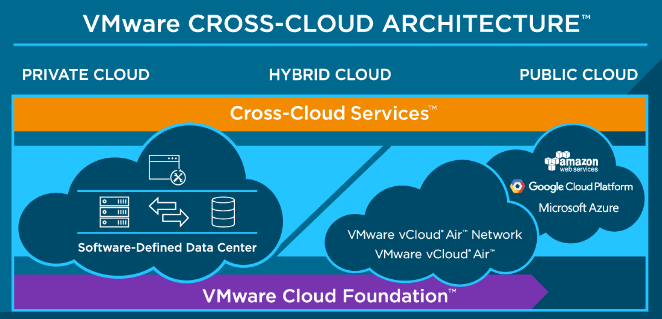
I’ve been sitting on this topic since the VMworld 2016 US Keynote where VMware announced the Cross Cloud Architecture. I posted some raw thoughts the day aft...
CloudPhysics have been a little quiet over the past twelve or so months with focus shifting from presenting data via Cards to Dashboards and also focusing on...
NSX-v 6.2.4 was released the week before VMworld US so might have gotten somewhat lost in the VMworld noise...For those that where fortunate enough to not up...

VMworld 2016 US is done and dusted and for those that didn't attend or attended but missed out on sessions due to "scheduling conflicts", VMware has been awe...

I'm still trying to process the VMworld 2016 Day 1 Keynote in my mind...trying to make sense of the mixed messages that myself and others took away from the ...

[UPDATE] - WE HAVE REACHED CAPACITY - APOLOGIES TO THOSE THAT MISSED OUT With VMworld now a week away, I am pleased to announce that #vGolf 2016 has a venue ...

This week the VMware vExpert team officially lifted the lid on two new subprograms that focus on NSX and VSAN . The announcements signal a positive move for ...
VMworld 2016 is just around the corner (10 days and counting) and the theme this year is be_Tomorrow …which looks to build on the Ready for Any and Brave IT ...

Rubrik have today announced an expansion to their existing Converged Data Management Backup Appliances adding Cloud Data Management that leverages Rubrik's d...
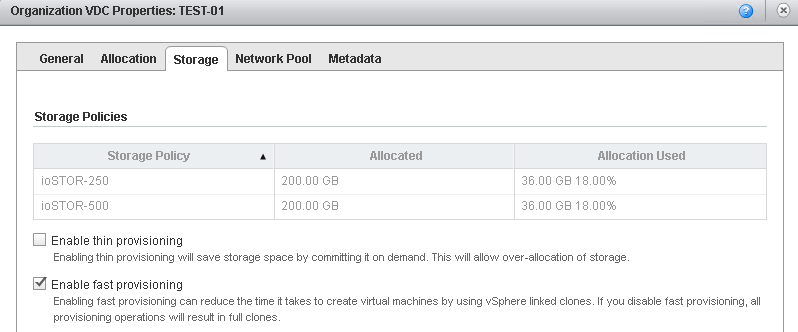
vCloud Director SP 8.10 has been out for a couple months now and the general buzz around this release has been extremely positive. The decision to expose the...
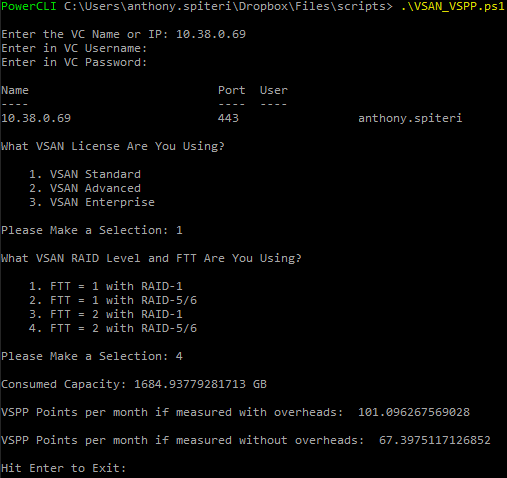
There is no doubt that new pricing introduced to vCAN Service Providers announced just after VSAN 6.2 was released meant that Service Providers looking at VS...

[ UPDATE ] This issue is resolved in VMware ESXi 6.0, Patch Release ESXi600-201608001. For more information, see VMware ESXi 6.0, Patch Release ESXi600-20160...

VMworld is a little over three weeks away and from the looking through the sessions at Partner Exchange and VMworld proper the refocus on the vCloud Air Netw...
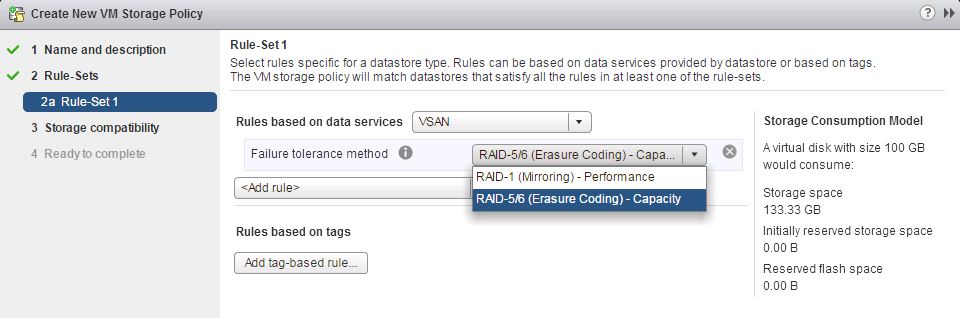
When VSAN 6.2 was released earlier this year it came with new and enhanced features and with the price of SSDs continuing to fall and an expanding HCL it see...
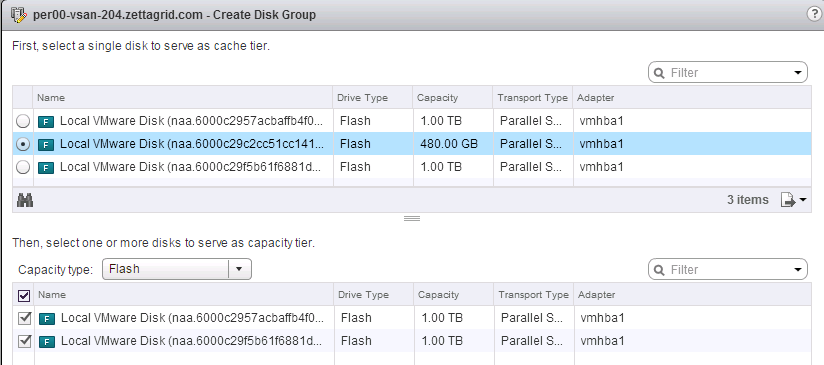
When VSAN 6.2 was released earlier this year it came with new and enhanced features and with the price of SSDs continuing to fall and an expanding HCL it see...
When VSAN 6.2 was released earlier this year it came with new and enhanced features and depending on what version you where running you might not have been a...
Last month Veeam announced that they had significantly enhanced the capabilities around the backup and recovery of vCloud Director . This will give vCloud Ai...
This week one of our Vitualisation Engineer's ( James Smith ) was trying to come up with a solution for a client that wanted the flexibility to bring in his ...
vCloud Director SP 8.10 has been out for about a month now and the general buzz around this release has been extremely positive. The decision to expose the p...
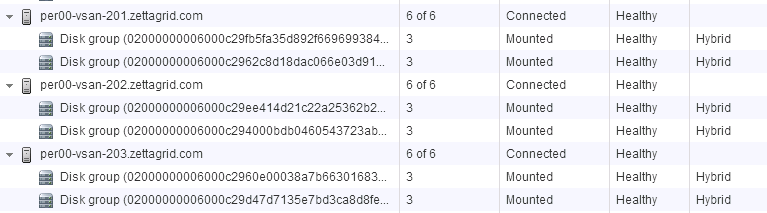
A month or so ago I had one of our VSAN Management Clusters Health Status flag that there was a failed disk in one of the hosts disk groups. VSAN worked quic...
A while ago VMware announced that NSX-v general support would come to an end on this October to pave the way for current 6.1.x users to upgrade to 6.2.x. A p...
NSX-v 6.2.3 has been out for a couple of weeks now and besides the new features and bug fixes there was a significant change to the licensing structure for N...

[ UPDATE ] - VMware have released an official KB for the CBT issue. Sadly if you recognize the title of this post it's because this isn't the first time I've...
Veeam have only announced two features of their upcoming v9.5 release of Backup & Replication but it's exciting to announce that they have chosen to release ...

PernixData has released version 3.5 of their FVP acceleration platform as well as version 1.1 of their Architect storage intelligence platform. Compared to p...

Last week VMware released NSX-v 6.2.3 Build 3979471 and it's anything but your standard point release. Running through the list off the release notes this co...
I generally don’t post around security releases but after going through the notes on CVE-2016-2079 I thought it was important enough to dedicate a post aroun...
Veeam don't just do awesome Backup & Replication software ...they also have, what I think is a highly underrated operations and management and capacity plann...

A couple of days ago an email dropped into my inbox from VMware titled " Important Notice About Your VMware vCloud Air OnDemand Account " My first thought wa...
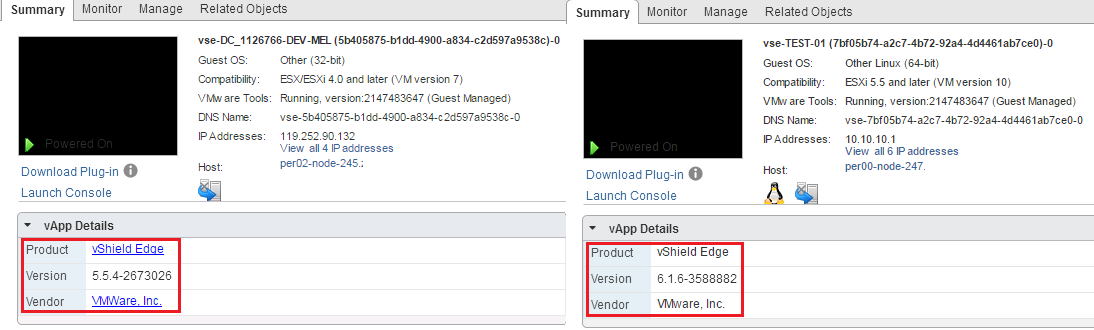
As mentioned last week VMware released vCloud Director SP 8.10 and with it a list of significant new features and improvements. In this series I'll go throug...

This is a quick post to alert Veeam users to an issue that was raised in the Veeam Community Forums yesterday...firstly if you are a Veeam customer and are n...
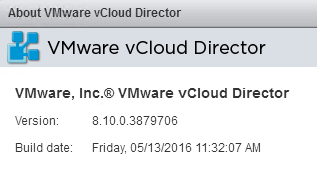
Earlier this morning VMware released vCloud Director SP 8.10 Build 3879706 . This is a significant release for vCloud Director as its the first release that ...
Log Insight is one of those great VMware products that needs to get more airplay as it has quiet a few applications other than a run of the mill log parser.....
While I have resisted temptation to post a blog on this years Top vBlog voting I thought with a couple of days to go it was worth giving it a shout just in c...
Last week I posted a tweet saying "Friends don't let friends delete the NSX-v VTEP PortGroup" and as most of us do in our industry we learn by doing and I fo...
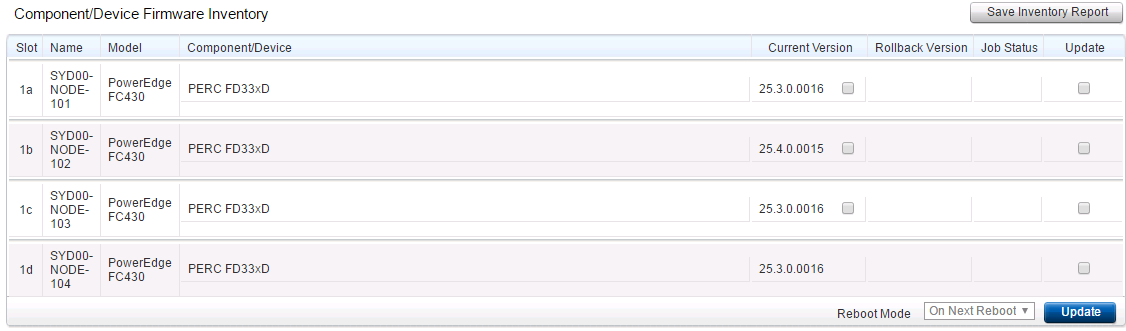
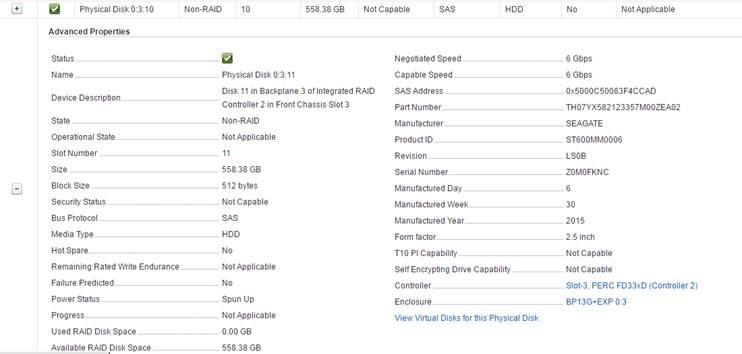
I wanted to cover off a couple of important updates in this post relating to the DELL PERC storage controller Firmware and software drivers as well as an imp...

Well this has crept up on us quickly this year! It's time to vote for the VMworld Sessions that will be part of the US and Europe VMworld's held later in the...

Overnight there was a couple of NSX related events that took place...one was expected and one not so much. I have known about the next release of NSX code na...

As many of us rejoiced at the release of VSAN 6.2 that came with vSphere 6 Update 2...those of us running DELL PERC based storage controllers where quickly w...

There has been some discussion in the vExpert Slack channel over the last couple of days discussing how the vExpert Program which is an advocacy program that...

EDIT 2pm AWST : Seems as though the link and announcement has been pulled so take with a grain of salt until it's confirmed or otherwise. EDIT 3:15pm ASWT : ...

Over the past week there have been a number of posts around the new vSphere Beta which is the first step in testing the next major release from VMware follow...
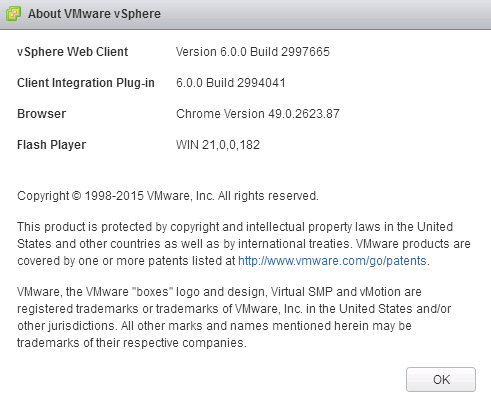
Last week VMware released advisory VMSA-2016-0004 for a critical security issue found in the Client Integration Plugin which is found in versions of vCenter,...
Last week I sat and passed the VCIX-NV ( VCXN610 ) exam and I thought I would follow-up last weeks Review Post with some interesting...well I think interesti...

