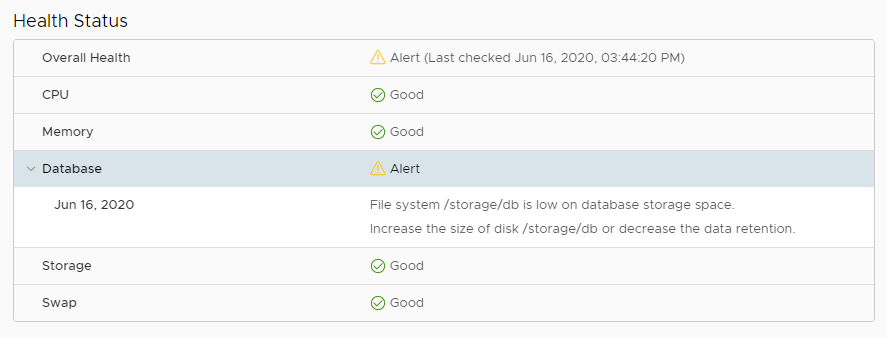
Quick Fix - VCSA Low DB Storage Space Warning
I had a situation earlier this week where the VMware SDK/API service was being reported as offline. I was triggered by some failed backup jobs which made me ...
Category
11 posts
I had a situation earlier this week where the VMware SDK/API service was being reported as offline. I was triggered by some failed backup jobs which made me ...
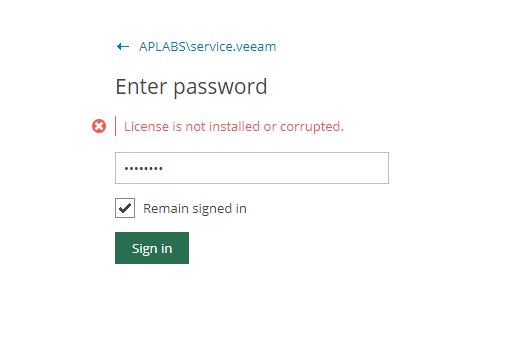
Had a situation today whereI needed to update the license for one of my Veeam Enterprise Manager isntances due to using ones from previous internal builds. M...
Multi Factor Authentication is pretty much standard now when it comes to accessing online accounts and most companies have implemented MFA for their employee...
vCloud Director 9.0, released last week has a bunch of new enhancements and a lot of those are focused around it's integration with NSX. Tom Fojta has a what...
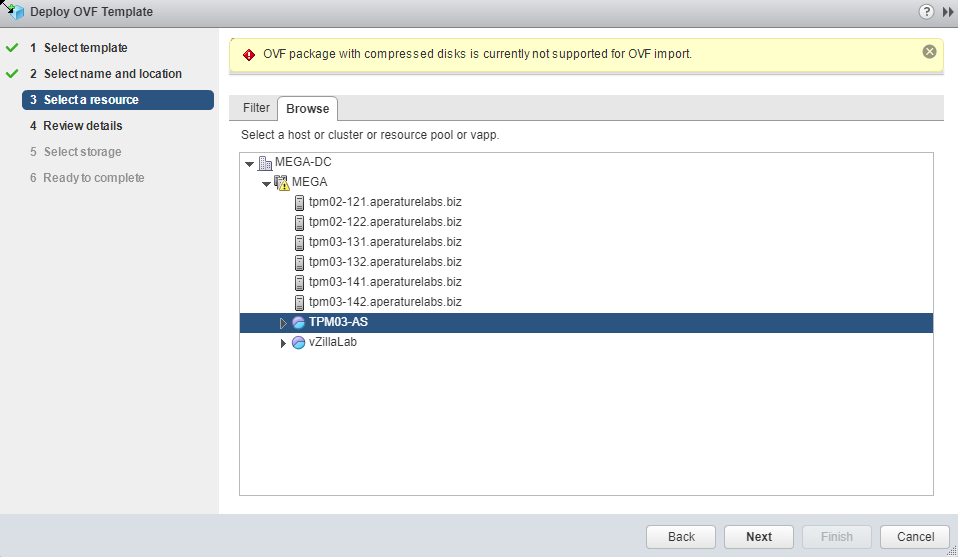
A couple of weeks ago I ran into an issue stopping me from importing an OVA and today I came across another issue relating to the Web Client not able to impo...
