More Than Meets the Eye... Veeam Backup Performance
Recently I was sent a link to a video that showed an end user comparing Veeam to a competitors offering covering backup performance, restore capabilities and UI. It mainly focused on the comparison of incremental backup jobs and their completion times. It showed that the Veeam job was taking a significantly longer time to complete for the same dataset. The comparison was chalk and cheese and didn’t paint Veeam in a very good light.
Now, without knowing 100% the backend configuration that the user was testing against or the configuration of the Veeam components, storage platforms and backup jobs vs the competitors setup…the discrepancy between both job completion times was too great and something had to be amiss. This was not an apples to apples comparison.
TL:DR - I was able to cut the time to complete an incremental backup job from 24 minutes to under 4 minutes by scaling out Veeam infrastructure components and tweaking transport mode options to suit the dataset from using the default configuration settings and server setup. Lesson being to not take inferred performance at face value, there are a lot of factors that go into backup speed.
Before I continue, it’s important for me to state that I have seen Veeam perform exceptionally well under a number of different scenarios and know from my own experience at my previous roles at large service providers that it can handle 1000s of VMs and scale up to handle larger environments. That said, like any environment you need to understand how to properly scope and size backup components to suite…that includes more than just the backup server and veeam components… storage obviously plays a huge role in backup performance as does the design of the virtualisation platform as well as networking.
I haven’t set out in this post to put together a guide on how to scale Veeam…rather I have focused on trying to debunk the differential in job completion time I saw in the video. I went into my lab and started to think about how scaling Veeam components and choosing different options for backups and proxies can hugely impact the time it takes for backup jobs to complete. For the testing I used a Veeam Backup & Replication server that I had deployed with the Update 4 release and had active jobs that where in operation for more than a month.
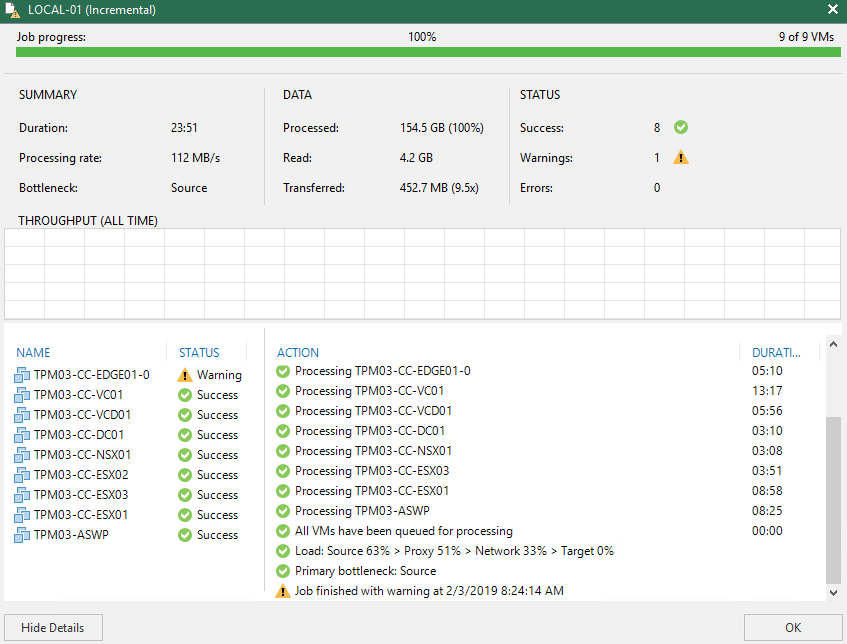
The Veeam Backup & Replication server is on a VMware Virtual Machine running on modest 2vCPU and 8GB of RAM. Initially I had this running as an all in one Backup Server and Proxy setup. I have a SOBR repository consisting of two ReFS formatted local VMDK (underlying storage is vSAN) extents and a Capacity Tier extent going to Amazon S3. The backup job consisted of nine VMs with a footprint of about 162GB. A small dataset but one which was based of real world workloads. The job was running Forward Incremental, keeping 14 restore points running every 4 hours with a Synthetic Full running every 24 hours (initial purpose of was to demo Cloud Tier) and on average the incremental’s where taking between 23 to 25 minutes to complete.
The time to complete the incremental job was not an issue for me in the lab, but it provided a good opportunity to test out what would happen if I looked to scale out the Veeam components and tweak the default configuration settings.
Adding Proxies
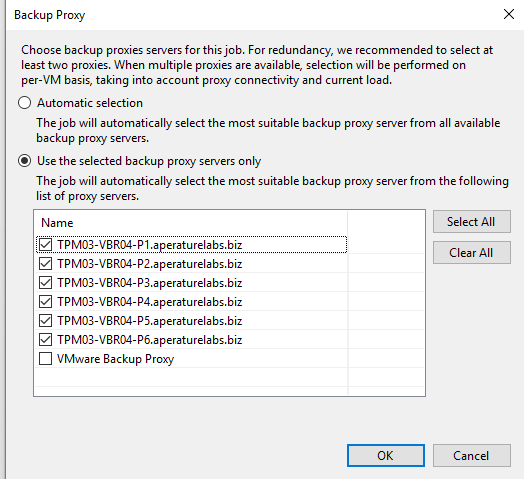
As a first step I deployed three virtual (https://bp.veeam.expert/proxy_servers_intro/proxy_server_vmware-vsphere) (2vCPU and 4GB RAM) into the environment and configured the job to use them in (https://bp.veeam.expert/proxy_servers_intro/proxy_server_vmware-vsphere/transport_modes/virtual_appliance_mode). Right away the job time decreased down by ~50% to 12 minutes. Basically, more proxies means more disks are able to be processed in parallel when in hot-add mode so it’s logical that the speed of the backup would increase.