What a effort that was! Today I sat and passed the VCIX-NV ( VCXN610 ) exam and I can say that this exam has taken a fair bit out of me over the last month o...
For a while now we have known that vCloud Networking and Security's days where numbered ...with the release of NSX as a replacement+ product it had been comm...
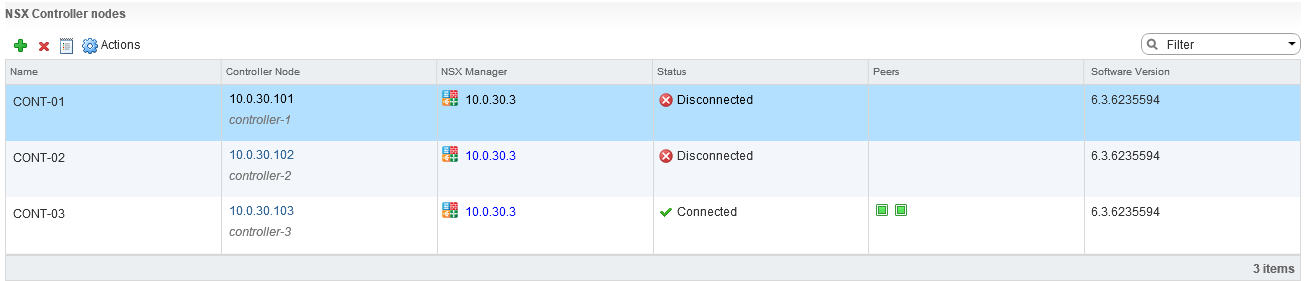
With NSX becoming more and more widely available there are more NSX home labs being stood up and with that the chances of the NSX Controllers failing due to ...
It's been just over a week since VMware released vSphere 6 Update 2 and I thought I would go through some of the key features and fixes that are included in ...
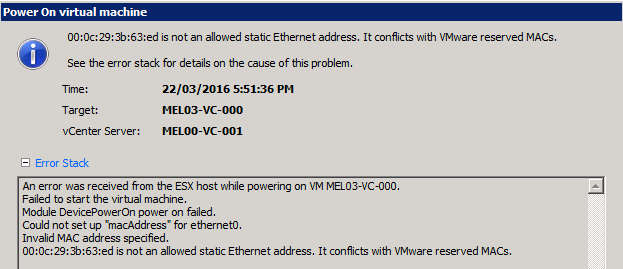
The old changing of the MAC address causing NIC/IP issues has raised it's ugly head again...this time during a planned migration of one of our VCSA from one ...

Late last year CloudPhysics released their VM Exploration mode feature which allowed for a detailed look into what was happening holistically to a VM with th...
Somewhat hidden among the major releases that came our from VMware HQ yesterday was a point release for vCloud Director SP 8.x. This takes the vCD SP Build t...
Who said big corporations don't listen to their clients! VMware have come to the party in a huge way with the release of VSAN 6.2...and not only from a techn...
I've had this situation happen a couple of times in production where NSX Host Preparation Install or Upgrade seems to hang forever without timing out and spi...
Last week VMware released version 6.2.2 of NSX-v. The 6.2.2 release is mainly aimed at patching a security hole in the glibc libraries as well as removing a ...
I've been using the VCSA for a couple of years now since the release of vSphere 5.5 and have been happily using the upgraded 6.0 version for a couple of my e...
VMware is at an interesting place at this point in time...there is still no doubting that ESXi and vCenter are the market leaders in terms of Hypervisor Plat...

"Best Virtualisation Event Outside of VMworld!" ...now there is a big statement if ever there was one! Without insulting every other VMUG UserCon around the ...
Last Friday Cory Romero announced the first intake of the 2016 VMware vExperts . As a five time returning vExpert it would be easy for me to sit back enjoy a...
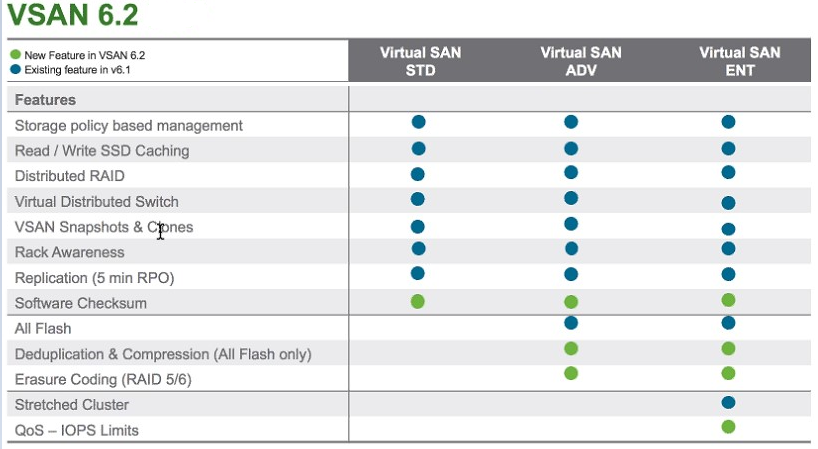
There is a saying in our industry that Microsoft always get their products right on the third attempt...and while this has been less and less the case of lat...

Continuing on from post earlier on the week on the release of the new Learning VMware NSX Book by Ranjit Singh and reviewed by myself @jfrappier ...the guys ...
Why Veeam's software-driven, hardware agnostic approach makes sense for backups https://www.youtube.com/watch?v=hDBlTdzE6Us&t=8s Late last year I attended a ...
CloudPhysics are still quietly working away in the background continuing to improve their analytics service...and apart from recently announcing record resul...
Well…the news isn’t great filtering out over the internets about the VMware Job Cuts and the apparent clipping of vCloud Air's wings. While this is yet to be...
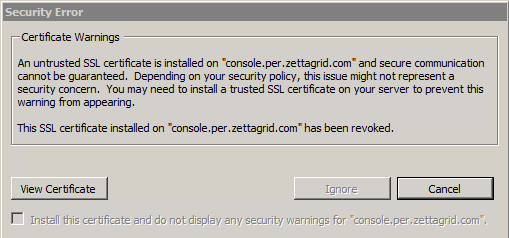
Certificates and VMware don't go together like a horse and carriage ... And while I've never really had a major issue with SSL certs in VMware mainly because...
For the last couple of weeks we have had some intermittent issues where by ESXi network adapters have gone into a disconnected state requiring a host reboot ...
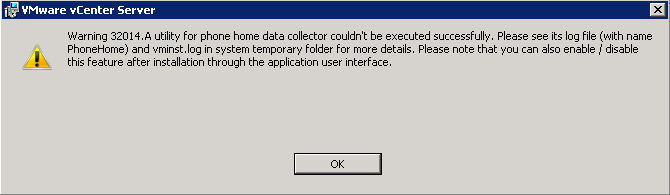
This week I've been upgrading vCenter in a couple of our labs and came across this issue during and after the upgrade of vCenter from 5.5 Update 2 to 5.5 Upd...
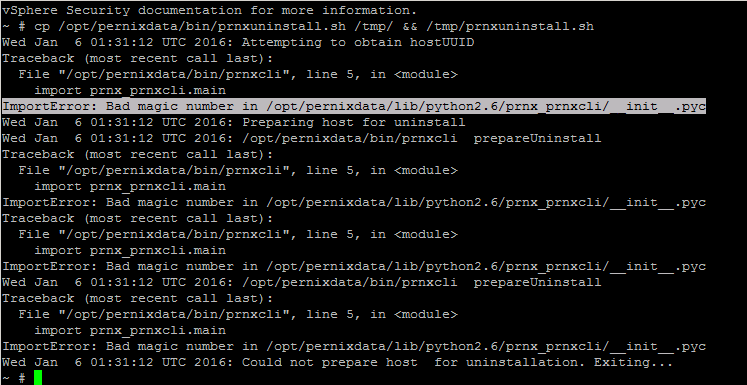
Came across an issue this morning trying to remove old 2.0 PernixData FVP Host Extensions from an ESXi 5.5 Update 3a Host. When running the uninstall script ...

This is a special post...apart from being this blog's 200th it's a great week for all those who have dedicated time and effort into VMware's vCloud Director....
It's been a big week for vCloud Director! For those still running the 5.6.x SP Build there was a point release last week taking vCD SP to 5.6.5 Build 3307437...
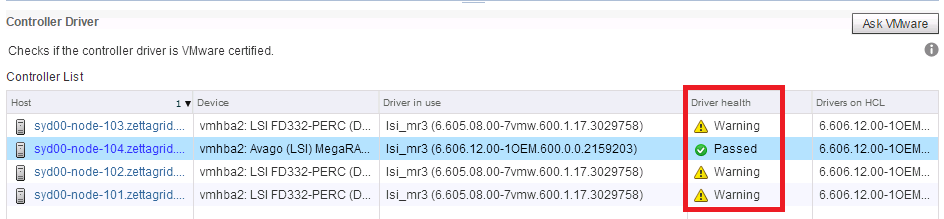
Last week VMware released a patch to fix another issue with Change Block Tracking (CBT) which took the ESXi 6.0 Update 1 Build to 3247720. The update bundle ...
Last week I wrote a piece on the talk around vCloud Air’s demise or more to the point...the often suggested demise of VMware's Public Cloud Platform. The bas...
Certificates and VMware don't have a great history and there are a lot of posts out there centered around people's struggles with vCenter, Lookup Service or ...
I’ve been wanting to write some commentary around the vCloud Air and Virtustream merger since rumours of it took place just before VMworld in Auguest and I’v...
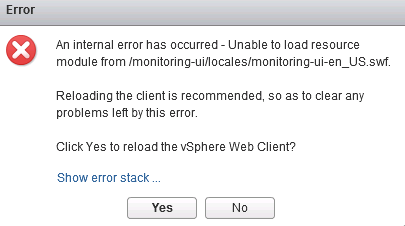
This quick fix post is for those out there who are still using vCenter Operations Manager 5.8.x and are or thinking about deploying or upgrading to vCenter 6...
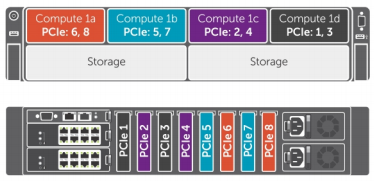
When you get your new DELL FX2s out of the box and powered on for the first time you will notice that the disk configuration has not been setup with VSAN in ...

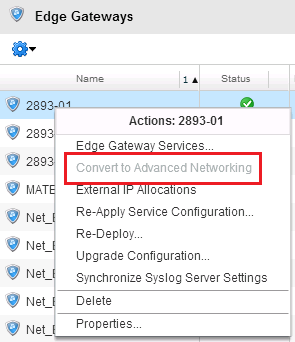
A few weeks back at Zettagrid we released our NSX Advanced Networking product that we have been working on for the best part of 12 months. I’m particularly p...
During VMworld CloudPhysics released their new Dashboard Feature which saw a change of direction in the way CloudPhysics customers get presented with their d...
Back in September I wrote an introductory post (If you haven't read that post click here ) on the DELL PowerEdge FX2 HCI hardware and why we had selected it ...

Today Ninefold (an Australian based IaaS and PaaS) provider announced that they where closing their doors an would be migrating their clients to their parent...
Today is a great day for Zettagrid…we have officially released our NSX Advanced Networking feature that extends the networking functionality of our vCloud Ba...
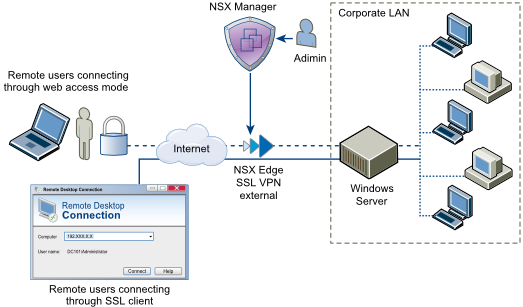
Overview : The SSL VPN-Plus feature has been around since the VSE 5.x days and as I've found out was possibly the best underused feature of the VSE. Contribu...

Yesterday at the long awaited reboot of the Perth VMUG here in Western Australia I chaired a vExpert/vChampion Panel that included Alex Barron , Luke Brown ,...

This is something to look out for if you are upgrading from vCloud Director 5.5.x to 5.6.x SP and if you have altered the syslog settings of your cells....Th...

Last week Veeam released Update 3 for Backup & Replication 8 taking the build number to 8.0.0.2084 and with the update, Veeam have released a couple new feat...
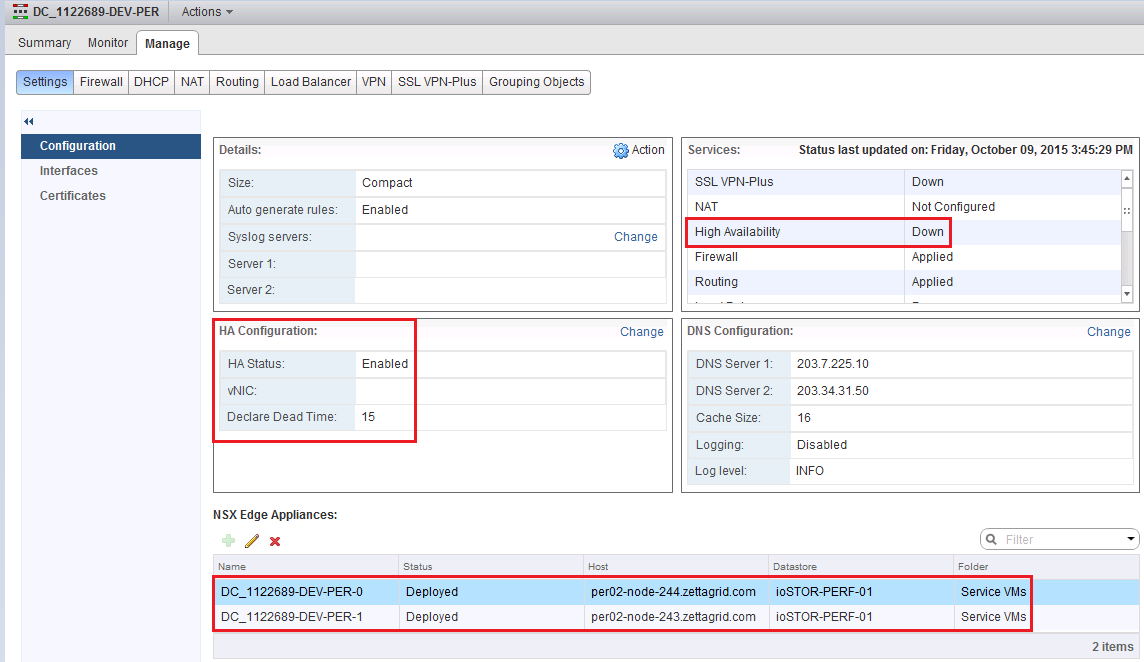
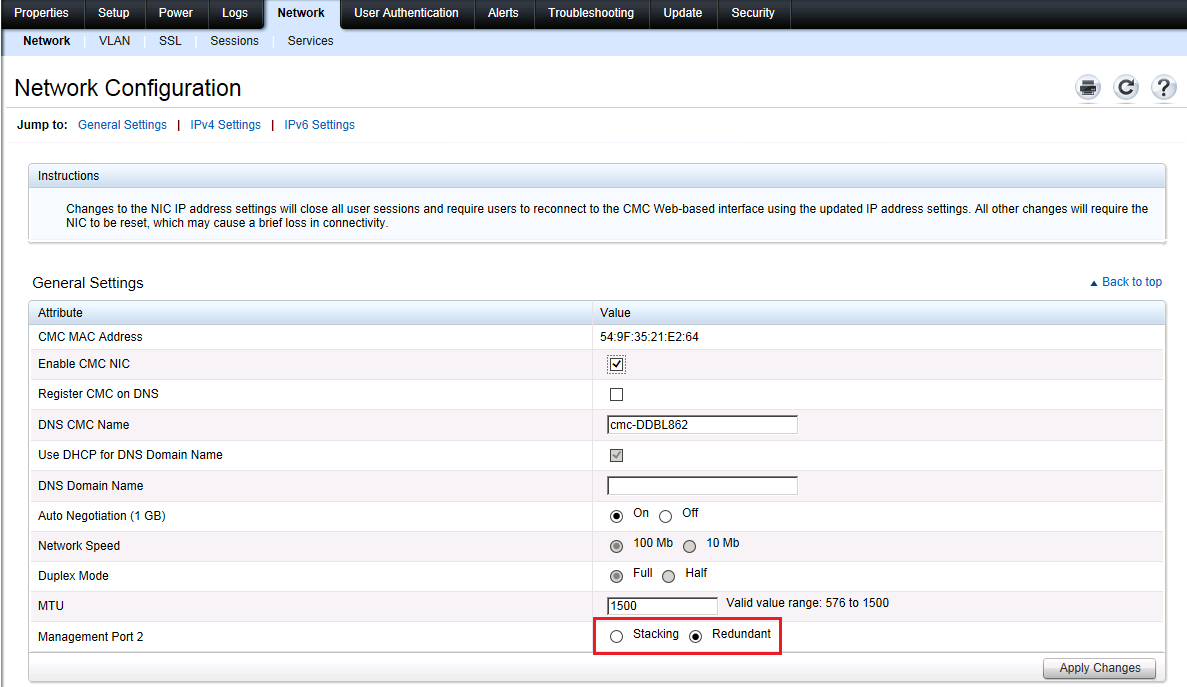
In doing some testing around NSX Edge deployment scenarios I came across a small quirk in the High Availability Config for the NSX Edge Gateway where by afte...
Since June the vCloud Director SP Beta has been running with a lot of renewed interest in the IaaS Platform. The beta was well participated in and there was ...
Last week NSX-v 6.1.5 ( Build 3102213 ) was released...This is a minor point release but does resolve a number of bugs present from previous 6.1.x builds and...
When working with NSX you have the option to create logical switches that are bound by Transport Zones...within those Transport Zones you could have a single...
Since VMworld in San Francisco, VMware have been on a tear backing up all the VSAN related announcements at the show by starting to push a stronger message a...