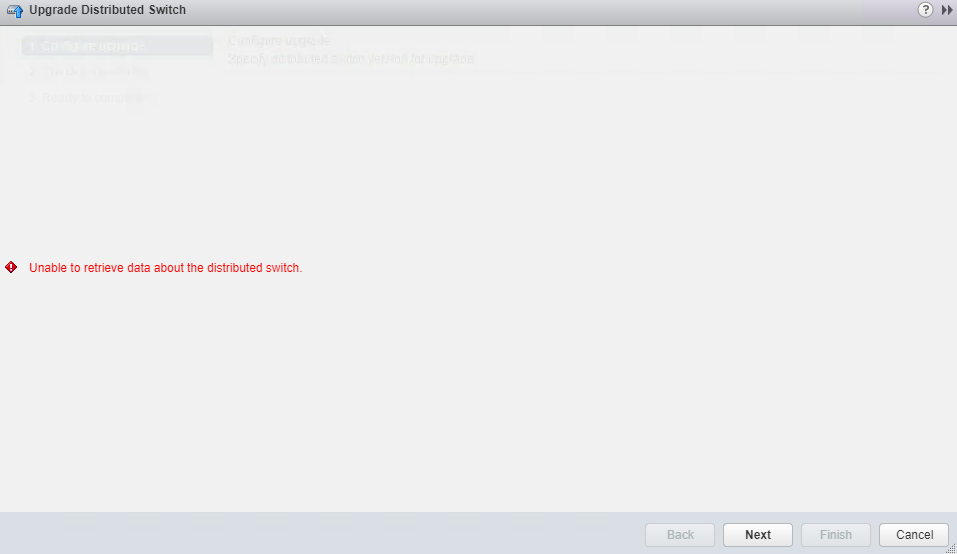
This week I upgraded (and migrated) my SliemaLabs NestedESXi vCenter from a Windows 6.0 server to a 6.5 VCSA ...everything went well, but ran into an issue w...
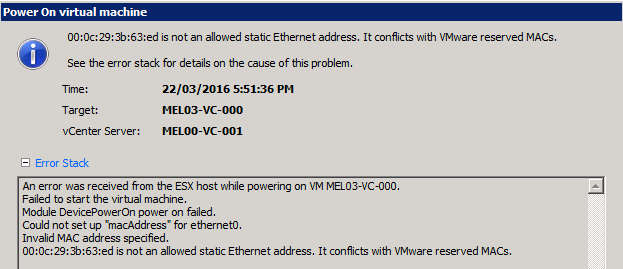
The old changing of the MAC address causing NIC/IP issues has raised it's ugly head again...this time during a planned migration of one of our VCSA from one ...
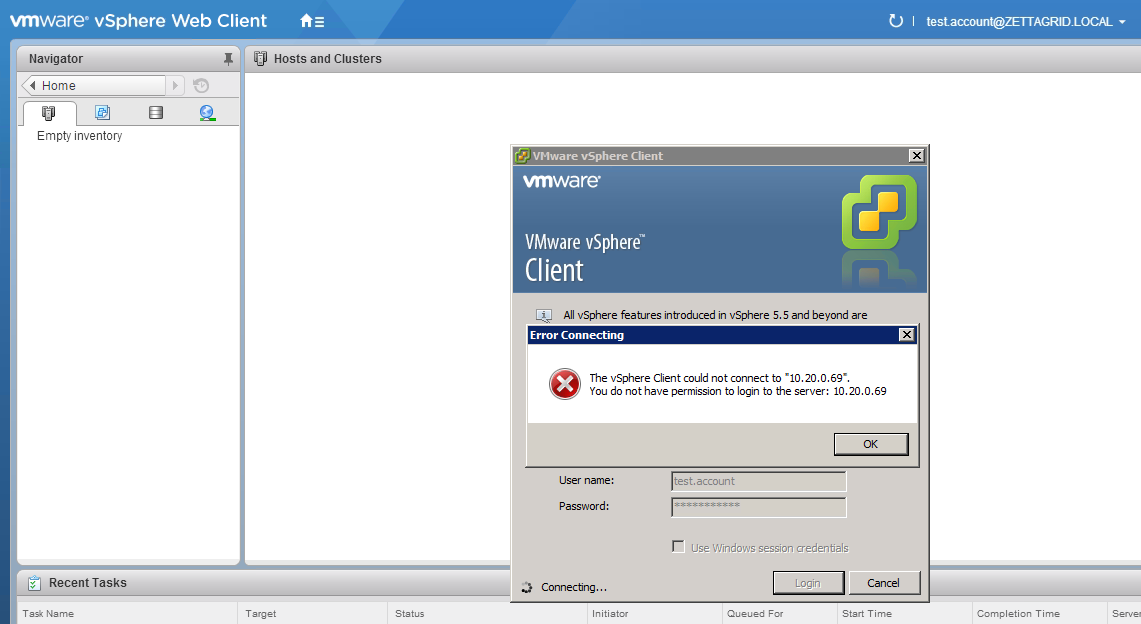
I've been using the VCSA for a couple of years now since the release of vSphere 5.5 and have been happily using the upgraded 6.0 version for a couple of my e...
