
Infrastructure as Code SaaS Based Automation with env0
Those reading my blog and social feeds over the last few years know how much of a fan of automation and infrastructure as code I am. I never profess or claim...
Category
16 posts
Those reading my blog and social feeds over the last few years know how much of a fan of automation and infrastructure as code I am. I never profess or claim...
HashiConf took place a couple of weeks ago now, and during the event I presented a community based Lightning Talk live. The session is based on using Infrast...

HashiConf Digital gets underway shortly and will offer two days of product reveals, technical sessions and Lightning Talks attracting a huge number of attend...

HashiConf Digital gets underway shortly and will offer three days of technical sessions and workshops attracting an estimated 6000 attendees from around the ...
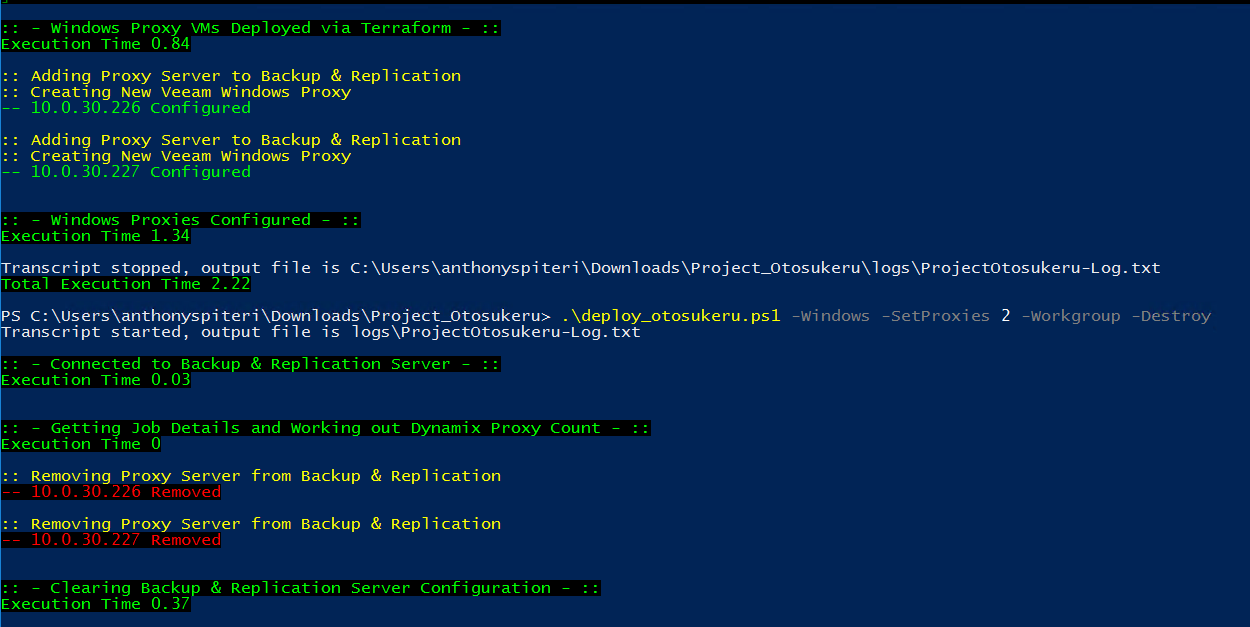
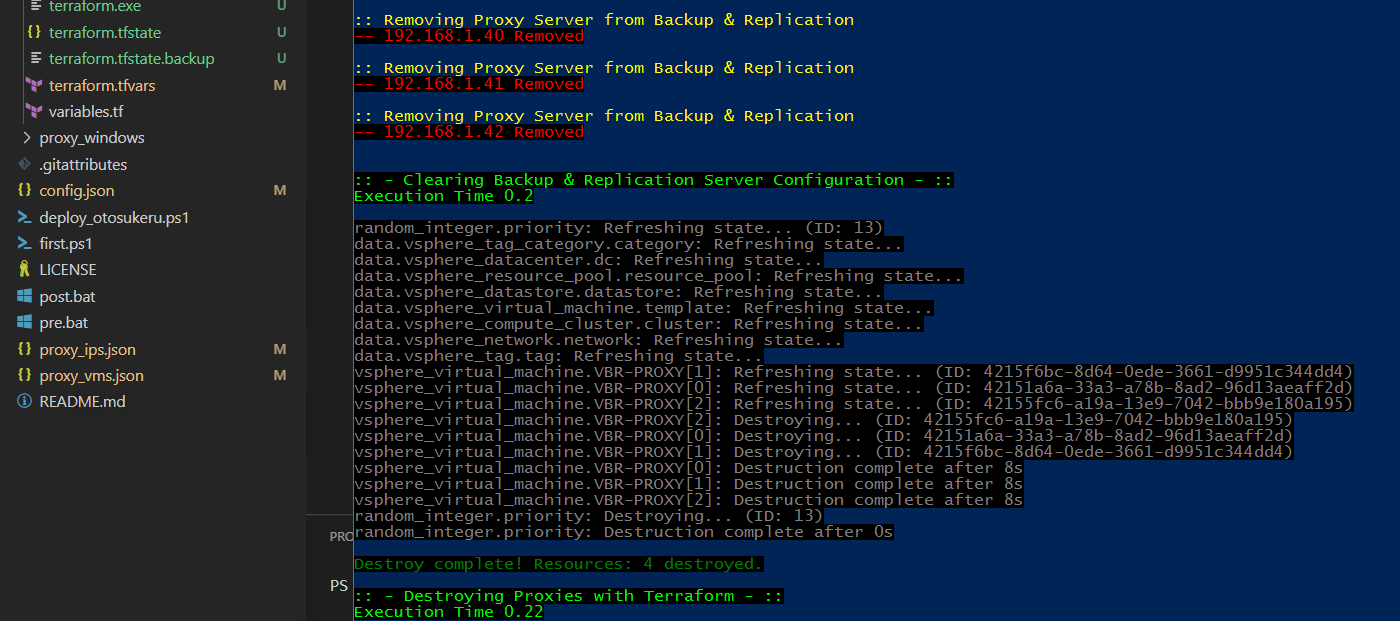
My recent obsession with automation and Infrastructure as Code in general has resulted in a lot of efficiencies in my day to day work life. Where I used to d...
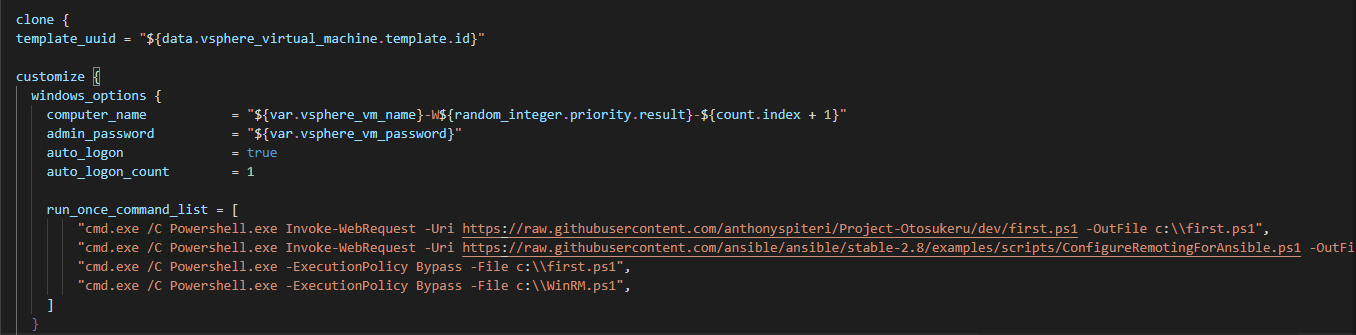
Bootstrapping Windows during automated deployments is one of the more frustrating aspects of working with templates that are being deployed by Infrastructure...
