Quick Fix - VCSA Low DB Storage Space Warning
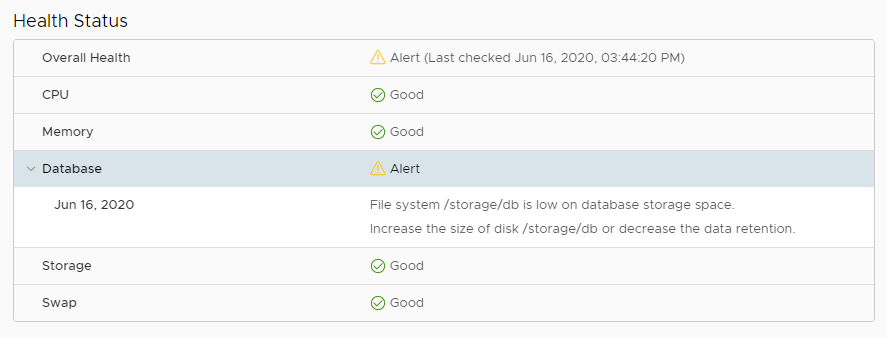
I had a situation earlier this week where the VMware SDK/API service was being reported as offline. I was triggered by some failed backup jobs which made me check to see what could be causing the problem. Logging into the VCSA Management UI, I was presented with the following warning in the Health Status.
File System /storage/db is low on database storage space. Increase the size of the disk /storage/db or decrease the data retention.
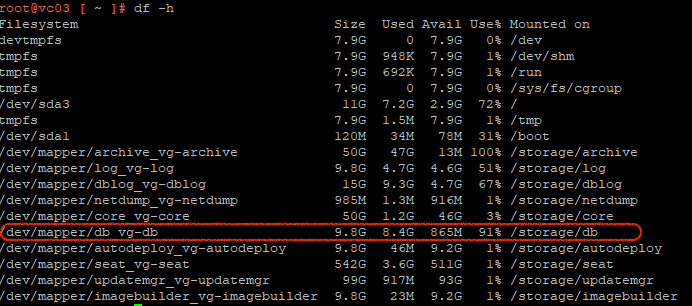
First thing is to locate and identify the correct disk/VMDK that needs checking and ultimately resizing. To do that, you need to log into the VCSA CLI and drop into the shell. A df -h will give you a list of the file systems on the VCSA. From there we need to locate the /storage/db mount as listed in the warning. As can be seen below, the warning was in place with the usage of that mount at 91%
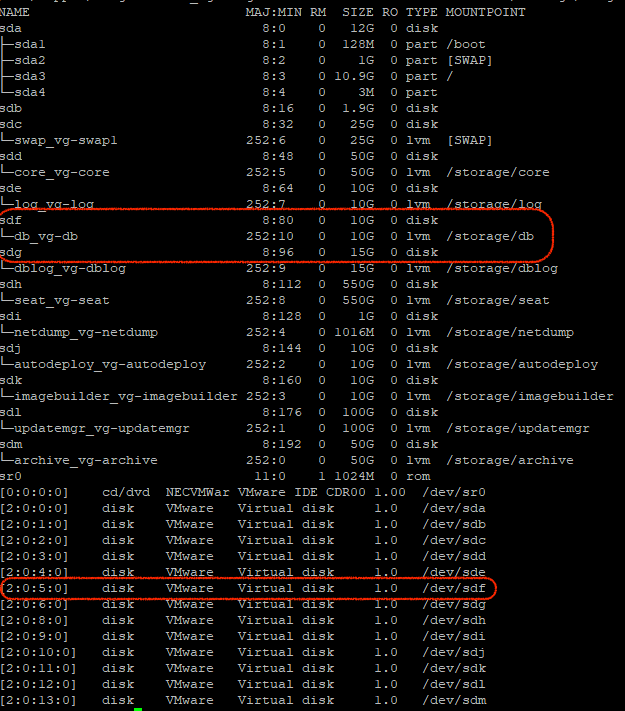
 From here, we need to work out the SCSI ID of the partition so that we can expand the correct disk. There are 13 VMDKs on this VCSA and there are multiple ones that are 10GB in size, so to get a little more targeted, we need to work out the device id (sdf in this case) and then the disk ID (2:0:5:0) as shown below.