REMOVING DEAD PATHS IN ESX4.1 (version 5 guidance here ) Very quick post in relation to a slightly sticky situation I found myself in this afternoon. I was ...
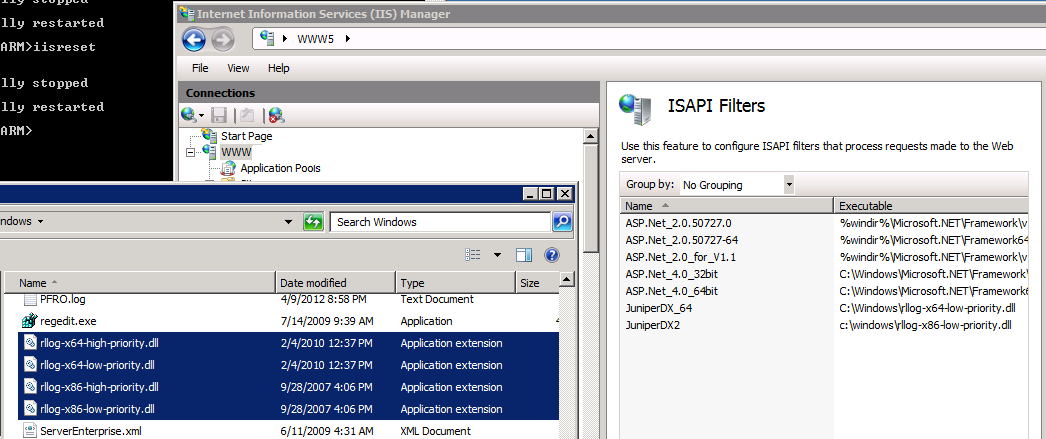
If you are NAT'ing public to private addresses with a load balancer in between your web server and your Gateway/FireWall device you might come across the sit...
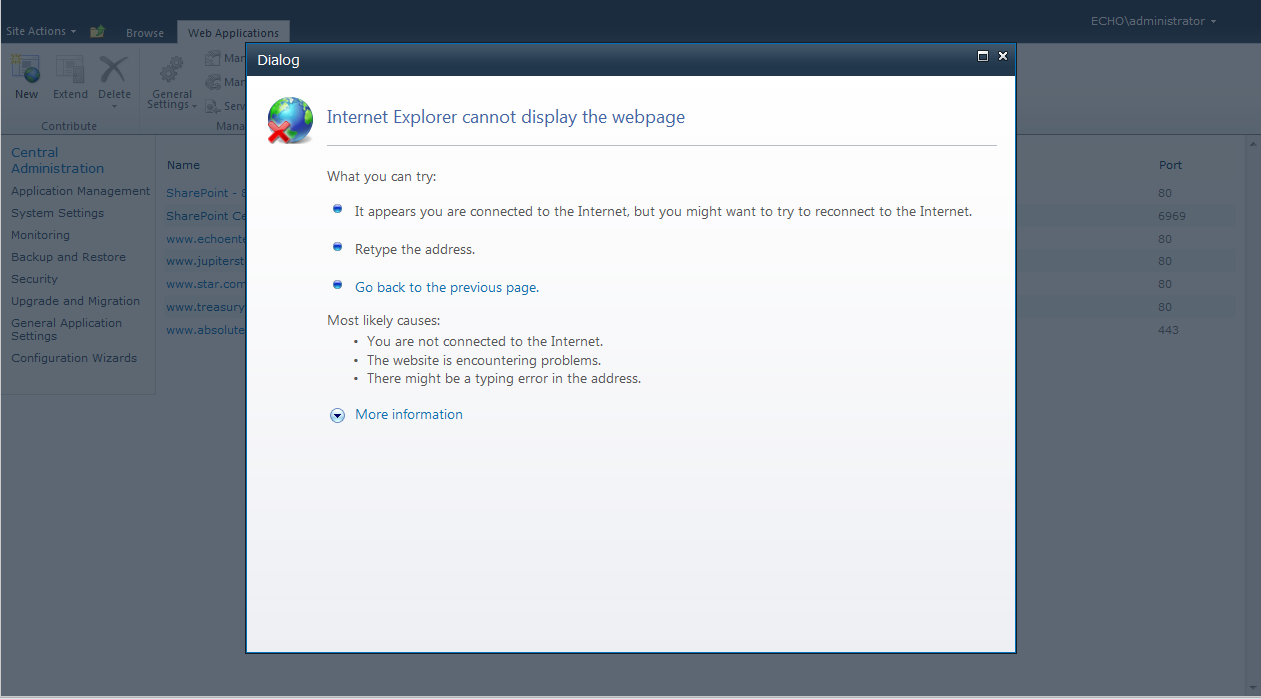
Had a really interesting issue with a large SharePoint Farm instance we host... over the last couple of days when we tried to create a new Web Application th...