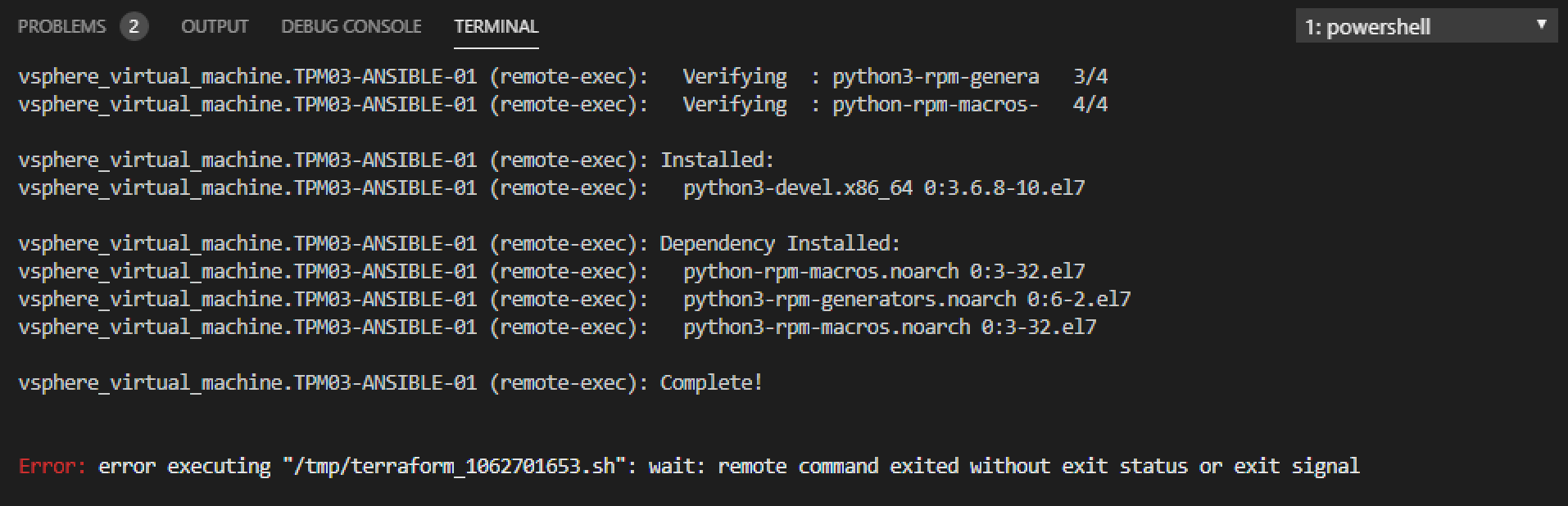
When deploying and configuring Linux as part of my Terraform plans, I have generally used a combination of script based or in-line Remote-Exec declarations t...

In the continuing spirit of Terraforming all things, when I started to look into Ansible I wanted a way to have the base Control Node installed in a repeatab...