From here, we need to work out the SCSI ID of the partition so that we can expand the correct disk. There are 13 VMDKs on this VCSA and there are multiple ones that are 10GB in size, so to get a little more targeted, we need to work out the device id (sdf in this case) and then the disk ID (2:0:5:0) as shown below.
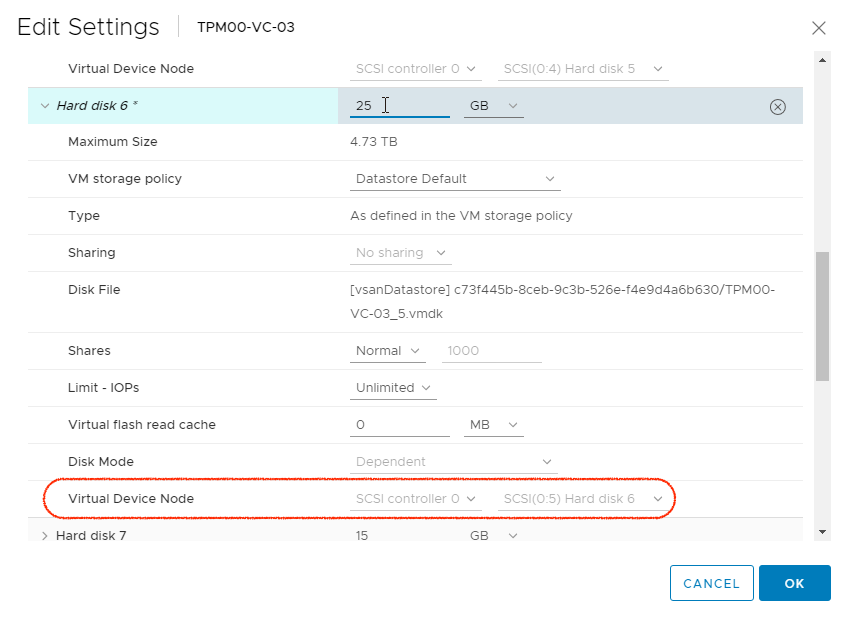
 With this done, we need to head to the vCenter where the VCSA Virtual Machine is located and edit the VM Settings. As can be seen today, we need to match the third number in the above ID to the SCSI ID in vCenter. In this case we are looking at SCSI(0:5) Hard Disk 6 and as you can see i’ve expanded the disk from 10GB to 25GB just to give some additional future headroom.
With this done, we need to head to the vCenter where the VCSA Virtual Machine is located and edit the VM Settings. As can be seen today, we need to match the third number in the above ID to the SCSI ID in vCenter. In this case we are looking at SCSI(0:5) Hard Disk 6 and as you can see i’ve expanded the disk from 10GB to 25GB just to give some additional future headroom.
 Once that has been done, returning to the VCSA CLI Shell, we can run the command below to expand the partition:
Once that has been done, returning to the VCSA CLI Shell, we can run the command below to expand the partition:
/usr/lib/applmgmt/support/scripts/autogrow.sh
This script looks for changes in the underlying storage and expands the volume without the need to reboot. Once that has been run, in this case the volume db_vg/db has been extended.
