
v12 RTM Is Out...With Enhanced DRaaS, Direct to Object Storage and more!
Today, Veeam made available to our VCSP partners the RTM of Veeam Backup & Replication 12 (Build 12.0.0.1402). It actually feels like it's been a while betwe...
Tag
8 posts
Today, Veeam made available to our VCSP partners the RTM of Veeam Backup & Replication 12 (Build 12.0.0.1402). It actually feels like it's been a while betwe...
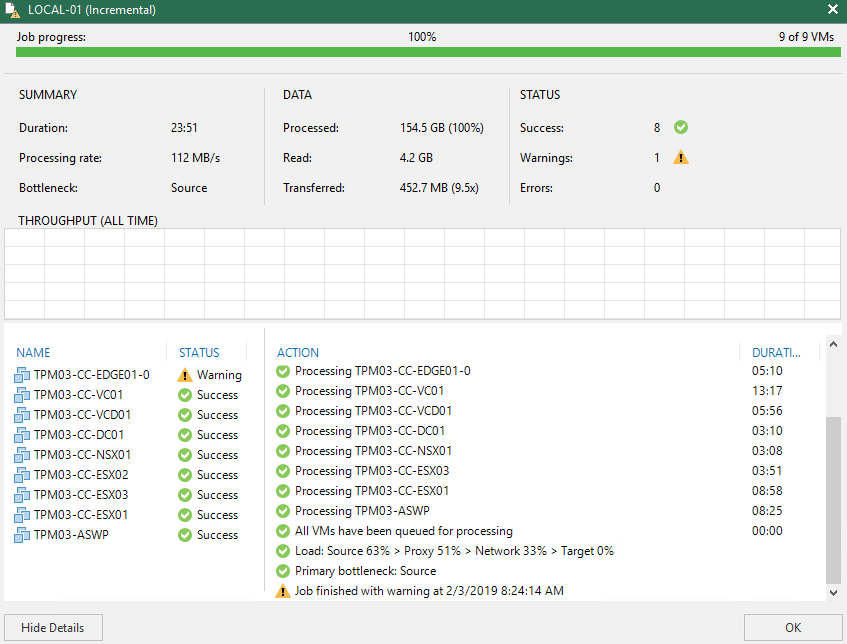
Recently I was sent a link to a video that showed an end user comparing Veeam to a competitors offering covering backup performance, restore capabilities and...
I originally came across the issue of slow storage performance with the native vmw_ahci driver that comes bundled with ESXi 6.5 just as I was first playing w...
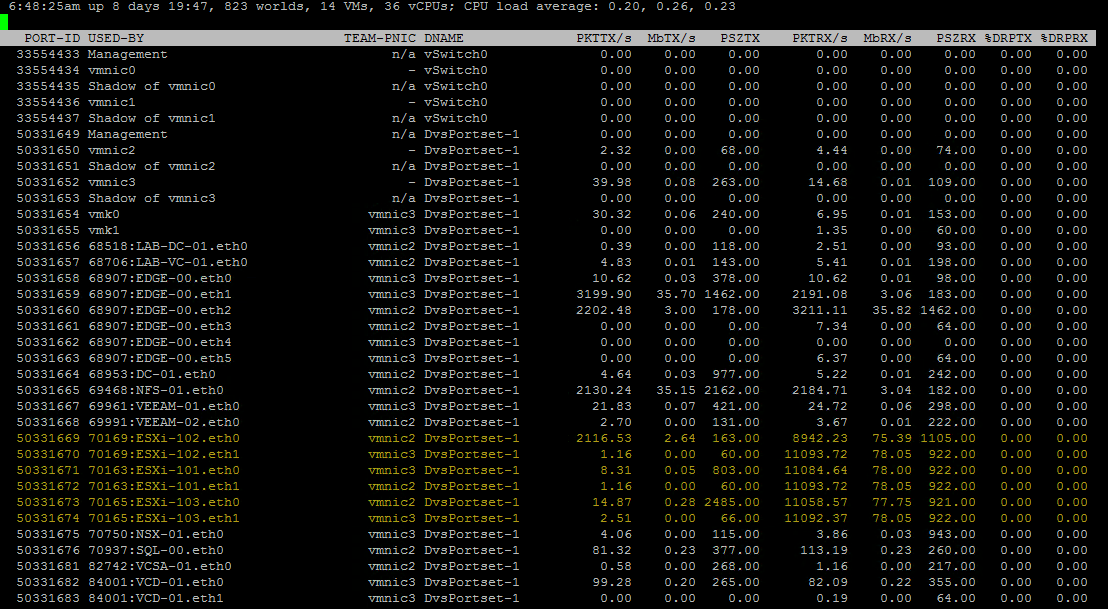
I've been running my NestedESXi homelab for about eight months now but in all that time I had not installed or enabled the ESXi MAC Learning dvFilter . As a ...