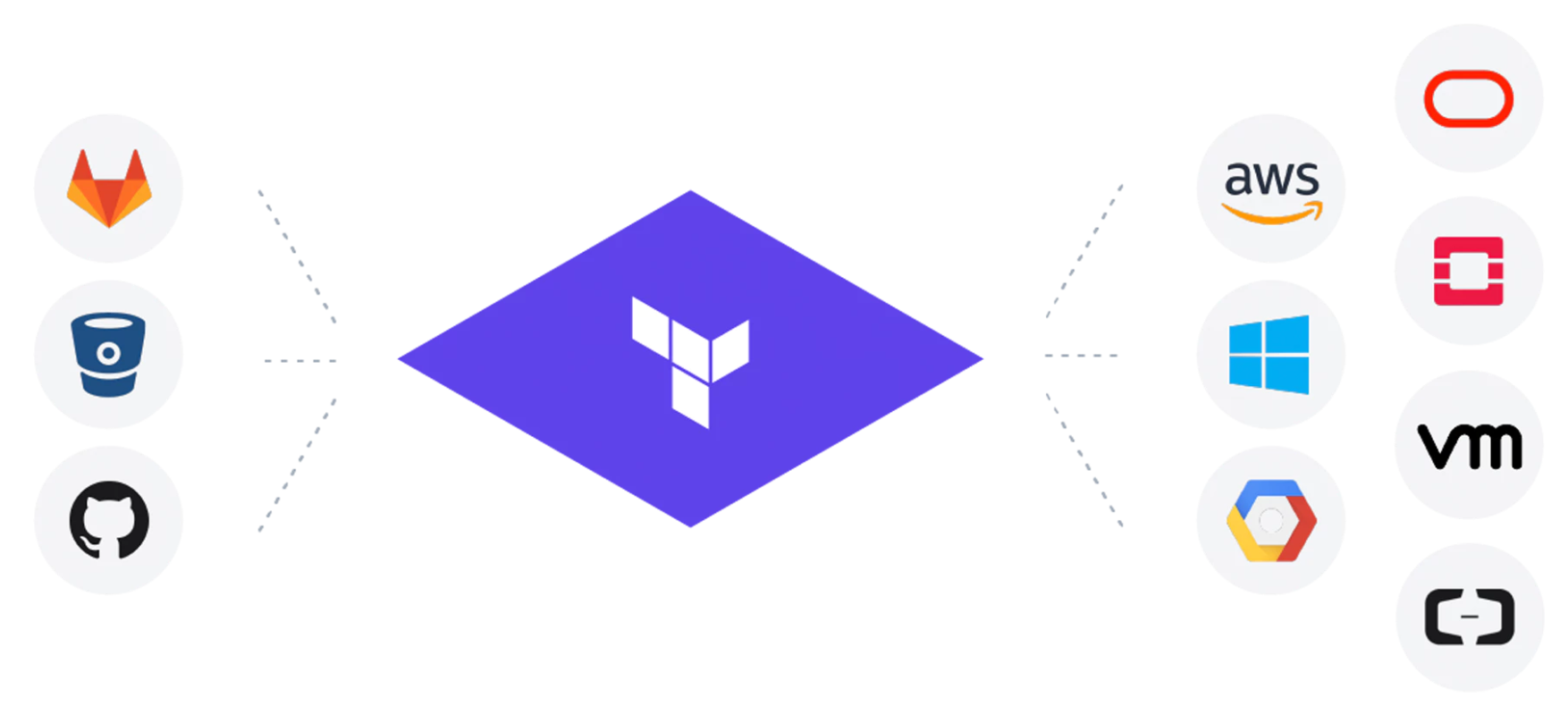
I've been working on a project over the last couple of weeks that has enabled me to sharpen my Terraform skills. There is nothing better than learning by doi...
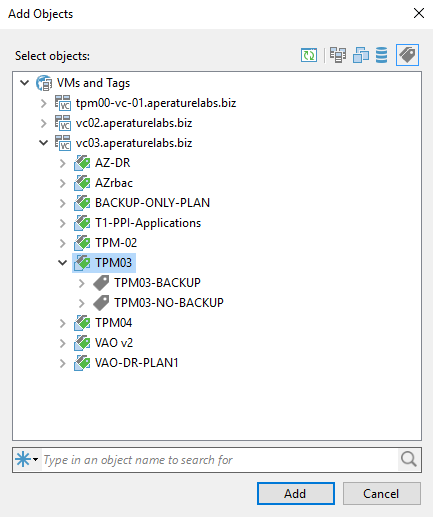
vSphere Tags are used to add attributes to VMs so that they can be used to help categorise VMs for further filtering or discovery. vSphere Tags have a number...