PernixData had a number of announcements at Virtualization Field Day back in June including details around their v3 release of FVP as well as the announcemen...
Had a situation pop up today where an NSX Edge needed to be moved from it's current location to another location due to an initial VM placement issue. The VM...

vSphere 5.5 Update 3 was released earlier today and there are a bunch of bug fixes and feature improvements in this update release for both vCenter and ESXi....
While at VMworld a couple of weeks ago I presented a short talk around my journey working with NSX-v and how it has shifted ( pivoted ) the direction of what...

Those that know me know that I am a very proud Australian of Maltese decent ...so when I was emailed a while back to see if I would review the beta for Altar...
At the Virtualization Field Day back in June PernixData Announced they would be releasing a free version of their FVP software... FVP Freedom . Overnight Fre...

Last week at VMworld I was lucky enough to spend some quality time with the PernixData team and got some great insights into their future products including ...

Last week at VMworld we had the annual vExpert Reception…this year the party was held at the very swanky Julia Morgan Ballroom in the Merchants Exchange buil...
Over the past year the guys at CloudPhysics have been relatively quiet compared to the proceeding 3 years since they burst onto the Scene at VMworld 2012. Th...

The vBrownbag Tech Talks are back on again this year at VMworld and it gives those who might have missed out on getting an official session accepted at this ...
Its been a couple of weeks since I wrote this post on the need for improvement with the vCloud Director UI and the response I've had to the article through t...
NSX for vSphere version 6.2 was made Generally Available earlier today and there has been some significant updates and improvements to the Network Virtualiza...

Rubrik is a company a lot of IT Professionals have been keeping an eye since release of their v1.0 Appliance back in May. Their industry DNA is extremely imp...
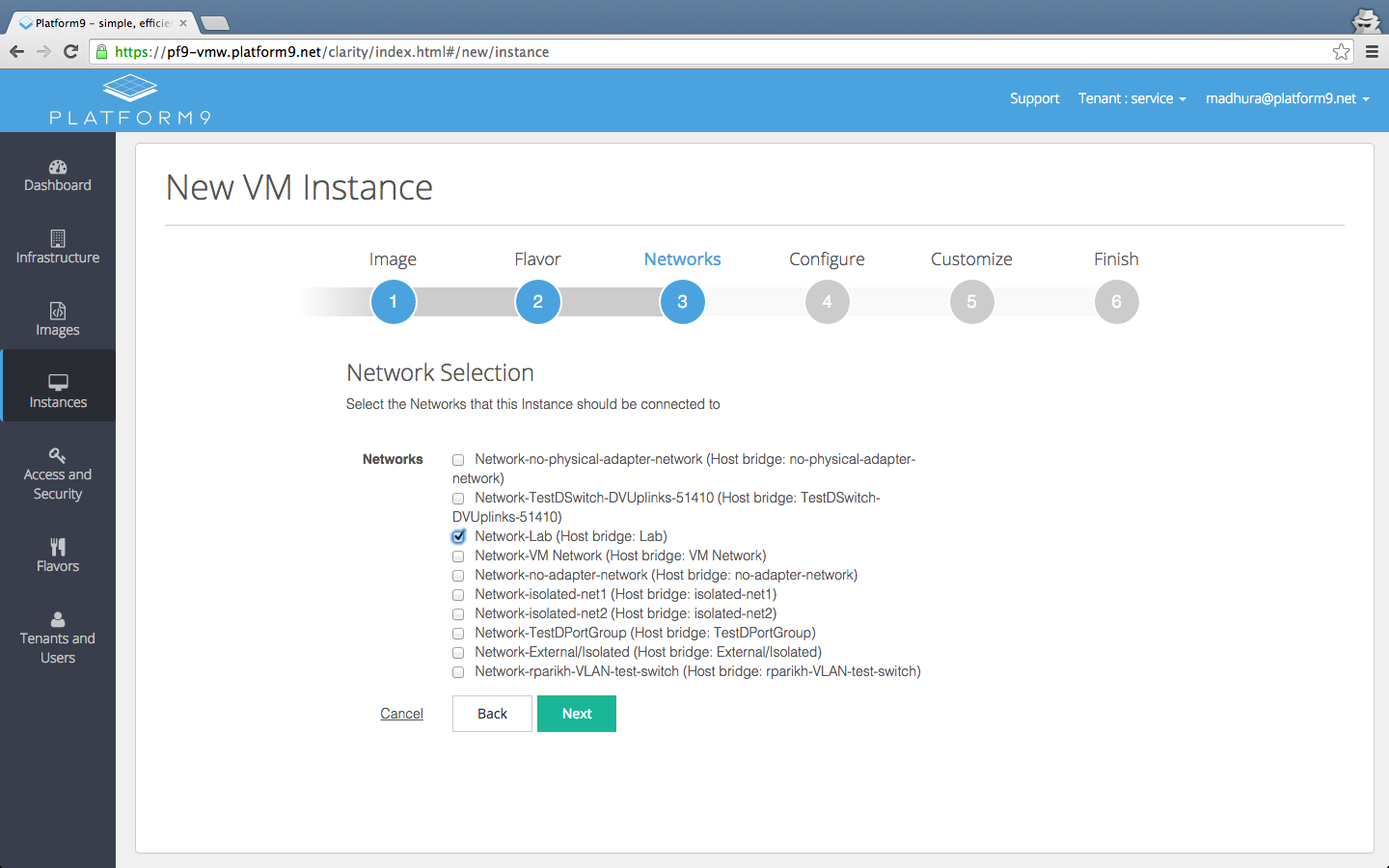
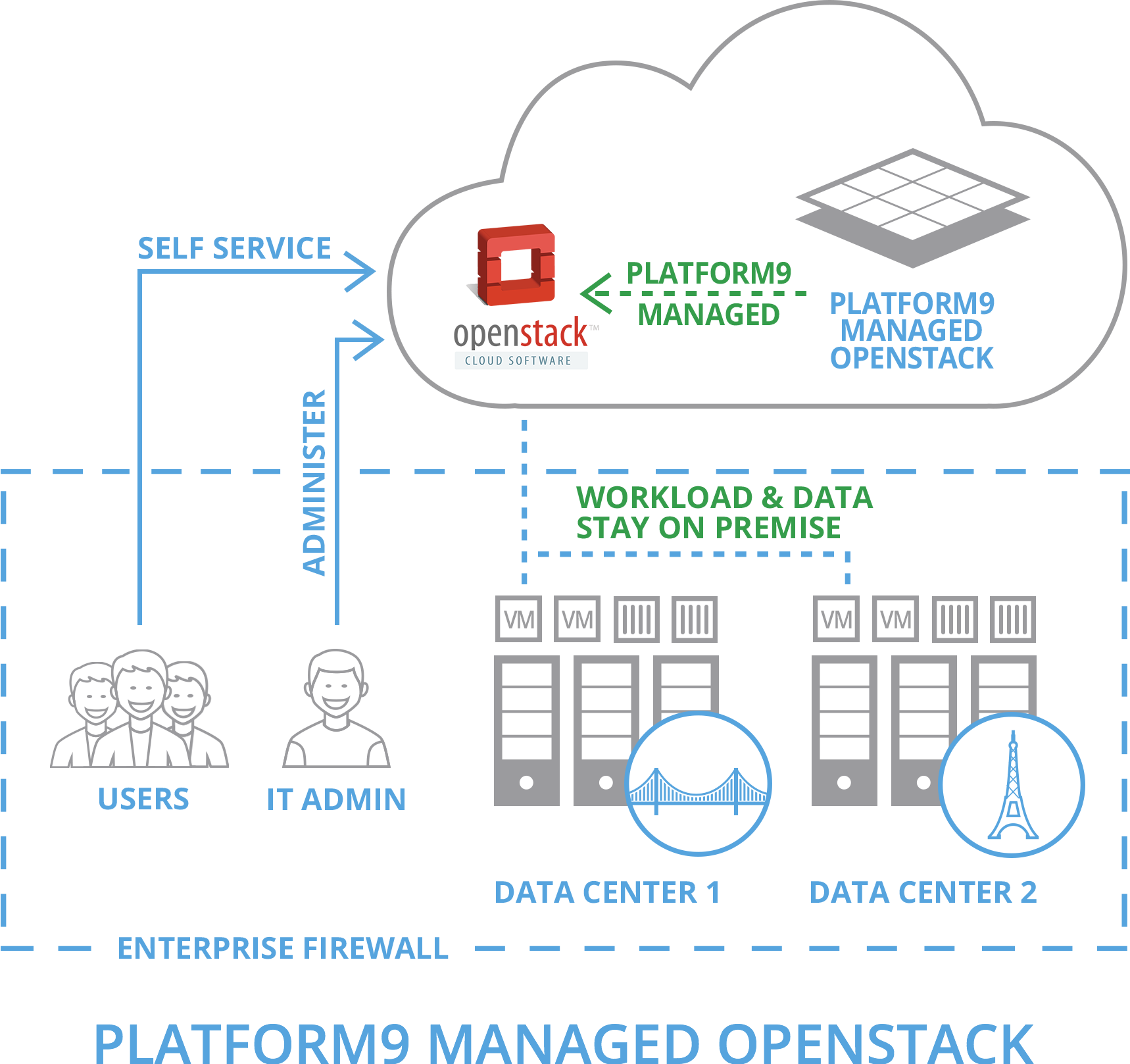
Today, Platform9 have announced the General Availability of their Managed OpenStack for VMware vSphere environments which adds to Platform9's ability to mana...
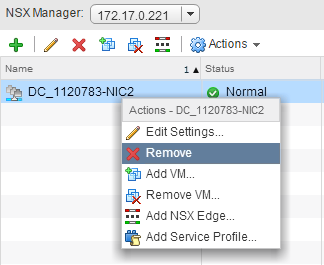
I came across an situation today where I was doing a clean up of Logical Switches in my NSX Lab where I was unable to remove a logical switch due to it appar...

For those that are not aware, VMware has had their Lab Flings going for a number of years now and on the back of the latest release ( ESXi Embedded Host Clie...
The vCloud Director 8 SP Beta program has been going for a couple of months now and there has been decent activity in the Discussion Forums and also a good n...
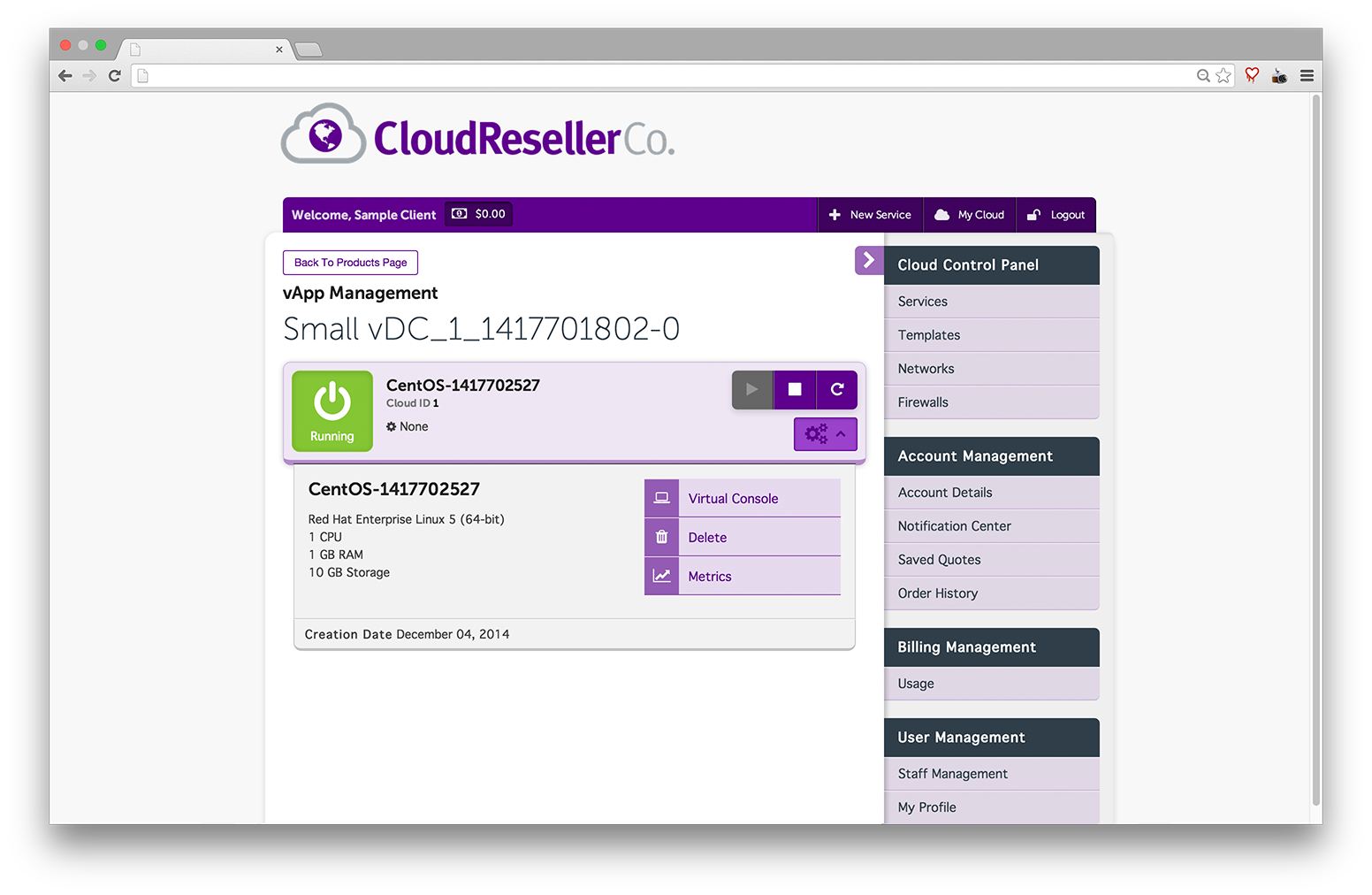
As those who have been using vCloud Director for a while...the ISO/OFV upload/download functionality can be frustrating to use at the best of times even thou...
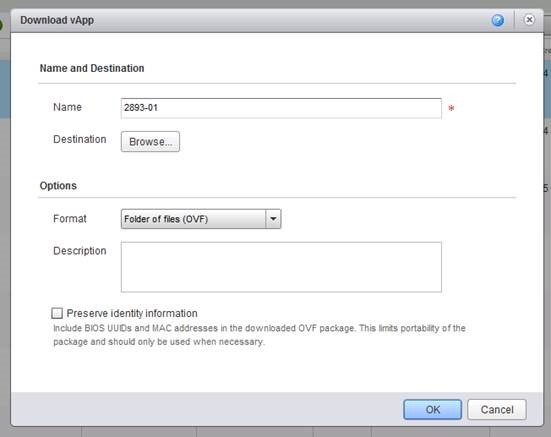
Last week I had a requirement to look at how to allow customers to export VM's and vApps from our vCloud Director Zones without using the UI. I've known abou...

