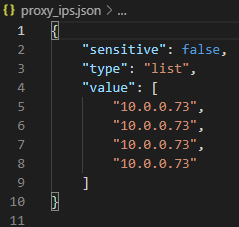
Quick Fix: Deploying Multiple Ubuntu 18.04 VMs From Template with DHCP Results Same in IP Allocation
In the continuing work I've been doing with Terraform, i've come across a number of gotchyas when working with VM Templates and deploying them on mass. The n...