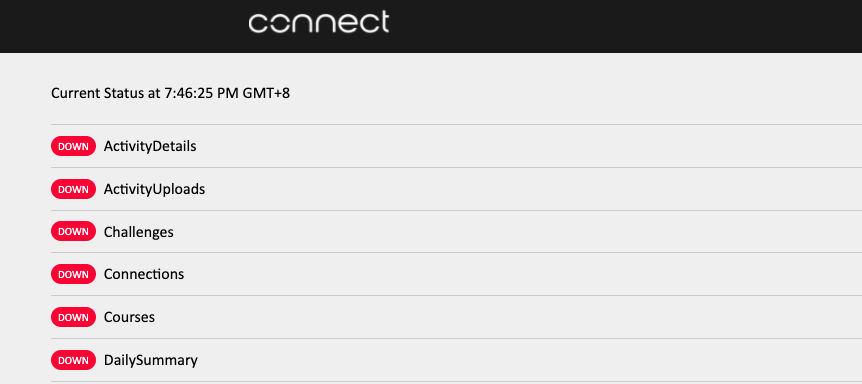
Garmin Down! - Dumbing Down Smart Devices Changes The Way We See IoT
Artificial intelligence, machine learning and the internet of things have been hot topics for any digital transformation discussion in recent years. It’s no surprise. The IT industry is obsessed with what the future has in store. As technologists, it’s important to continue to drive conversations about where the industry is going and what the next big technology breakthrough will be. We saw this with cloud computing through the 2000s and into the 2010s, but only in recent years has the buzz translated into mainstream usage to the point where we no longer talk about cloud computing as the “next big thing”. As refreshing as that is, in reality, discussions of new and emerging tech tend to be driven by hype.
For those unfamiliar with the Gartner Hype Cycle, it is an excellent visual representation of how the industry picks up on trends.
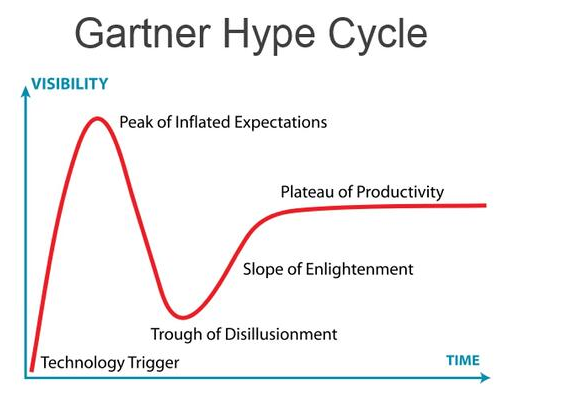
The Hype Cycle details the evolution of these trends until, like cloud computing, they either become accepted as the norm, fall off the industry radar (OpenStack anyone?) or are discussed at every mainstream conference and digital transformation talk until people become disillusioned with the topic.
IoT has the potential to become one of those topics. There have been some interesting talks recently on how the dumbing down of otherwise smart devices hurts the perception and seriousness of what it is to actually consume IoT in our daily lives. In reality, when you strip back the hype you are left with some pretty standard technologies that work to deliver these IoT services.
Every IoT service is backed by an application hosted on a server, but what does trivialising these devices do to our perception of data criticality?
A casual approach to protecting IoT data
Taking wearable activity trackers as an example. There is no doubt these are classified as IoT devices. They monitor steps, heartbeat, exercise activities, weight and sleep patterns – all while also telling the time. They store data locally before it has an opportunity to sync with the application on your smartphone, which in turn uploads all that data to a web service somewhere in the world. To talk about these as internet-connected devices generating critical data points that we rely on is not far off the truth. This data is important to the individual, but insufficient thought is given to what happens if it is lost? What control do users have to access this data at any given point? The reality is there are no regulations in place that allow the end user to autonomously ensure data of this kind is secure. If the data became unavailable tomorrow, more than likely, there would be nothing the user could do about it. With Garmin currently in the middle of what seems like a major outage, it highlights the fact that all data generated at the edge or on IoT devices can be seen to be critical for someone…but we don’t think about it until we don’t have it.
All data needs protecting
Compromise of wearable device data probably would not have a significant impact on the user’s day-to-day life. The criticality of that data is low, so the end user would not be impacted financially or otherwise. When we extend this example to more critical online services that collect data, the impact of data breach or loss of data becomes more impactful. You only have to look at the Facebook and Cambridge Analytica data leaks to see how serious data ownership is and what happens when data is used for purposes other than for what it originally intended. So why do we see some data as more worth protecting than others? Increasingly online platforms are allowing end users to access their data and it is the responsibility of the customer to take ownership into their own hands. Wearable devices might contain only low-level data, but this is still data that is personal to user. It contains email address, payment details, location and, more worryingly, personal health data. As this Garmin outage highlights… what seems like non-critical data is actually valuable for some… and crucial for others!