VMworld 2015 is just around the corner (5 weeks and counting) and the theme this year is Ready for Any …and it looks like there will be some carryover of the...
There is a lot of talk going around how IT Pros can more efficiently operate and consume Cloud Based Services...AWS has lead the way in offering a rich set o...
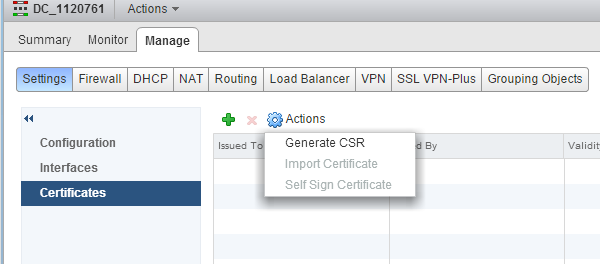
Overview : With the VSE and NSX Edges there are a number of features that can take advantage of Certificate services both as authentication mechanisms and fo...
Over the past couple of weeks i've been helping our Ops Team decommission an old storage array. Part of the process is to remove the datastore mounts and pat...
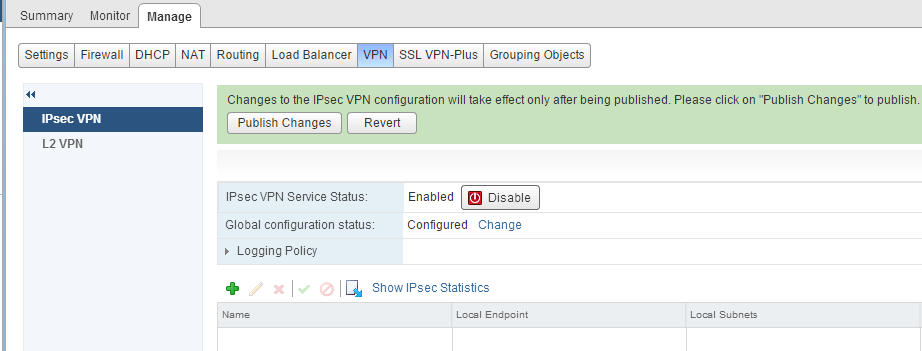
Overview : NSX and vShield Edges support site to site IPSec VPN between Edge instances and remote sites. Behind each remote VPN router, you can configure mul...
At Virtualization Field Day 2015, PernixData CTO Satyam Vaghani presented to the VFD5 delegates on some of the new features being released by PernixData. Per...

vCloud Director SP 5.6.x has the ability to export VM statistics to an external database source which can then be queried via a set of new API calls. I've go...
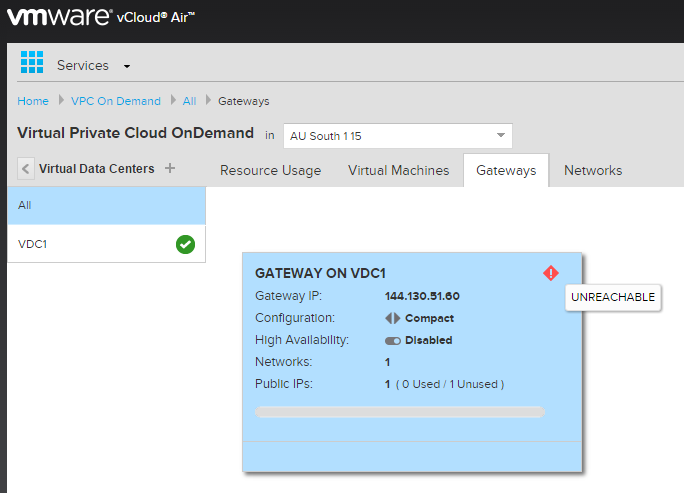
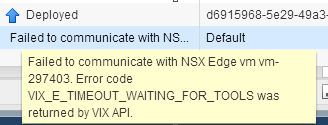
I've just come across a situation in my vCloud Air On Demand Service where the Edge Gateway was showing up as unreachable. Given vCloud Director is backing t...
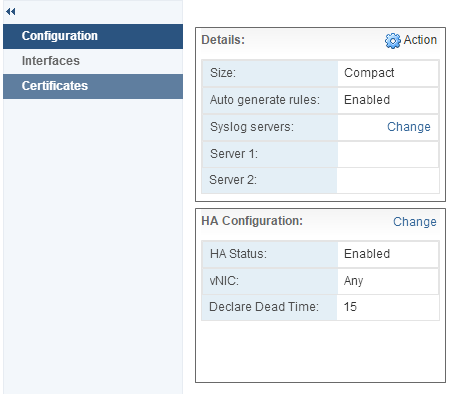
Overview : High Availability in both VSE and NSX Edges ensures Edge Network Services are always available by deploying a pair of Edge Appliances that work to...
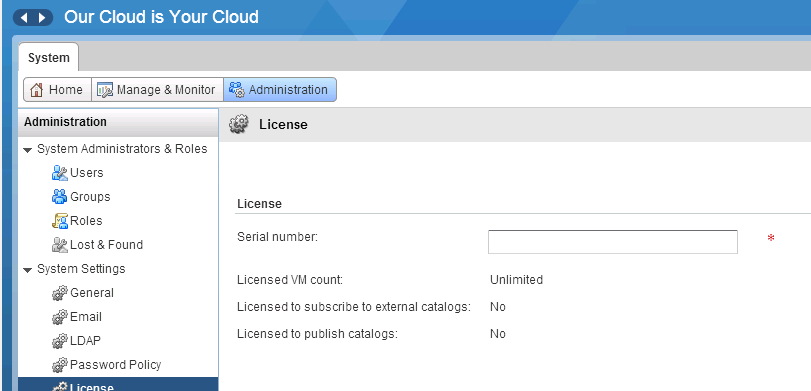
Thought I'd put up a very quick post on the process of upgrading from vCloud Director 5.5.x to vCloud Director SP 5.6.x. Any previous license key that you ha...
I was having a discussion internally about why we where looking to productize the NSX Edges for our vCloud Director Virtual Datacenter offering over the exis...

As posted a couple of weeks ago the Beta Program for the new SP Release of vCloud Director was announced and the kickoff was held yesterday morning (1st of J...
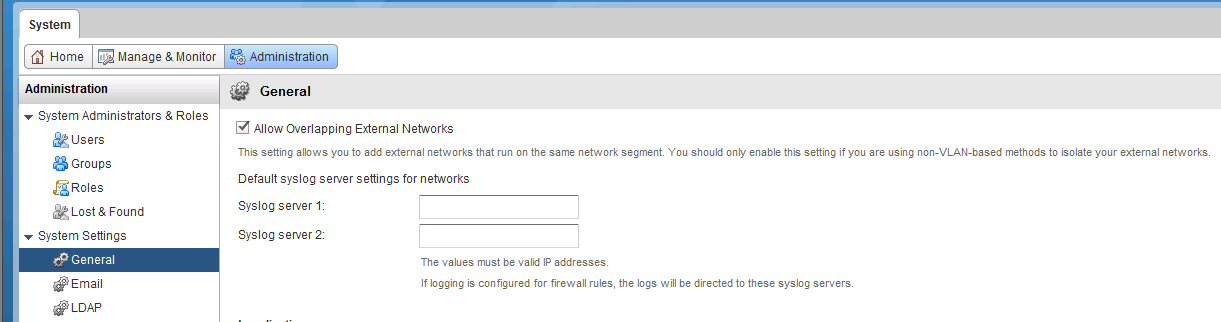
Part 4: vCloud Director Overlapping Networks : vCloud Director has the ability to allow Overlapping Network segments configurable from the Administration Tab...
vCloud Air Network Service Providers take note...rumours of vCloud's death where greatly exaggerated. Enterprise users...I still feel you are missing out on ...
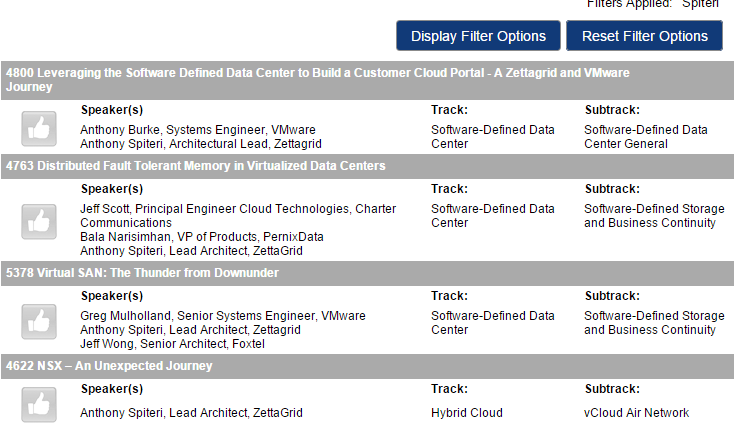
There are only 101 Days to go till VMworld 2015 with Registrations now Open and Session voting for this years event going live last week. Skimming through th...
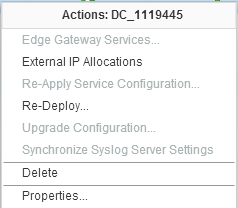
If you are familiar with vCloud Director Edge Gateway Services you might have come across situations where Edges become unmanageable and you see the followin...
Earlier in the week I did up a post on the vCloud Air On Demand Signup Process . As I've blogged about in the past, VMware reaffirmed their commitment to the...
Signing up with the promo code below gives you $500 of initial service credits and you are also in the draw for $500 in additional service credits for vCloud...
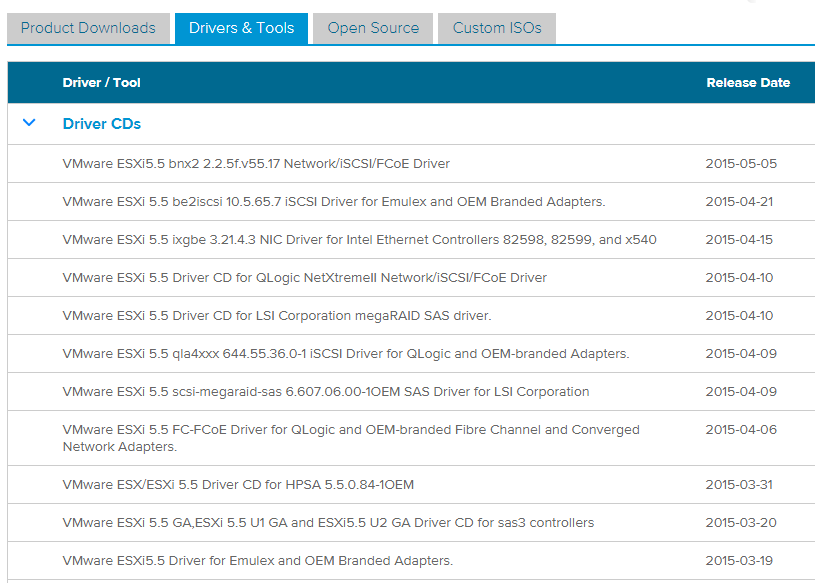
Today I needed to update an Emulex NIC Driver for an new host that I installed using the VMware ESXi 5.5 Update 2 base image. I needed to chase up the latest...
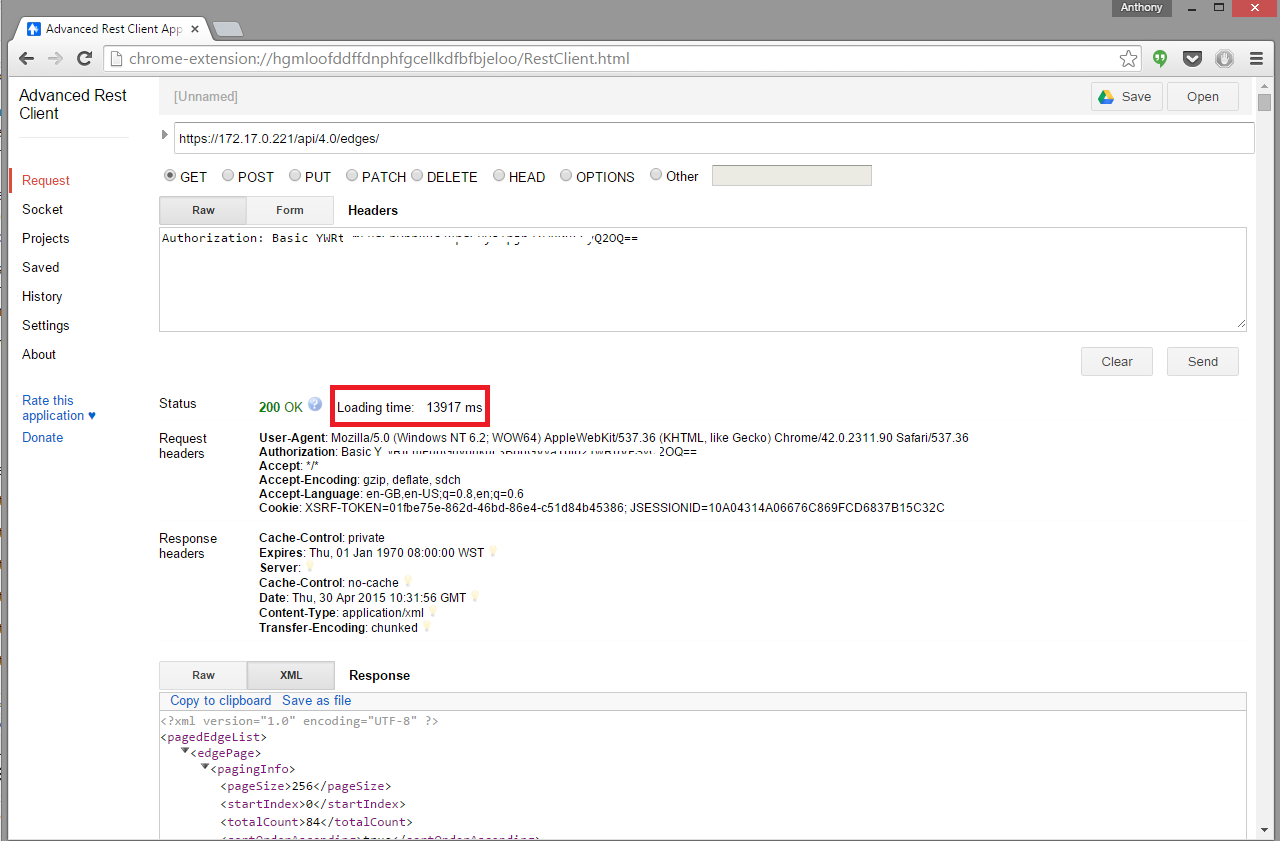
If there is one thing that working with NSX has done is drag me kicking and screaming into the world of APIs. Apart from being on the VCIX-NV Blueprint , in ...
This week VMware announced information around their Cloud Native Apps strategy...VMware Photon and Lightwave are aimed at the ever growing Container market w...
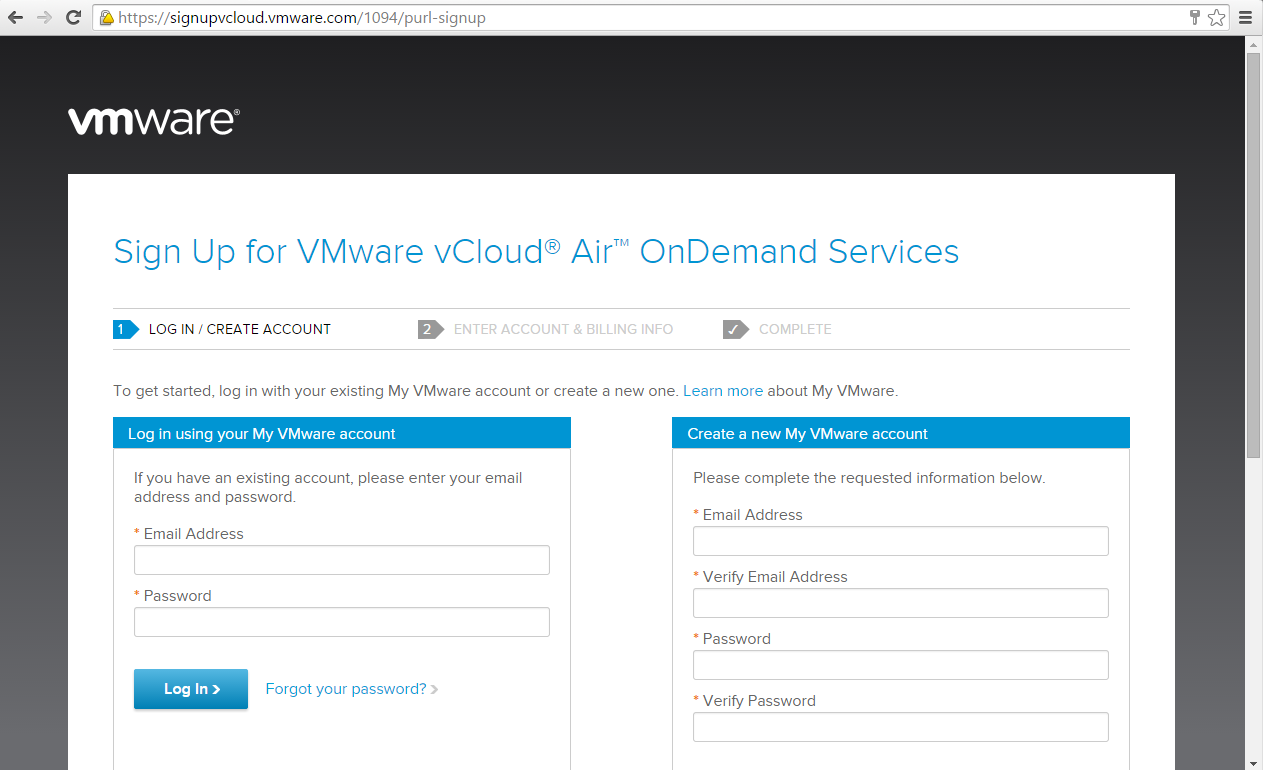
Last week VMware celebrated the official GA of vCloud Air in Australia . And while I've previously expressed mixed feelings around VMware's Public Cloud stra...
We have been working with VMware GSS on an issue for a number of weeks whereby we were seeing some vShield Edge devices go into an unmanageable state from wi...
There is a lot of talk going around how IT Pros can more efficiently operate and consume Cloud Based Services...AWS has lead the way in offering a rich set o...