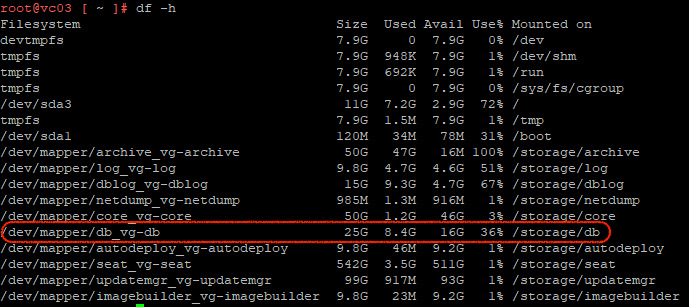
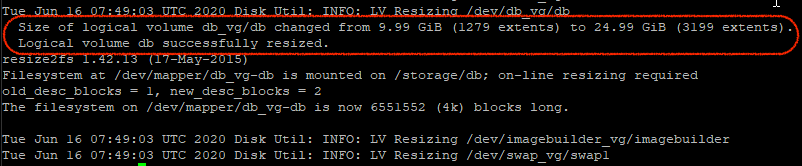 Once that has been done, if we run df -h again, the /storage/db usage will be less relative to the amount increased. As can been seen below that’s now 36%.
Once that has been done, if we run df -h again, the /storage/db usage will be less relative to the amount increased. As can been seen below that’s now 36%.
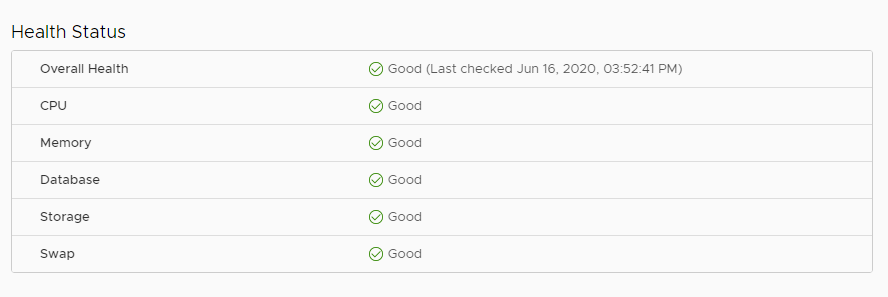
 After about two to five minutes the VCSA will report that the Health Status is all clear and green and we are back to normal operating conditions. For good measure, because I knew there was a service issue, I gave the vCenter a reboot as well.
After about two to five minutes the VCSA will report that the Health Status is all clear and green and we are back to normal operating conditions. For good measure, because I knew there was a service issue, I gave the vCenter a reboot as well.
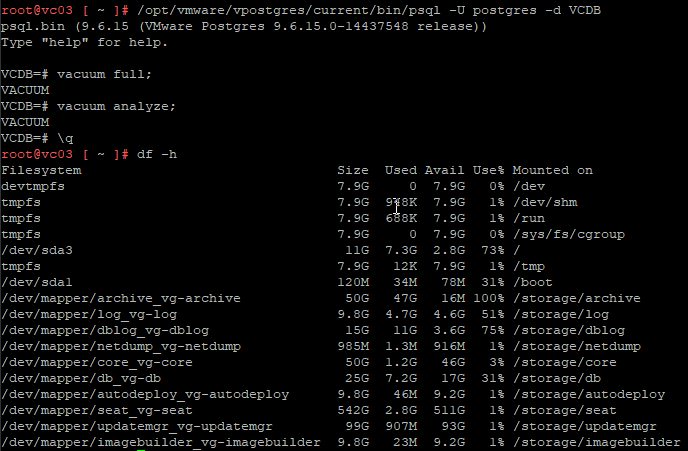
 As an FYI, an additional thing that I did was do what is called a vacuum. This is an additional task that can be run against the VCSA database that cleans up any bloat in the tables. As can be seen below, I was able to reclaim about 4% of diskspace after it was run.
As an FYI, an additional thing that I did was do what is called a vacuum. This is an additional task that can be run against the VCSA database that cleans up any bloat in the tables. As can be seen below, I was able to reclaim about 4% of diskspace after it was run.
 References:
https://kb.vmware.com/s/article/51981
https://kb.vmware.com/s/article/2145603
References:
https://kb.vmware.com/s/article/51981
https://kb.vmware.com/s/article/2145603