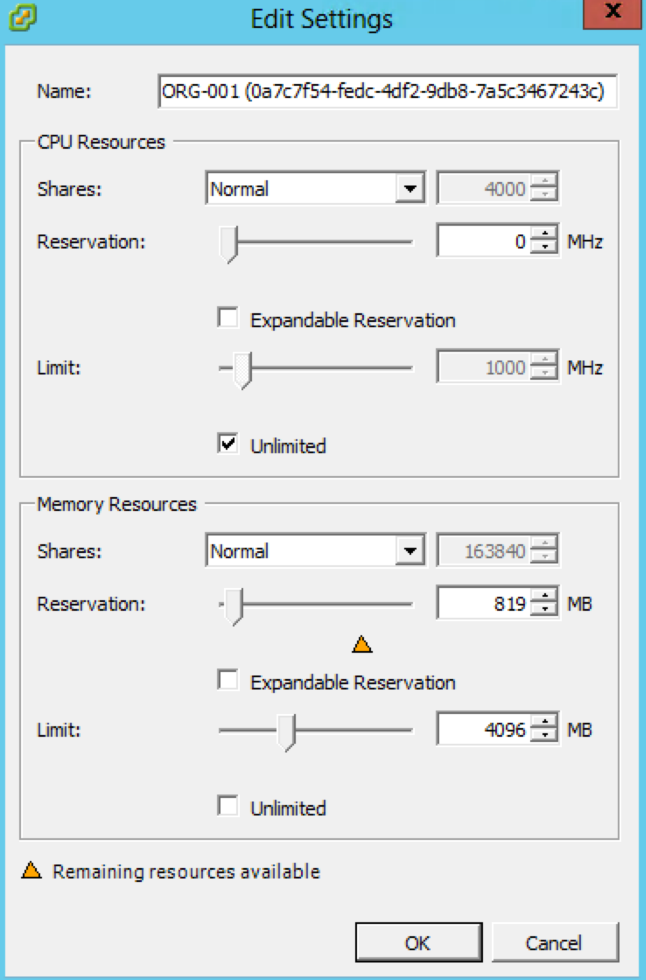
For the longest time all VMware administrators have been told that resource pools are not folders and that they should only be used under circumstances where...

[ NOTE ] : I decided to republish this post with a new heading and skip right to the meat of the issue as I've had a lot of people reach out saying that the ...
Ok, i'll admit it...i've had serious lab withdrawals since having to give up the awesome Zettagrid Labs. Having a lab to tinker with goes hand in hand with b...
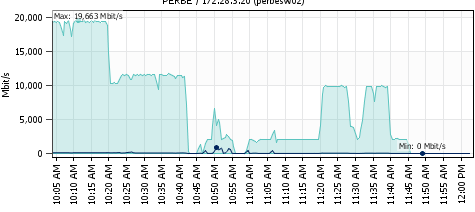
We have been conducting performance and stress testing of a new NFS connected storage platform over the past month or so and through that testing we have see...