The Top vBlog for 2015 Results where announced a couple of nights ago and Australia had strong representation throughout the 400 odd blogs listed at vSphere-...
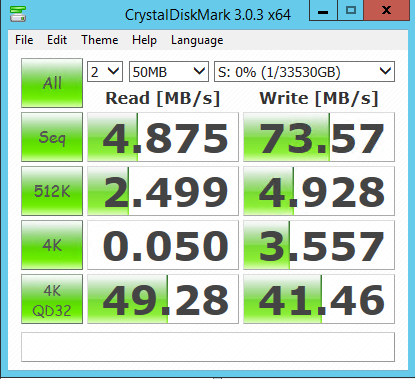
There are countless posts out there comparing E1000s and VMXNET3 and why the VMXNET3 should (where possible) always be used for Windows VMs. http://rickardno...
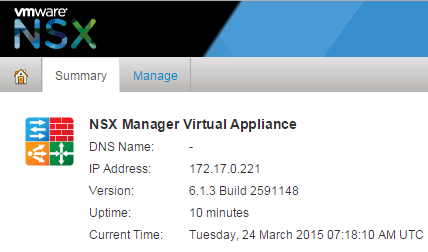
Earlier today NSX-v 6.1.3 was released. This update brings vSphere 6.0 Support as well as bug fixes and a couple minor feature enhancements. https://www.vmwa...
Like most VMware Junkies over the past 24 hours I've downloaded the vSphere 6.0 bits and had them ready and primed to deploy and discover all the new feature...
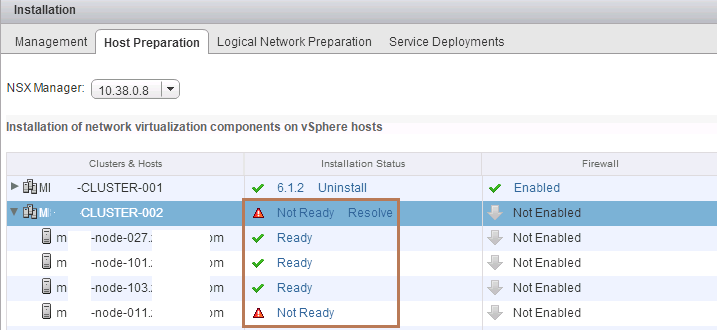
I came across a situation today while going through an NSX Setup and Configuration where I came across a Cluster under the Host Preparation Tab that was repo...
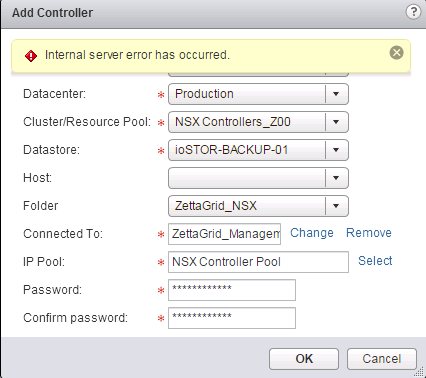
During my initial work with NSX-v I was running various 6.0.x Builds together with vCD 5.5.2 and vCenter/ESXi 5.5 without issue. When NSX 6.1 was released I ...
VMware Education dropped somewhat of a bombshell today when they announced the almost immediate retirement of the VCAP CIA/CID/DTA/DTD http://blogs.vmware.co...
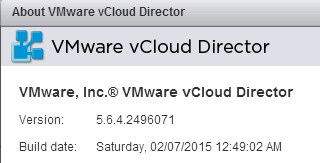
In October 2014 VMware released vCD SP 5.6.3 which was the first version of vCloud Director that was forked for Service Providers. As I mentioned in this pos...

This blog series extends my NSX Bytes Blog Posts to include a more detailed look at how to deploy NSX 6.1.x into an existing vCloud Director Environment. Ini...
I’m honoured to be recognized as a VMware vExpert for 2015…this is my 4 th year as a vExpert and without doubt the passion that drives this community remains...
Today vSphere 6.0 was officially announced and will be GA in about 6-8 weeks...I've had limited time myself to tinker with the BETA in great depth, however I...
VMware released new builds for vCenter and ESXi 5.5 today. The builds contain mostly bug fixes, but I wanted to point out one fix that had affected those who...
I came across Platform9 while wandering the back halls of the VMWorld Solutions Exchange last year in San Francisco…as a fan of the movie District 9 I was dr...
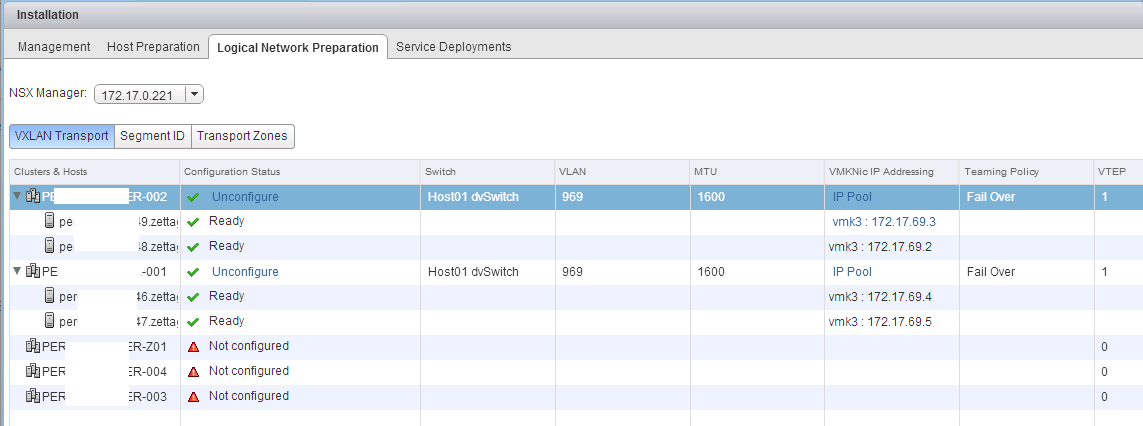
This blog series extends my NSX Bytes Blog Posts to include a more detailed look at how to deploy NSX 6.1.x into an existing vCloud Director Environment. Ini...
vCloud Director SP 5.6.3 was initially released in October 2014 was the first of the SP Editions that had been forked from the Enterprise 5.x builds that cam...
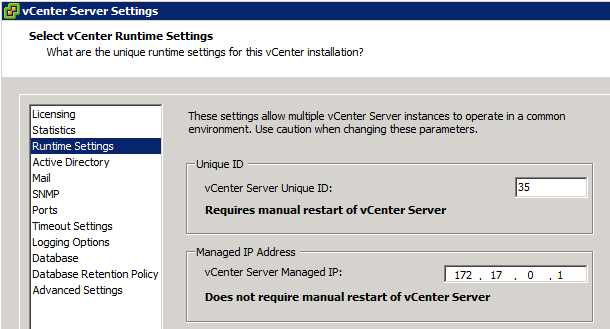
This blog series extends my NSX Bytes Blog Posts to include a more detailed look at how to deploy NSX 6.1.x into an existing vCloud Director Environment. Ini...
This blog series extends my NSX Bytes Blog Posts to include a more detailed look at how to deploy NSX 6.1.x into an existing vCloud Director Environment. Ini...

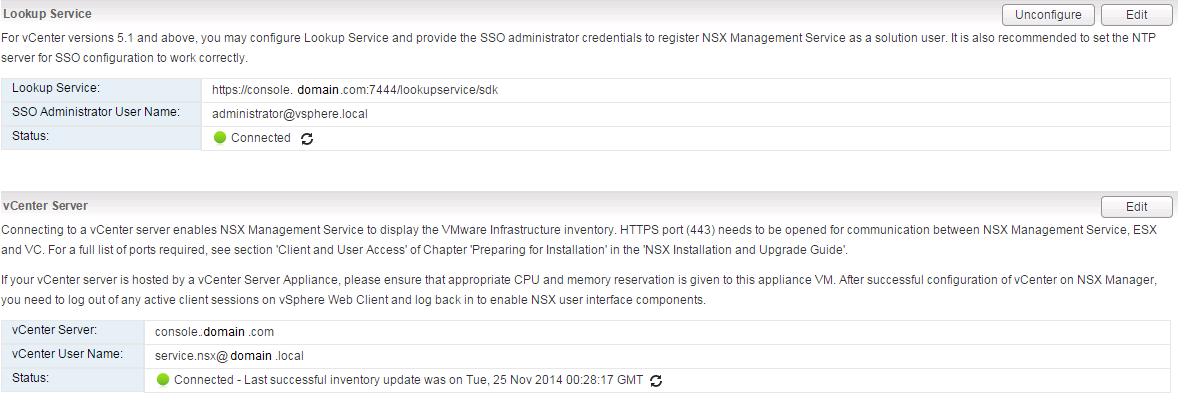
Part 1: Intro and VSM to NSX Manager Upgrade Part 2: NSX Manager Configuration and vCD VSE Deployment Validation Part 3: Controller Deployment, Host Preparat...

In my Lab deployments of NSX I've come across an issue whereby logging into the vSphere Web Client with authorized accounts results in the inability to manag...
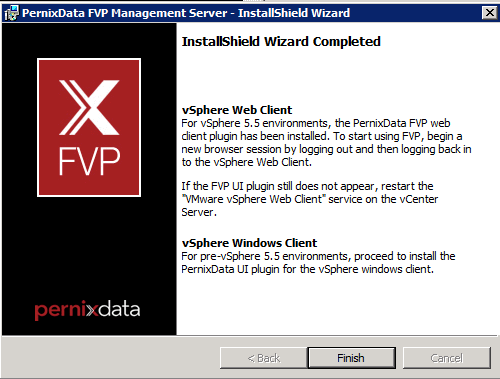
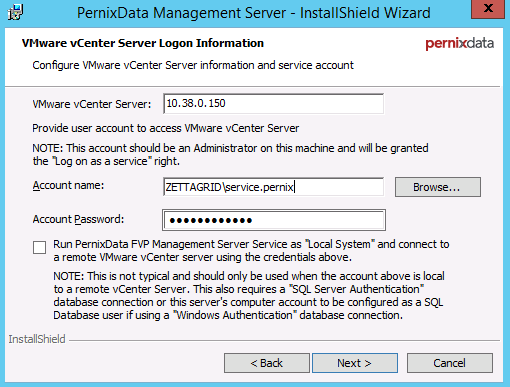
Posting a very quick fix to an issue that I have seen pop up during all my installs to date of PernixData FVP Management Server (v2.x) whereby the Management...

Another vForumAU has come and gone and upon reflection it was possibly the best event I’ve attended since my first one back in 2011. This year the venue for ...

"With regards to the upgrade path for SPs looking to deploy vCD SP there will be a build released approx. Q1 15 that will allow upgrades from 5.5.2" On the 8...

It's fair to say that it's not very often the difference between a 1 and 0 can have such a massive impact on performance...I had read a couple of posts from ...

We are currently in the process of upgrading all of our vCenter Clusters from ESXi 5.1 to 5.5 Update 2 and have come across a bug whereby the vMotion of VMs ...
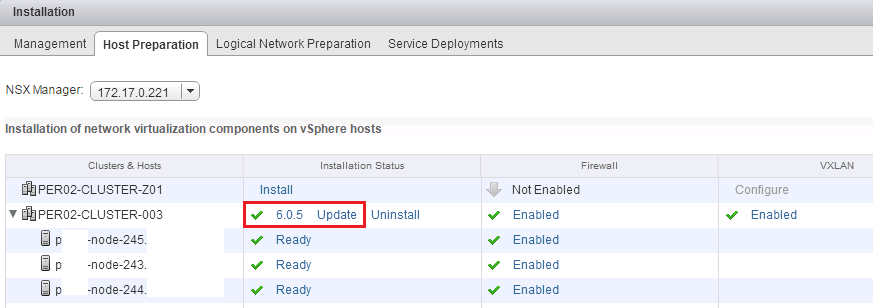
In Part 1 and Part 2 we went through the relatively straight forward upgrade of the NSX Manager and the more involved upgrading the NSX Controllers. To compl...