Adding More Proxies
As a second step I deployed three more proxies into the environment and configured the job to use all six in hot-add mode. This didn’t result in a significantly faster time to what it was at three proxies, but again, this will vary depending on the amount of VMs and size of those VMs disks in a job. Again, Veeam offers the flexibility to scale and grow with the environment. This is not a one size fits all approach and you are not locked into a particular appliance size that may max out requiring additional significant spend.
Change Transport Mode
Next I changed the job back to use three proxies, but this time I forced the proxies to use (https://bp.veeam.expert/proxy_servers_intro/proxy_server_vmware-vsphere/transport_modes/network_mode). To read more about Transport modes, head (https://bp.veeam.expert/proxy_servers_intro/proxy_server_vmware-vsphere/transport_modes).
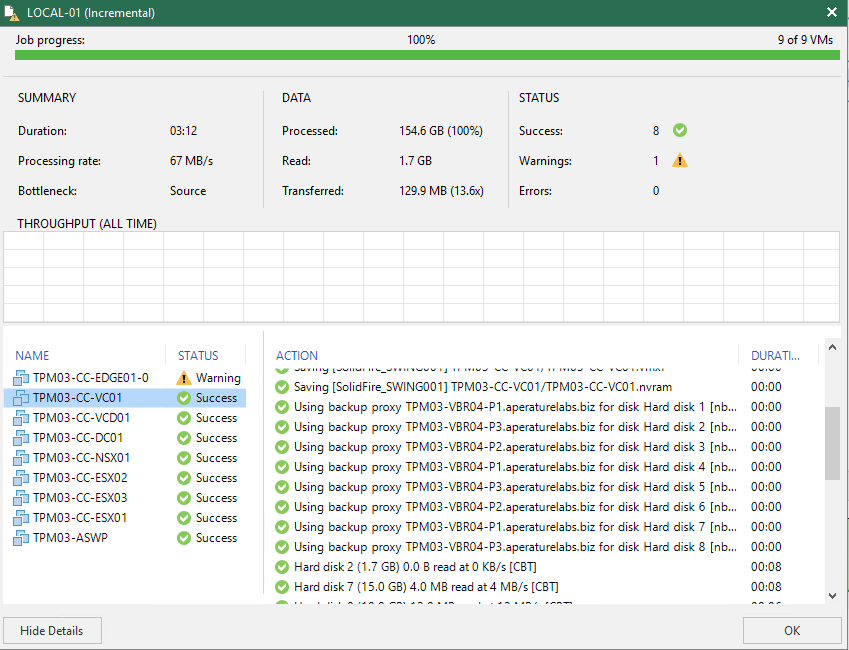
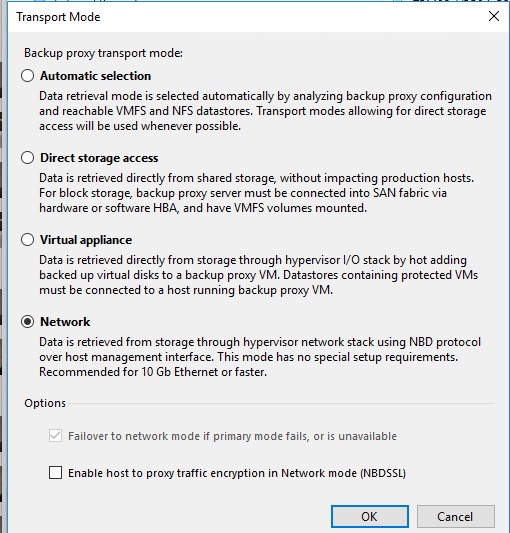 This resulted in a sub 4 minute job completion to read a similar incremental data set as the previous runs. A ~20 minute difference after just a few tweaks of the configuration!
This resulted in a sub 4 minute job completion to read a similar incremental data set as the previous runs. A ~20 minute difference after just a few tweaks of the configuration!
Removing Surplus Proxies and Balancing Things Out
For the example above I introduced proxies however the right balance of proxies and network mode was the most optimal configuration for this particular job in order to lower the job completion window. In fact in my last test I was able to get the job to complete consistently around the 5 minute mark by just using the one proxy with network mode.
Conclusion:
So with that, you can see that by tweaking some settings and scaling out Veeam components I was able to bring a job completion time down by more than 20 minutes. Veeam offers the flexibility to scale and grow with any environment. This is not a one size fits all approach and you are not locked into a particular appliance size that will scale out requiring additional and significant spend while also locking you in by way of restricted backup date portability**.** Again, this is just a quick example of what can be done with the flexibility of the Veeam platform and that what you see as a default out of the box experience (or a poorly configured/problematic environment) isn’t what should be expected for all use cases. Milage will vary…but don’t let first/misleading impressions sway you…there is always more than meets the eye! Sources: https://bp.veeam.expert/