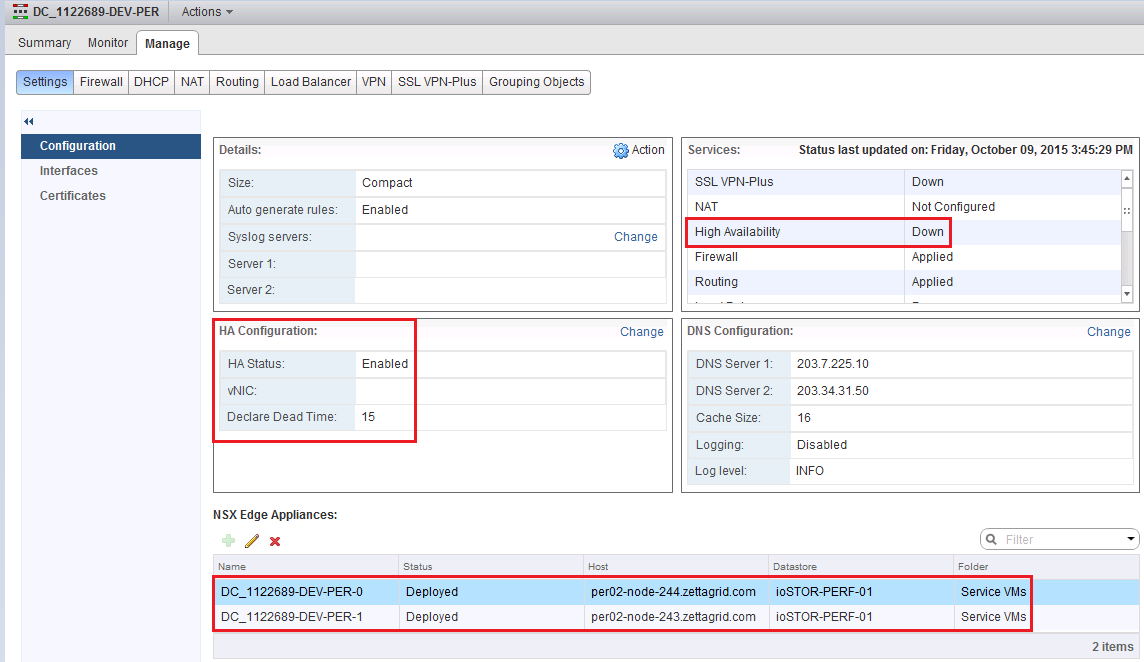
NSX Bytes: NSX Edge - High Availability Status Down
In doing some testing around NSX Edge deployment scenarios I came across a small quirk in the High Availability Config for the NSX Edge Gateway where by afte...
Tag
2 posts
In doing some testing around NSX Edge deployment scenarios I came across a small quirk in the High Availability Config for the NSX Edge Gateway where by afte...
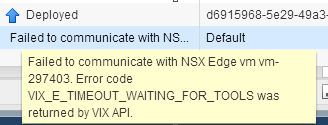
Had a situation pop up today where an NSX Edge needed to be moved from it's current location to another location due to an initial VM placement issue. The VM...