
ESXi 5.5: IOPS Limit and mClock scheduler
It’s fair to say that it’s not very often the difference between a 1 and 0 can have such a massive impact on performance…I had read a couple of posts from Duncan Epping in regards to a new DiskIO Schedular introduced in ESXi 5.5 and what it meant for VM Disk Limits compared to how things where done in previous 5.x versions of ESXi.
As mentioned in the posts linked above the ESxi Host Advanced Setting Disk.SchedulerWithReservation is activated by default in ESXi 5.5, so without warning in an upgrade scenario where IOPS limits are used the rules change…and from I found out last night the results are not pretty.
The graphic above is showing the total latency of a VM (On an NFS datastore with an IOPS limit set) running firstly on ESXi 5.1 up until the first arrow when the VM was vMotioned to an in place upgraded host now running ESXi 5.5 Update 2. As soon as the VM lands on the 5.5 host latency skyrockets and remains high until there is another vMotion to another 5.5 host. Interestingly enough the overall latency on the other host isn’t as high as the first but grows in a linear fashion.
The second arrow represents the removal of the IOPS Limits at which point latency falls to its lowest levels in the past 24 hours. The final arrows represents a test where the IOPS Limits was reapplied and the advanced setting Disk.SchedulerWithReservation was set to 0 on the host.
To make sense of the above it seems that the mClock Scheduler being on caused the applied IOPS Limit to generate artificial latency against the VM rendering it pretty much useless. The reasons for this are unknown at this point, but in reading Duncan’s blog on the IOPS Limit Caveat it would seem that due to the new 5.5 mClock Scheduler looking at application level block sizes to work out the IO the applied limit actually crippled the VM. In this case the limit was set to 250 IOPS, so I am wondering if there is some unexpected behaviour happening here even if larger block sizes are being used in the VM.
Suffice to say it looks like the smart thing to be doing is set the Disk.SchedulerWithReservation to 0 and revert back to 5.0/1 behaviour with IOPS Limits in place. If you want to do that on bulk the following PowerCLI command will do the trick.
get-cluster CLUSTERNAME | get-VMhost | get-AdvancedSetting -Name Disk.SchedulerWithReservation | Set-AdvancedS
etting -Value 0 -Confirm:$falseOne more interesting observation I made is that it appears VMs with IOPS limits on iSCSI datastores are not/less effected…however most large NFS datastores with a large number of VMs where. You can see below what happens to datastore latency when I switched off the mClock Scheduler…latency dropped instantly.
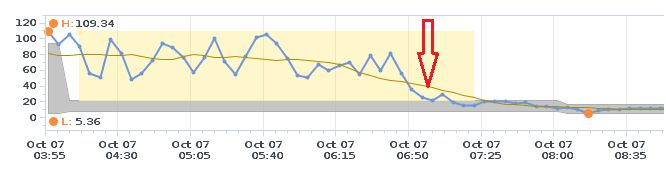 I’m not sure if this indicates more general NFS issues with ESXi 5.5…there seems to have been more than a few since Update 1 came out. I’ve reached out to see if this behaviour can be explained so hopefully I can provide an update when that information comes to hand…again, I’m not too sure what the benefit of this change in behaviour is so I’m hoping someone who has managed to digest the Brain Hurting Academic Paper to explain why this was introduced.
In laymen’s terms…an IO is not an IO in the world of VM IOPS Limits anymore.
I’m not sure if this indicates more general NFS issues with ESXi 5.5…there seems to have been more than a few since Update 1 came out. I’ve reached out to see if this behaviour can be explained so hopefully I can provide an update when that information comes to hand…again, I’m not too sure what the benefit of this change in behaviour is so I’m hoping someone who has managed to digest the Brain Hurting Academic Paper to explain why this was introduced.
In laymen’s terms…an IO is not an IO in the world of VM IOPS Limits anymore.
4 Commentsarchived