In Part 1 we went through the relatively straight forward upgrade of the NSX Manager. In this post we will upgrade the NSX Controllers from 6.0.x to 6.1. NSX...
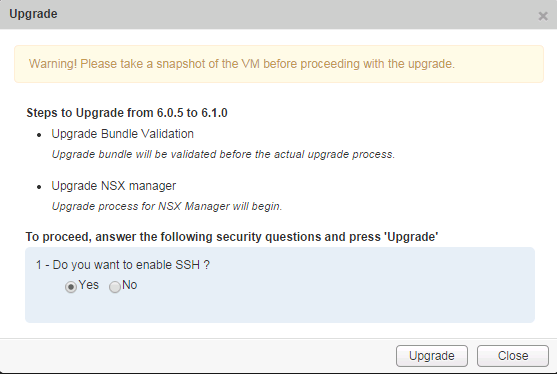
On the back of VMworld US and a bunch of other VMware Product Updates released last week...NSX 6.1 went GA late last week.... For a quick overview of the new...

A few months ago I wrote a quick post on a bug that existed in vCloud Director 5.1 in regards to IP Sub Allocation Pools and IP's being marked as in use when...
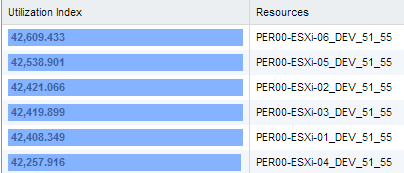
Late last year I was load testing against a new storage platform using both physical and nested ESXi hosts...at the time I noticed decreased network throughp...

Probably the biggest announcement from last week’s VMworld was the unveiling of the Project Marvin/Mystic as EVO:RAIL. Most of the focus on VMware releasing ...

I couple of months ago I wouldn't have seen myself writing up one of these blog posts which seems to be customary for any blogger who has taken a VCAP. Havin...

As mentioned in a previous post I was lucky enough to be able to present a #vBrownBag Tech Talk at this years VMworld. Even though the timing meant a smallis...
Those that have been following my Twitter over the past month or so would know that I took up the challenge to sit and pass my VCAP-DCA at VMworld 2014. Afte...
I must admit…I didn’t see this coming! One of my more recent posts a couple weeks ago was related to how VMware would engage with it’s Service Provider Partn...
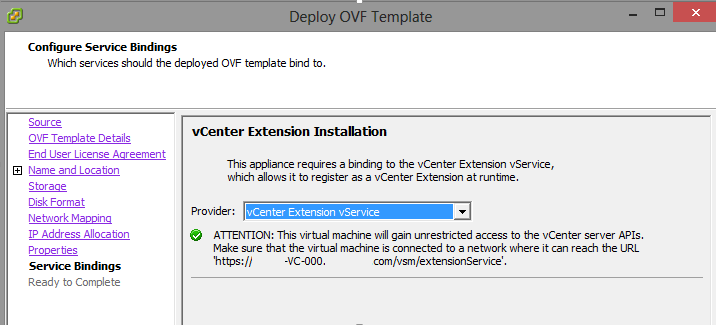
One of the new Objectives in the VCAP-DCA 550 is around the vSphere Replication Appliance. The Blueprint specifics that there will be one Replication Applian...
A couple of years ago I remember first hearing about Project Zepher which was rumored to be VMware's first attempt at a public cloud offering...though it was...

The power of a service like CloudPhysics continues to grow almost weekly as they add new features and Cards. Not only is it brilliant for analytics and metri...
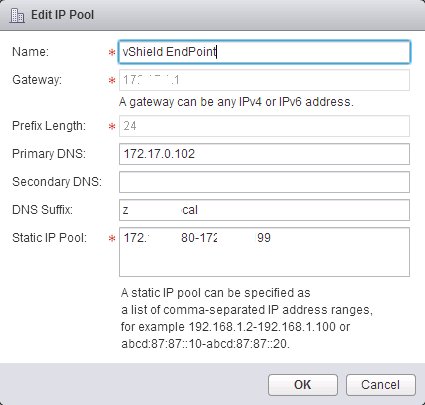
I recently had to deploy a solution into our Labs that required the installation of vShield Endpoint VMs to facilitate a 3rd Party service. No worries there....
A few months ago I wrote a quick post on a bug that existed in vCloud Director 5.1 in regards to IP Sub Allocation Pools and IP's being marked as in use when...
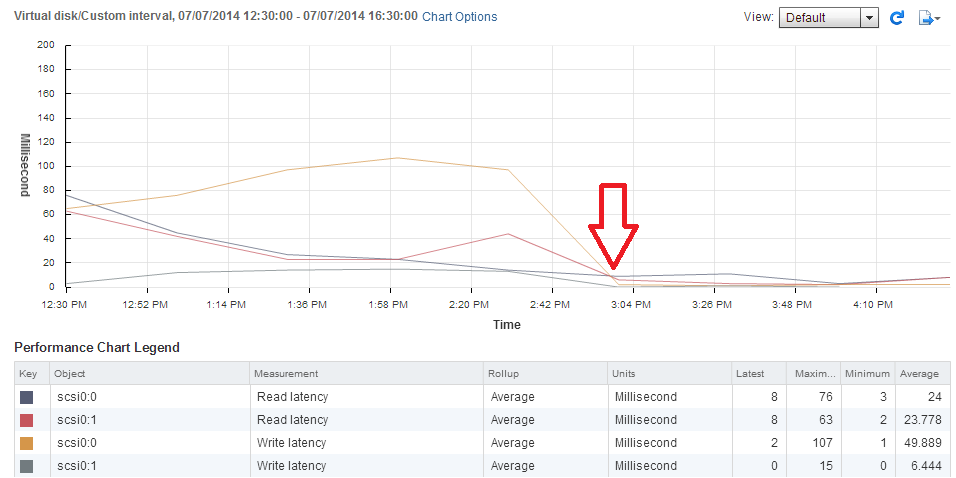
There is another NFS bug hidden in the latest ESXi 5.x releases...while not as severe as the 5.5 Update 1 NFS Bug it's been the cause of increased Virtual Di...
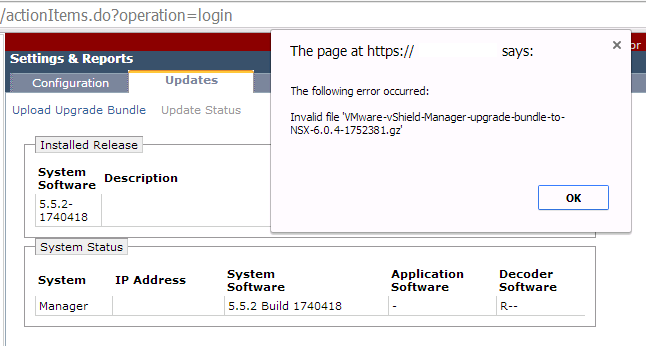
This is a really quick NSX Byte..but one that could save you some head scratching when looking to upgrade your vShield Manager to the NSX Manager. If you get...
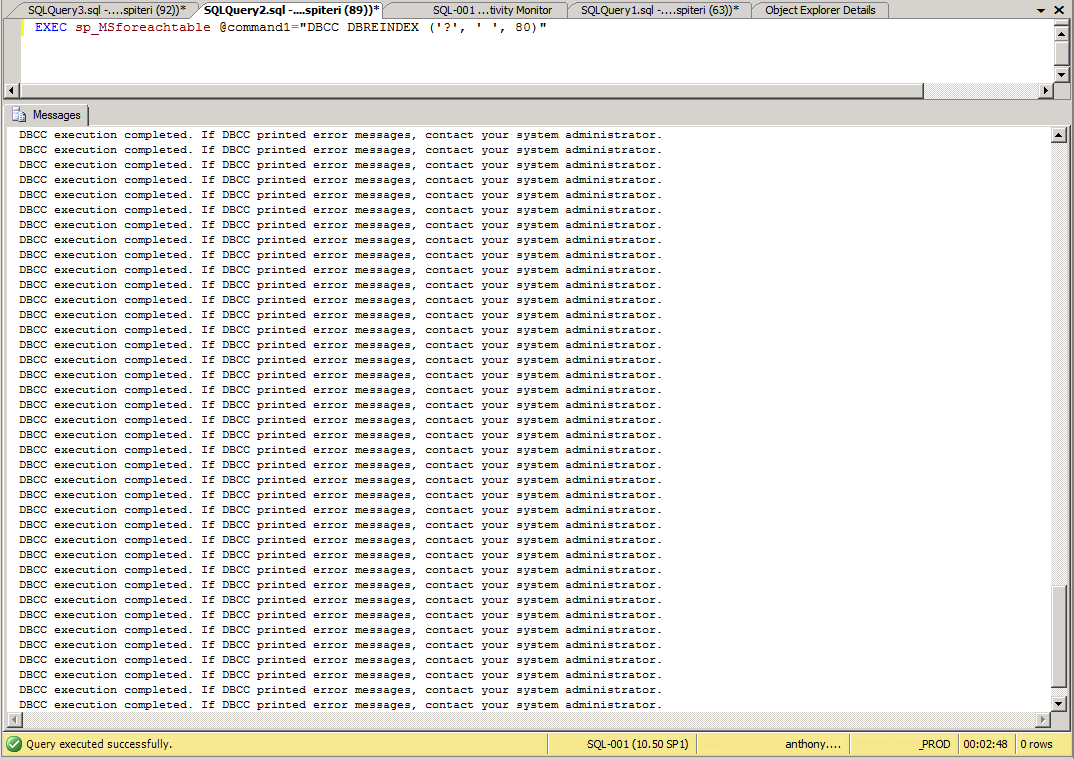
Generally speaking upgrading the vCloud Director binaries is a pretty straight forward task. It's a two step process where the Cell's are upgraded first foll...
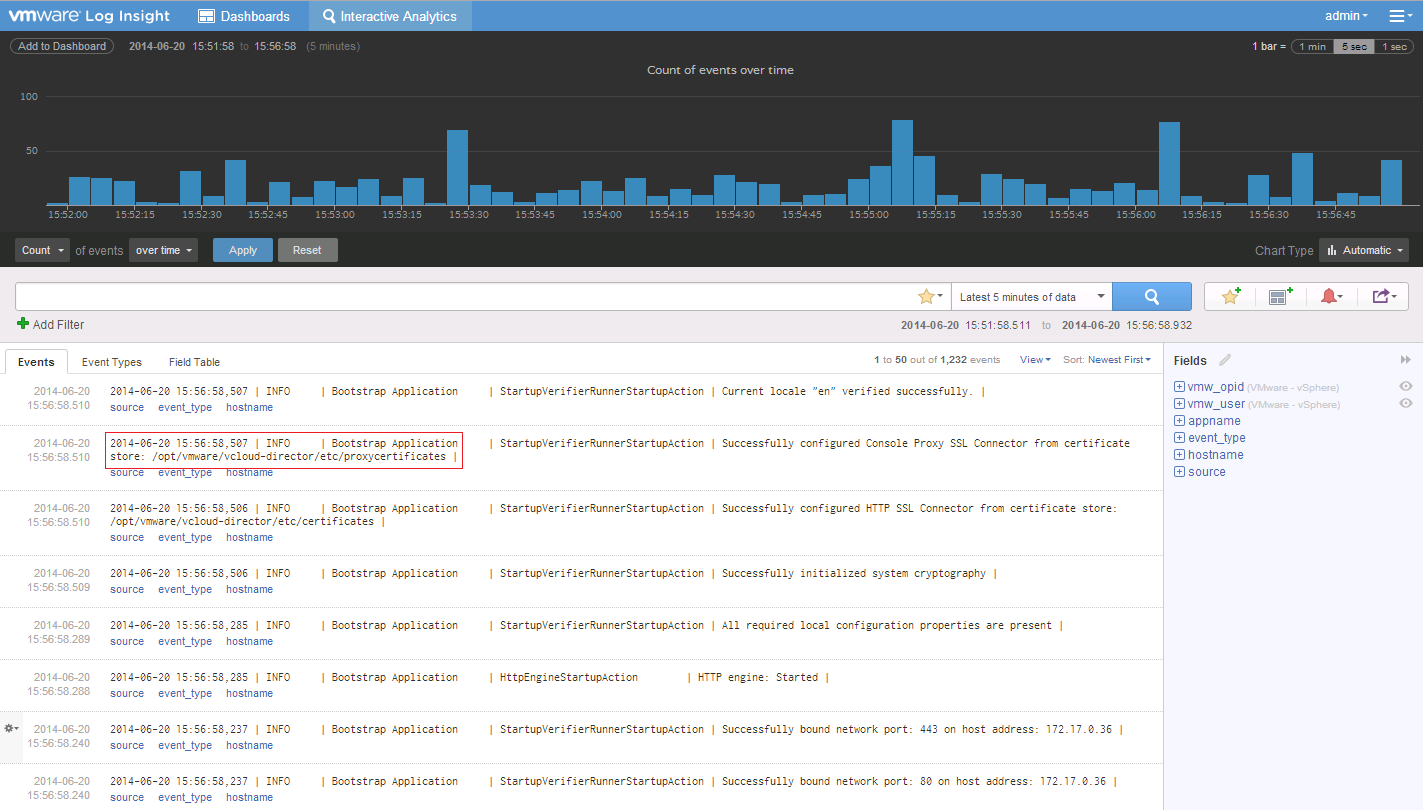
Recently v2.0 of VMware Log Insight became GA, and I've been playing around with it since it's release. Having been on the BETA of the 1.5 Version the 2.0 Ve...
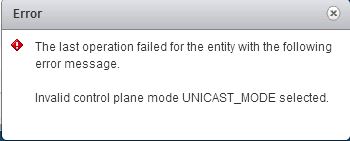
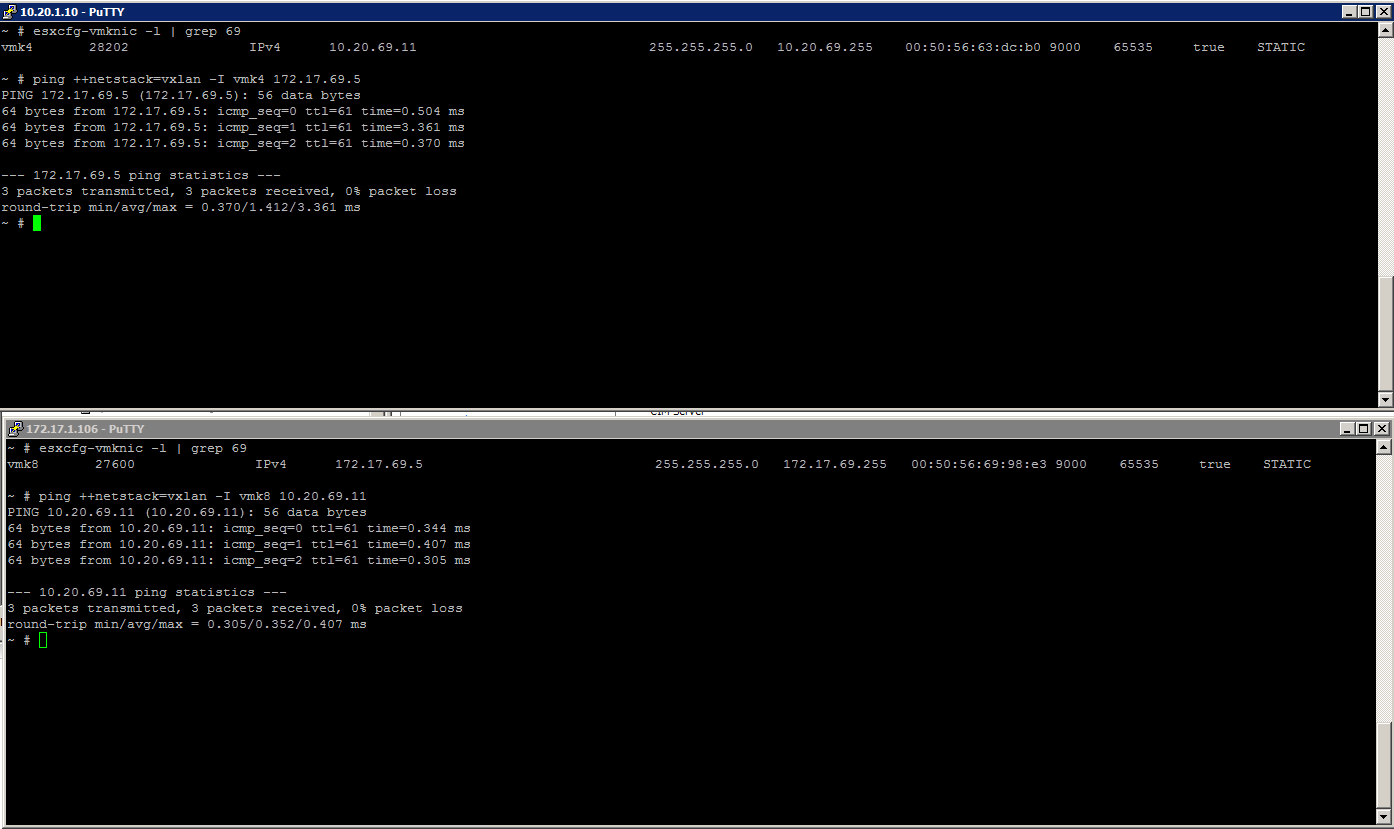
One of VMware NSX's best features is the ability to have the VXLAN Control Plane working in Unicast Mode...removing the requirement for Multicast traffic on ...
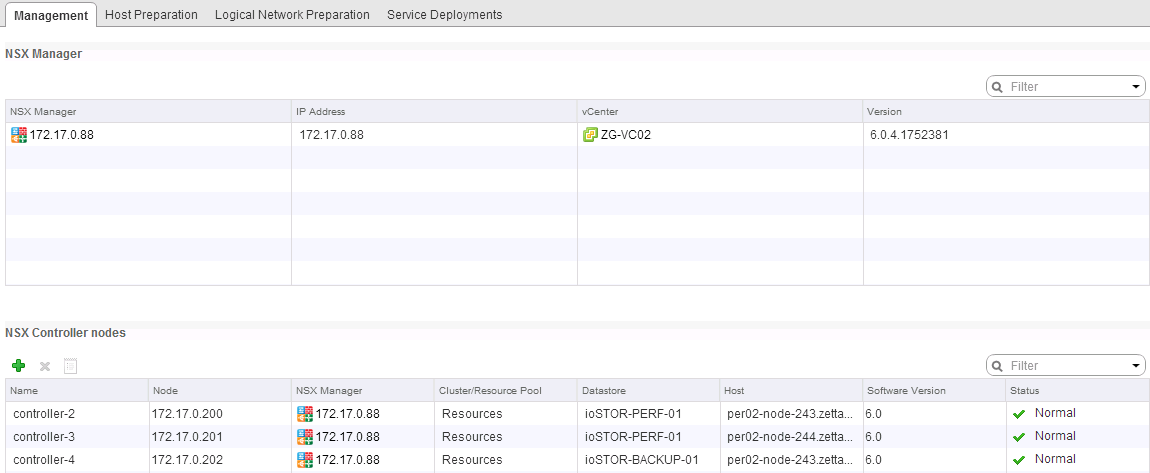
There are a lot of great posts already out there in regards to install and configuration of NSX. Rather than reinvent the wheel I've decided to do a series o...
About 7 weeks ago I wrote a post detailing my frustration at the way in which VMware's NSX was being trickled out into the market place and the hefty caveats...
![CloudPhysics: Enhanced Storage Analytics Cards [Part 2] – Snapshots Gone Wild 2](/images/2014/05/snap.png)
Following up from Part 1 which focused on the Datastore Contention v2 Card, I'll shift focus to what can sometimes be a Virutalization Admins worst nightmare...
Sometimes I think there is change just for the sake of change...or to keep us on our toes :) Either way I just came across an interesting upgrade gotchya whe...