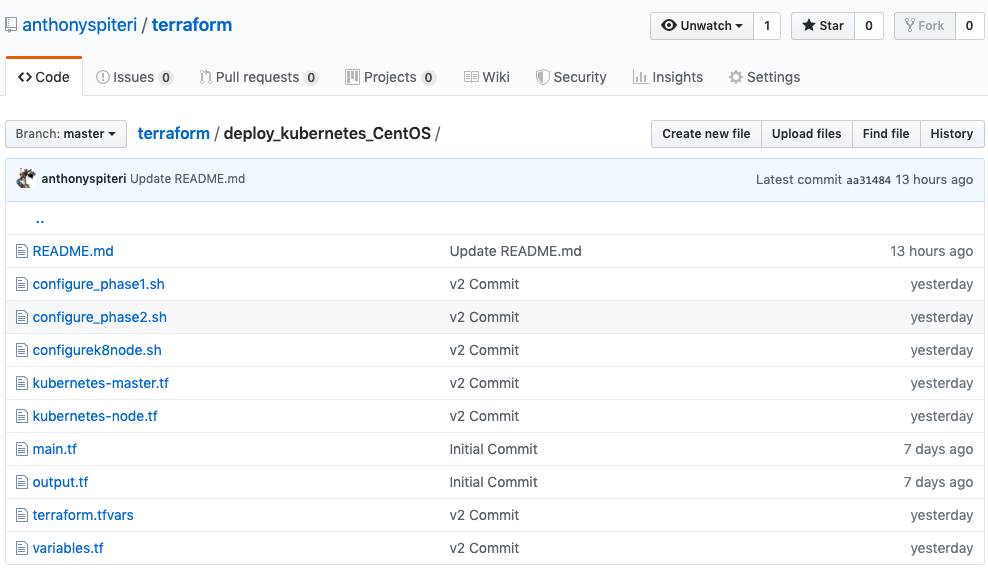
Terraform from HashiCorp has been a revelation for me since I started using it in anger last year to deploy VeeamPN into AWS . From there it has allowed me t...

Apart from the K word, there was one other enduring message that I think a lot of people took home from VMworld 2019 . That is, that Dev and Ops should be co...

That is probably the longest title i've ever had on this blog, however I wanted to highlight everything that is contained in this solution. Everything above ...
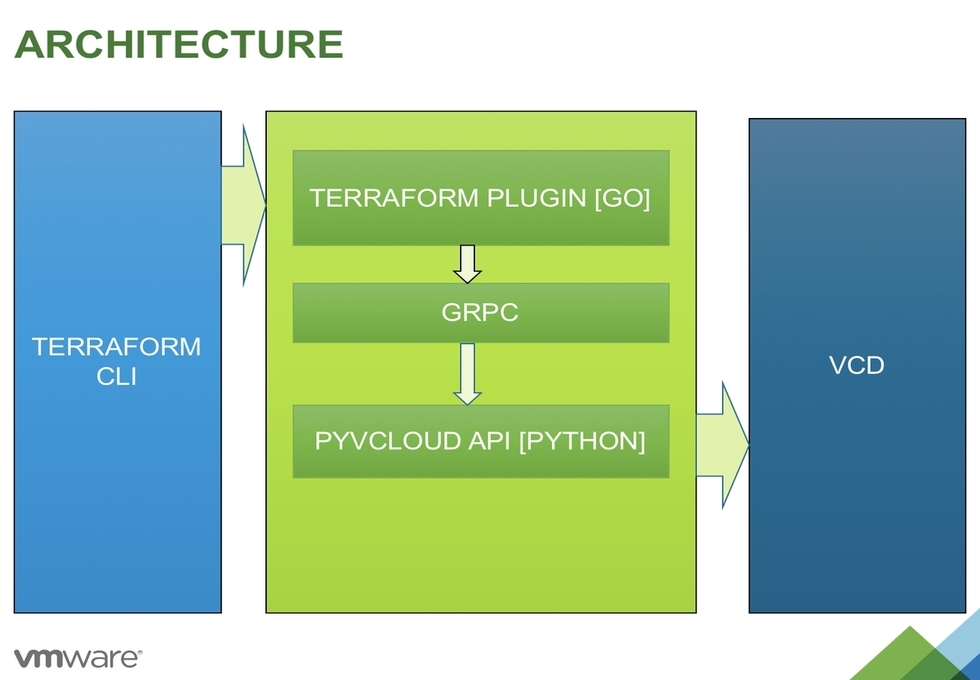
Last week I wrote an opinion piece on Infrastructure as Code vs RESTful APIs . In a nutshell, I talked about how leveraging IaC instead of trying to code aga...

While I was a little late to the game in understanding the power of Infrastructure as Code, I've spent a lot of the last twelve months working with Terraform...
Last week I was looking to add the deployment of a local CentOS virtual machine to the Deploy Veeam SDDC Toolkit project so that it included the option to de...