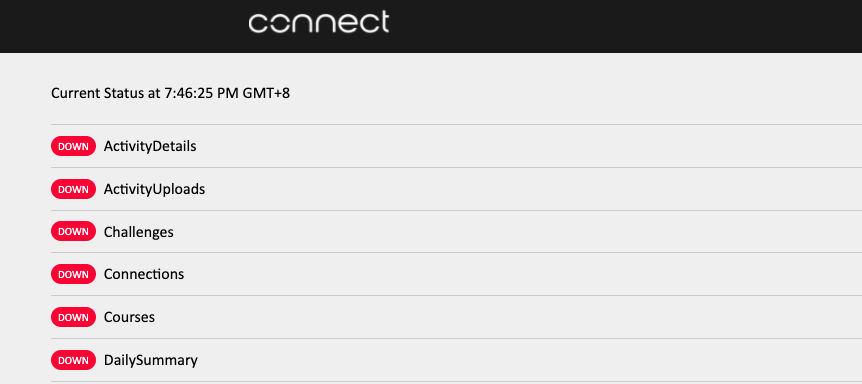
Garmin Down! - Dumbing Down Smart Devices Changes The Way We See IoT
Artificial intelligence, machine learning and the internet of things have been hot topics for any digital transformation discussion in recent years. It’s no ...
Tag
3 posts
Artificial intelligence, machine learning and the internet of things have been hot topics for any digital transformation discussion in recent years. It’s no ...
As recent events have shown, outages and disasters are a fact of life in this modern world. Given the number of different platforms that data sits on today, ...

It's been a bad couple of weeks for cloud services both around the world and locally...Over the last three days we have seen AWS have issues which may have b...