Voting is Open for VMWorld 2014 and I have submitted three sessions for your consideration. The first session is a VMUG User Conference Presentation I Co-Pre...
I'm a little frustrated! When VMware announced that their Network Virtualization acquisition Nicira (rebranded NSX) was officially GA at VMWorld 2013 most ha...
![CloudPhysics: Enhanced Storage Analytics Cards [Part 1] - Datastore Contention](/images/2014/04/cp_s_1.png)
The guys at CloudPhysics have been busy behind the scenes of late working on improving an already great Analytic and Monitoring platform and recently I was a...

Time fly's where you are having fun! Two years ago I was privileged to be awarded my first vExpert Award...In that time I have been able to keep up my commun...
Just after the release of VSAN a couple weeks back, I wrote this post talking about the need for VSAN to appear on the VSPP pricelist. At the time there only...
UPDATE : Looks like we will be seeing some VSPP Pricing for VSAN in Q2 vCenter and ESXi 5.5 Update 1 has reached GA, and we now have v1.0 of VSAN officially ...
We have recently been working through a product where knowing and reporting on VM Max Read/Write IOPS was critical. We needed a way to be able to provide rep...
Over the past couple of months we have seen a number of support requests coming into our HelpDesk around network connection dropouts in Windows Server 2012 G...
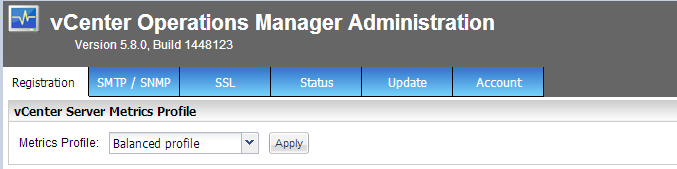
UPDATE : VMware Global Support supplied me with vCOPs 5.8.0 Hot Fix 01 Build 1537842 which is available via a support request. This is a complete .pak update...
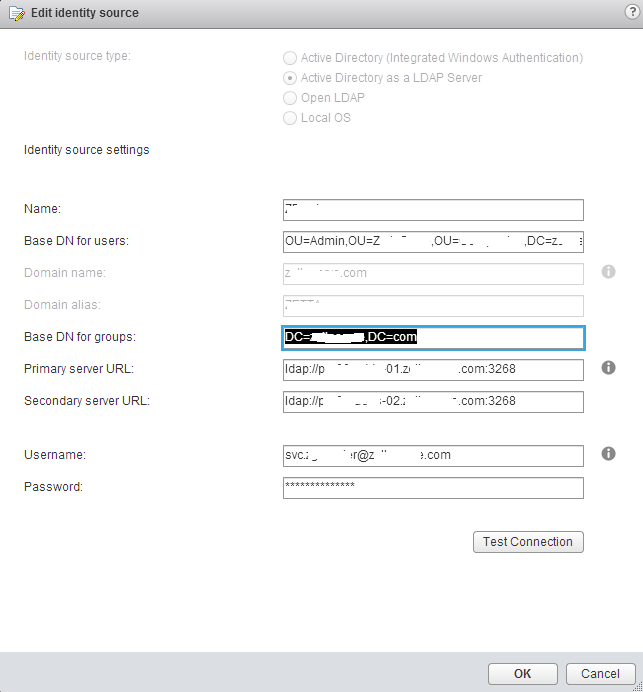
I've been running vCenter SSO 5.5 in mixed mode with vCenter 5.1 for a little while in our lab and production environment and recently had to configure exter...
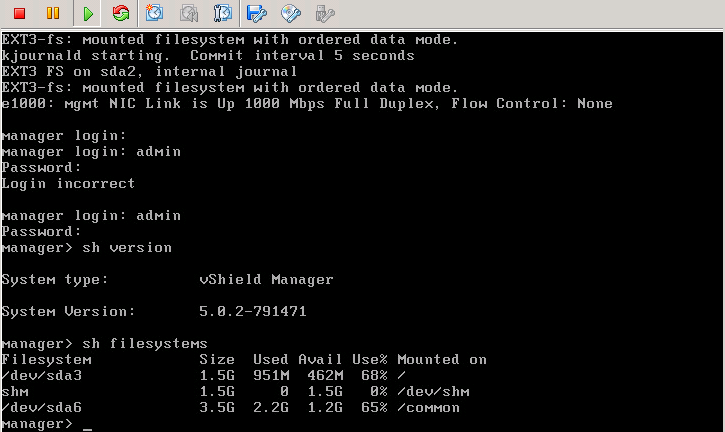
Having recently just completed the upgrading our vCloud Platform from 1.5 to 5.1 I thought it best to share my experiences around the upgrading of the vShiel...
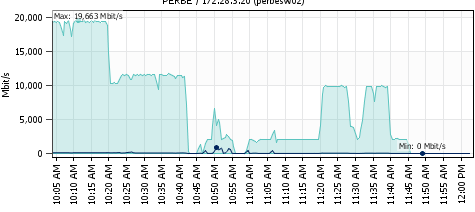
We have been conducting performance and stress testing of a new NFS connected storage platform over the past month or so and through that testing we have see...
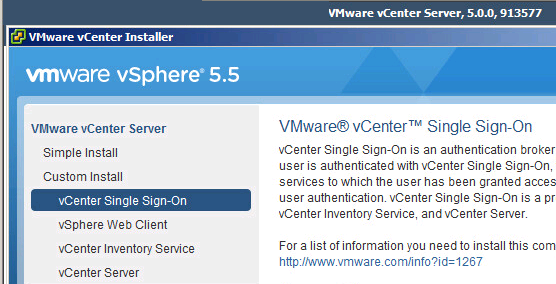
While at a post #vFourmAU event last week a group of us where talking about SSO in vCenter 5.1 and what a disaster it had been (credibility wise) and that VM...
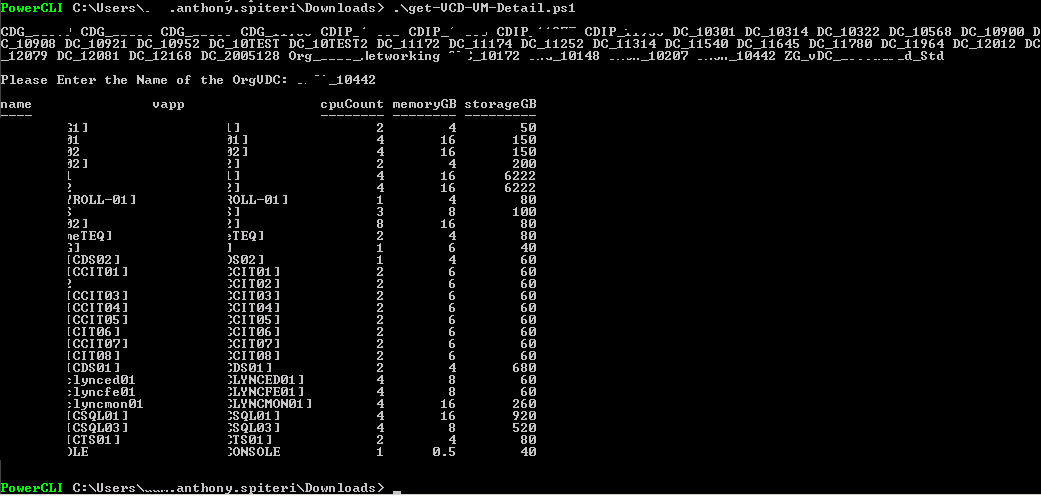
I had been looking for a way to get quick reports from our vCloud Zones using PowerCLI that reports on VM Allocated Usage. Basically I wanted to get a list o...
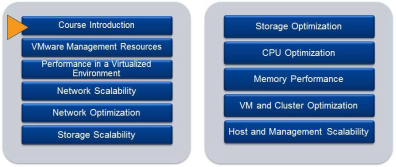
While it's fresh in my head, I thought I might get a short post up reviewing the Optimize and Scale Course I just completed this week. Overall I was impresse...
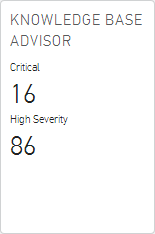
I've been lucky enough to have been early access to a new Card from the guys at CloudPhyics which, at it's core lets VMware admins quickly and precisely get ...
Over the last couple of weeks I've been fortunate to represent ZettaGrid, as a Platinum Sponsor of the VMware Series 2013 road shows in Melbourne and Sydney....
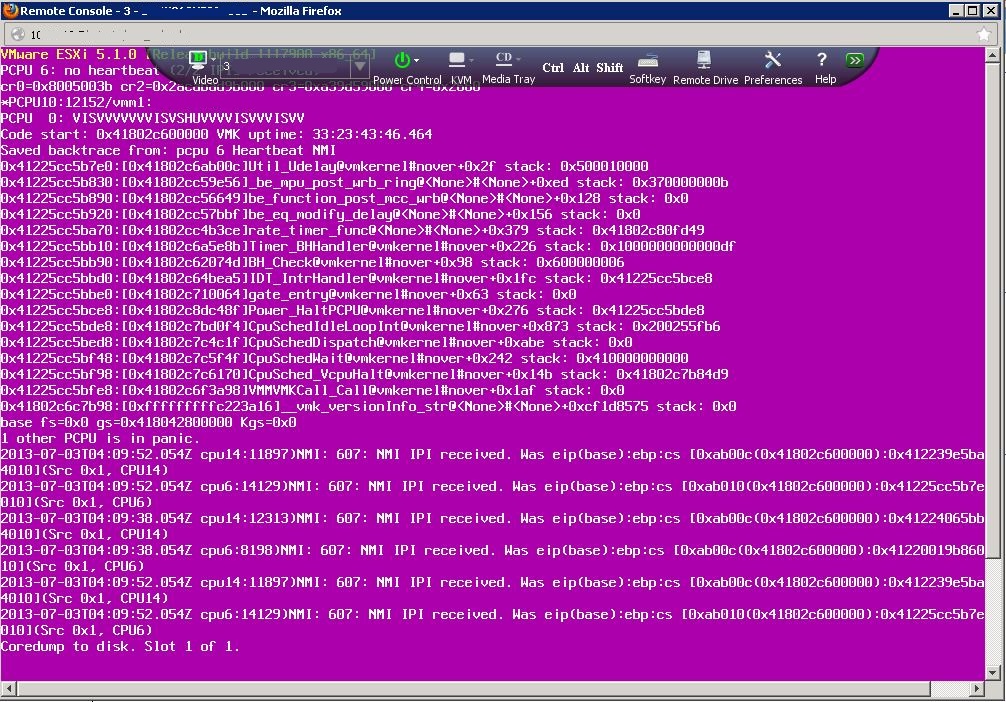
This is a quick informational post to warn anyone running an Emulex based 10GbE Converged Ethernet adapter in an IBM Blade Center with HS23 Series Blade serv...
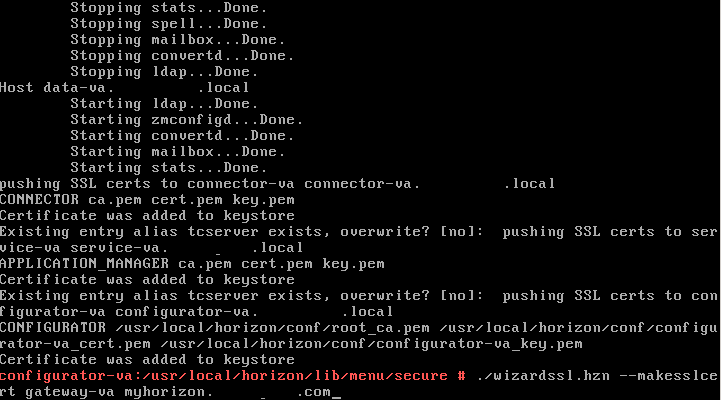
I came across this issue yesterday while trying to deploy a new instance on Horizon Workspace 1.0 in a POC environment. Having installed the vAPP a couple ti...
Almost exactly 12 months ago to the day I kicked off this site with this article describing my journey in virtualization leading up to my first vExpert 2012 ...
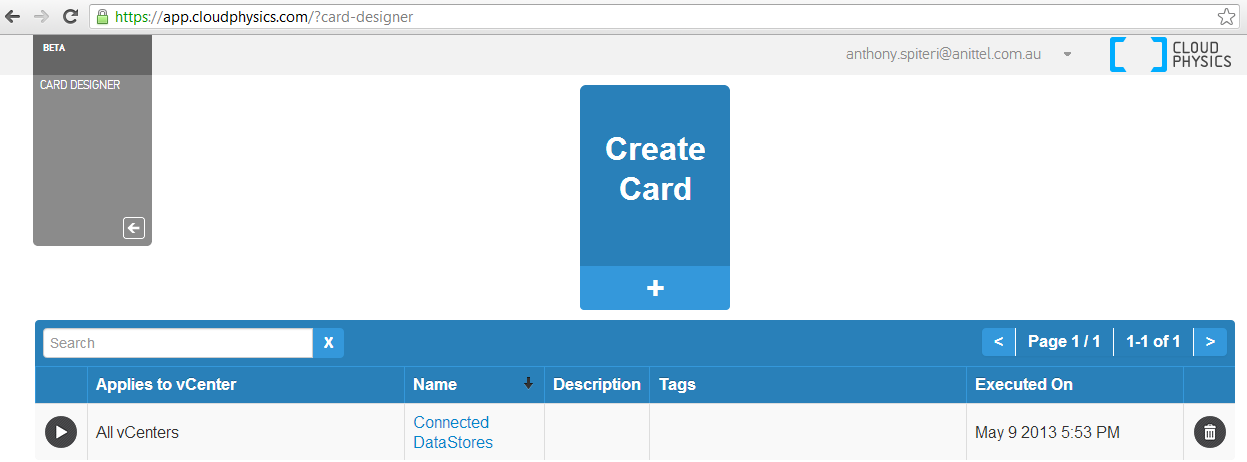
The boys at CloudPhysics are working hard behind the scenes at adding new features to their current stable of Analytic Cards based on data collected from t...
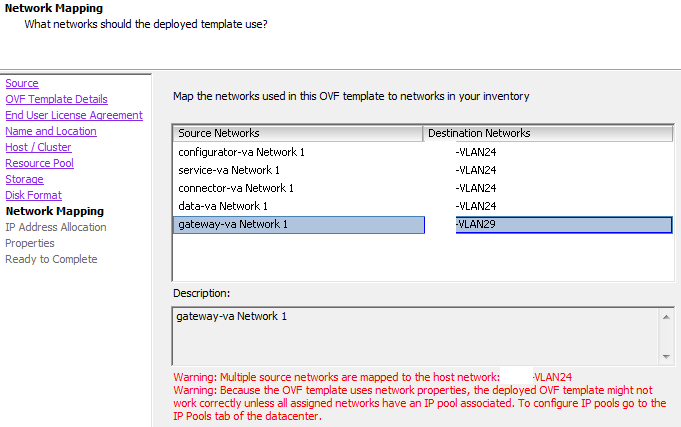
I've been waiting to deploy Project Octopus for the best part of 18 months... I'm still actively running the Octopus Beta and for my personal use/interna...
I was luckey to attend PEX at Australia Technology Park this week and thought I would share some of my take always. The venue was a little different to what ...
REMOVING DEAD PATHS IN ESX4.1 (version 5 guidance here ) Very quick post in relation to a slightly sticky situation I found myself in this afternoon. I was ...
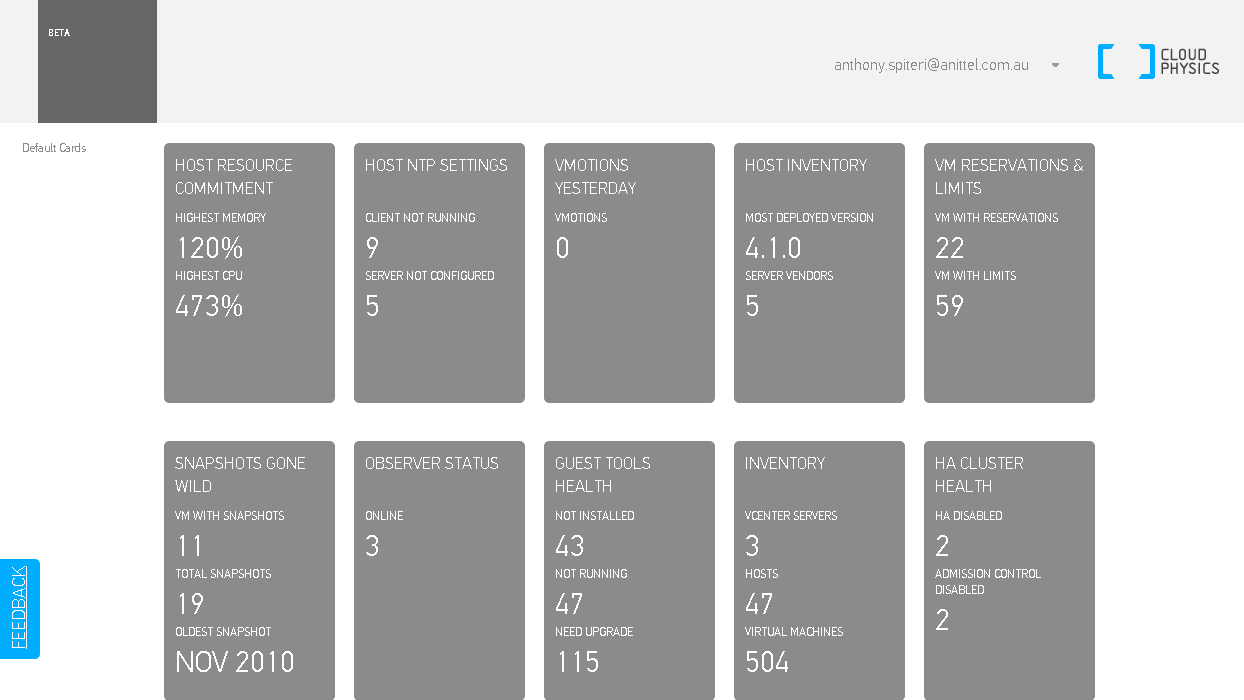
I first came across CloudPhysics just before VMWorld 2012. For a general overview, go here : I am a massive fan of analytics and trend metrics and I use a ...
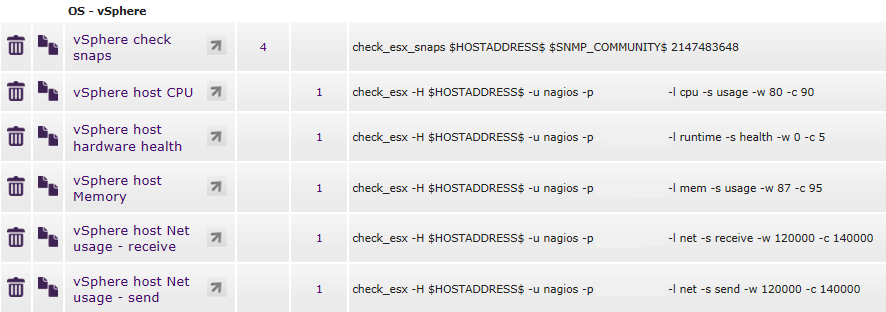
Unless my Google skills are seriously on the decline I wasn't able to find a definitive post on correctly setting up a nagios user to facilitate esx_chec...

The SSO Component of vCenter 5.1 throws a couple of spanners in the works with regards to a straight forward upgrade of an existing vCenter install. While no...
A few years ago there was a theory put forward by a certain Apple CEO that we were entering the Post PC Era…while I have never subscribed to that theory (w...
There where some pretty big announcements and reveals at VMworld 2012, but unless I missed something (which was totally possible had any accouncement been ma...
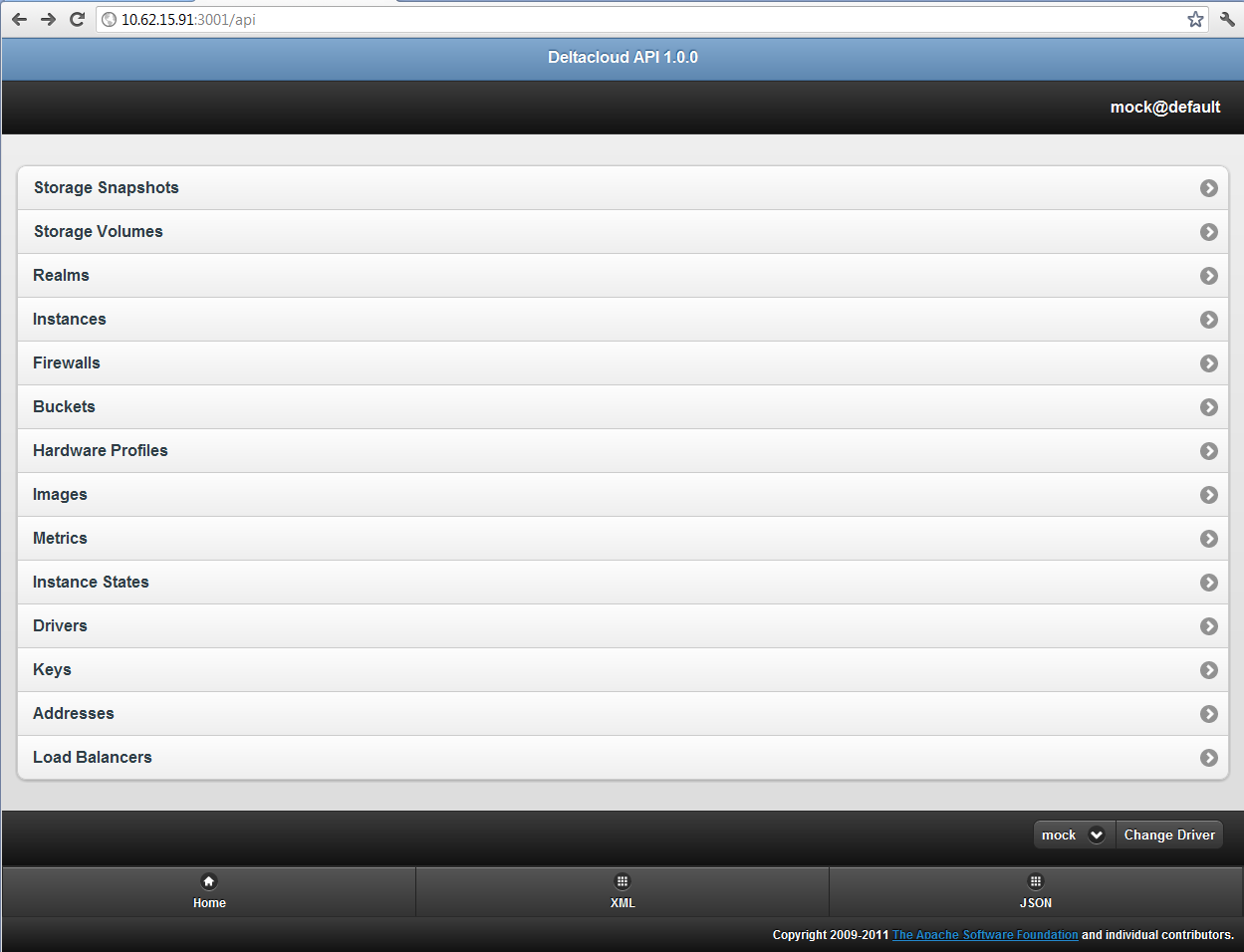
As I was browsing my Twitter feed last night I can across a tweet that talked about the 1.0 Release of Apache DeltaCloud. As described on the website : Delta...
VMware announced overnight that their aquired Private Social Media Platform SocialCast is to have full features enabled for 50 users. http://www.vmware.com/c...
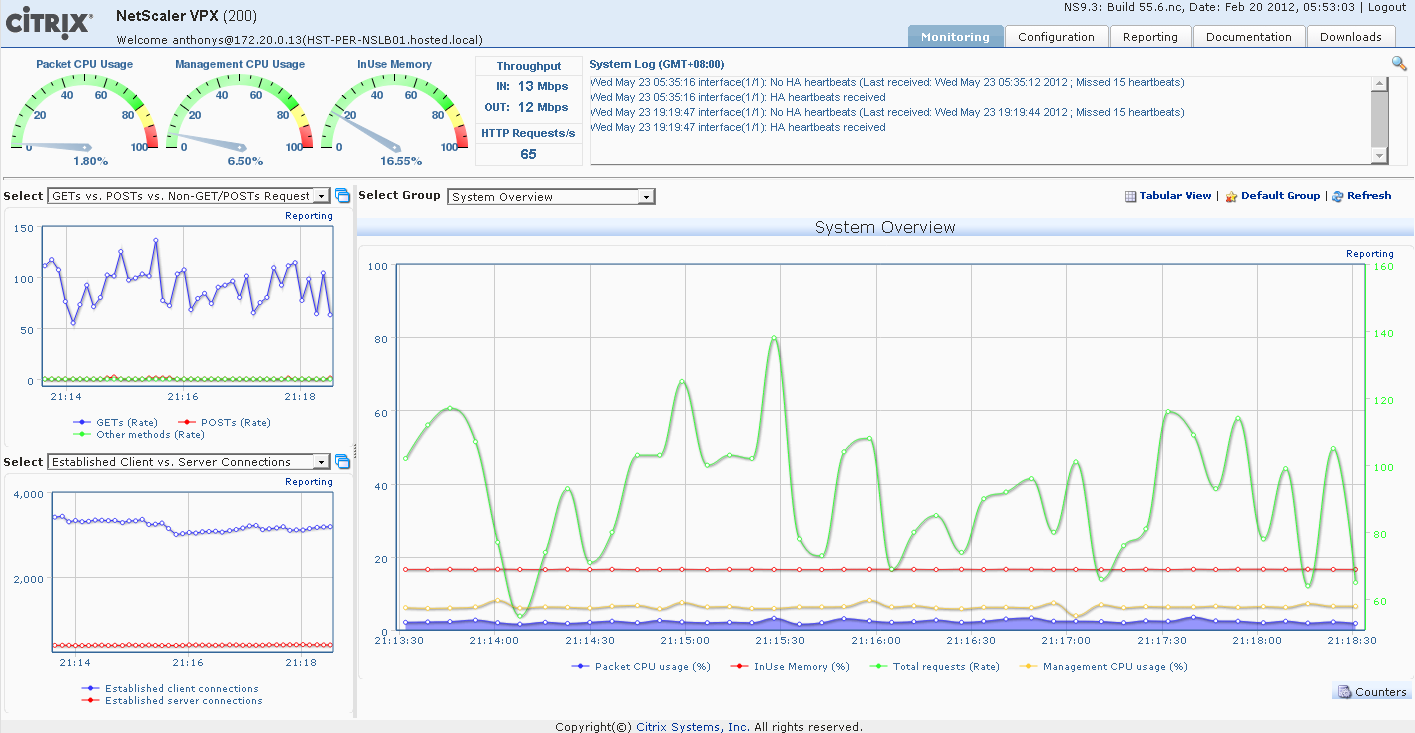
Ive come across a couple of how-to's on configuring vCloud Cells in a highly available Load Balanced environment. There is a good overview here by @hany_mich...
A little after vCenter Operations Manager 5.0 went GA I posted this forum thread in regards to the default time-out value of the Web UI...Thanks to ILIO and ...
If you had asked me 2 years ago that I'd be writing as a VMware vExpert I would have thought you were crazy. At that stage my only exposure to VMware was on ...